AWS Compute Blog
Learning AWS App Mesh
UPDATE – Oct 26 2020 – We have updated the instructions and recommended configurations for AWS App Mesh, which can be found in this GitHub repository: https://github.com/aws/aws-app-mesh-examples/tree/master/examples/apps/djapp. Please consider the below steps deprecated, but we are leaving the post live for its deeper explanation of some of the steps involved.
This post is contributed by Geremy Cohen | Solutions Architect, Strategic Accounts, AWS
At re:Invent 2018, AWS announced AWS App Mesh, a service mesh that provides application-level networking. App Mesh makes it easy for your services to communicate with each other across multiple types of compute infrastructure, including:
App Mesh standardizes how your services communicate, giving you end-to-end visibility and ensuring high availability for your applications. Service meshes like App Mesh help you run and monitor HTTP and TCP services at scale.
Using the open source Envoy proxy, App Mesh gives you access to a wide range of tools from AWS partners and the open source community. Because all traffic in and out of each service goes through the Envoy proxy, all traffic can be routed, shaped, measured, and logged. This extra level of indirection lets you build your services in any language desired without having to use a common set of communication libraries.
In this six-part series of the post, I walk you through setup and configuration of App Mesh for popular platforms and use cases, beginning with EKS. Here’s the list of the parts:
- Part 1: Introducing service meshes.
- Part 2: Prerequisites for running on EKS.
- Part 3: Creating example microservices on Amazon EKS.
- Part 4: Installing the sidecar injector and CRDs.
- Part 5: Configuring existing microservices.
- Part 6: Deploying with the canary technique.
Overview
Throughout the post series, I use diagrams to help describe what’s being built. In the following diagram:
- The circle represents the container in which your app (microservice) code runs.
- The dome alongside the circle represents the App Mesh (Envoy) proxy running as a sidecar container. When there is no dome present, no service mesh functionality is implemented for the pod.
- The arrows show communications traffic between the application container and the proxy, as well as between the proxy and other pods.

PART 1: Introducing service meshes
Life without a service mesh
Best practices call for implementing observability, analytics, and routing capabilities across your microservice infrastructure in a consistent manner.
Between any two interacting services, it’s critical to implement logging, tracing, and metrics gathering—not to mention dynamic routing and load balancing—with minimal impact to your actual application code.
Traditionally, to provide these capabilities, you would compile each service with one or more SDKs that provided this logic. This is known as the “in-process design pattern,” because this logic runs in the same process as the service code.
When you only run a small number of services, running multiple SDKs alongside your application code may not be a huge undertaking. If you can find SDKs that provide the required functionality on the platforms and languages on which you are developing, compiling it into your service code is relatively straightforward.
As your application matures, the in-process design pattern becomes increasingly complex:
- The number of engineers writing code grows, so each engineer must learn the in-process SDKs in use. They must also spend time integrating the SDKs with their own service logic and the service logic of others.
- In shops where polyglot development is prevalent, as the number of engineers grow, so may the number of coding languages in use. In these scenarios, you’ll need to make sure that your SDKs are supported on these new languages.
- The platforms that your engineering teams deploy services to may also increase and become disparate. You may have begun with Node.js containers on Kubernetes, but now, new microservices are being deployed with AWS Lambda, EC2, and other managed services. You’ll need to make sure that the SDK solution that you’ve chosen is compatible with these common platforms.
- If you’re fortunate to have platform and language support for the SDKs you’re using, inconsistencies across the various SDK languages may creep in. This is especially true when you find a gap in language or platform support and implement custom operational logic for a language or platform that is unsupported.
- Assuming you’ve accommodated for all the previous caveats, by using SDKs compiled into your service logic, you’re tightly coupling your business logic with your operations logic.
Enter the service mesh
Considering the increasing complexity as your application matures, the true value of service meshes becomes clear. With a service mesh, you can decouple your microservices’ observability, analytics, and routing logic from the underlying infrastructure and application layers.
The following diagram combines the previous two. Instead of incorporating these features at the code level (in-process), an out-of-process “sidecar proxy” container (represented by the pink dome) runs alongside your application code’s container in each pod.
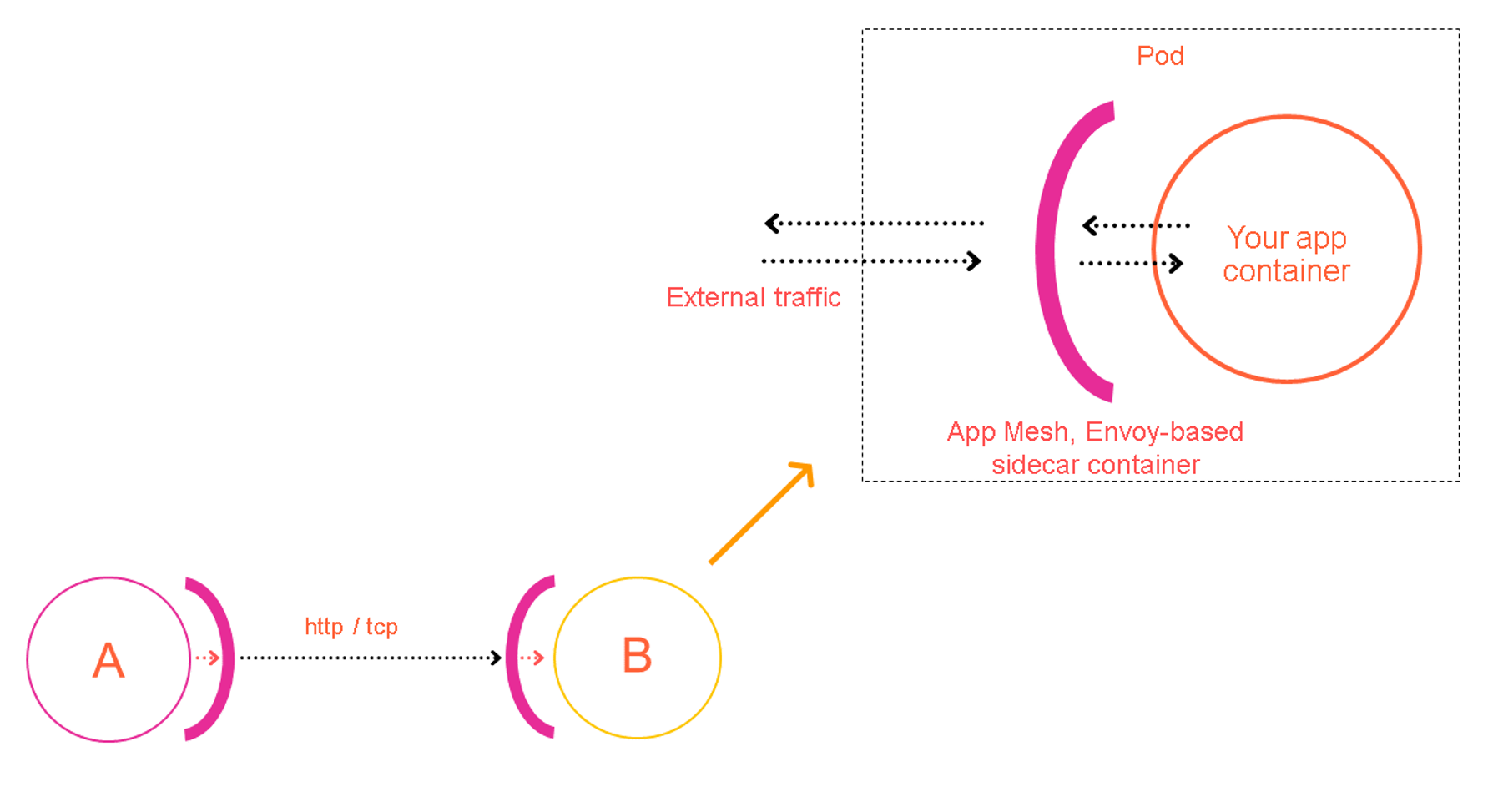
In this model, consistent and decoupled analytics, logging, tracing, and routing logic capabilities are running alongside each microservice in your infrastructure as a sidecar proxy. Each sidecar proxy is configured by a unique configuration ruleset, based on the services it’s responsible for proxying. With 100% of the communications between pods and services proxied, 100% of the traffic is now observable and actionable.
App Mesh as the service mesh
App Mesh implements this sidecar proxy via the production-proven Envoy proxy. Envoy is arguably the most popular open-source service proxy. Created at Lyft in 2016, Envoy is a stable OSS project with wide community support. It’s defined as a “Graduated Project” by the Cloud Native Computing Foundation (CNCF). Envoy is a popular proxy solution due to its lightweight C++-based design, scalable architecture, and successful deployment record.
In the following diagram, a sidecar runs alongside each container in your application to provide its proxying logic, syncing each of their unique configurations from the App Mesh control plane.

Each one of these proxies must have its own unique configuration ruleset pushed to it to operate correctly. To achieve this, DevOps teams can push their intended ruleset configuration to the App Mesh API. From there, the App Mesh control plane reliably keeps all proxy instances up-to-date with their desired configurations. App Mesh dynamically scales to hundreds of thousands of pods, tasks, EC2 instances, and Lambda functions, adjusting configuration changes accordingly as instances scale up, down, and restart.
App Mesh components
App Mesh is made up of the following components:
- Service mesh: A logical boundary for network traffic between the services that reside within it.
- Virtual nodes: A logical pointer to a Kubernetes service, or an App Mesh virtual service.
- Virtual routers: Handles traffic for one or more virtual services within your mesh.
- Routes: Associated with a virtual router, it directs traffic that matches a service name prefix to one or more virtual nodes.
- Virtual services: An abstraction of a real service that is either provided by a virtual node directly, or indirectly by means of a virtual router.
- App Mesh sidecar: The App Mesh sidecar container configures your pods to use the App Mesh service mesh traffic rules set up for your virtual routers and virtual nodes.
- App Mesh injector: Makes it easy to auto-inject the App Mesh sidecars into your pods.
- App Mesh custom resource definitions: (CRD) Provided to implement App Mesh CRUD and configuration operations directly from the kubectl CLI. Alternatively, you may use the latest version of the AWS CLI.
In the following parts, I walk you through the setup and configuration of each of these components.
Conclusion of Part 1
In this first part, I discussed in detail the advantages that service meshes provide, and the specific components that make up the App Mesh service mesh. I hope the information provided helps you to understand the benefit of all services meshes, regardless of vendor.
If you’re intrigued by what you’ve learned so far, don’t stop now!
For even more background on the components of AWS App Mesh, check out the official AWS App Mesh documentation, and when you’re ready, check out part 2 in this post where I guide you through completing the prerequisite steps to run App Mesh in your own environment.
PART 2: Setting up AWS App Mesh on Amazon EKS
In part 1 of this series, I discussed the functionality of service meshes like AWS App Mesh provided on Kubernetes and other services. In this post, I walk you through completing the prerequisites required to install and run App Mesh in your own Amazon EKS-based Kubernetes environment.
When you have the environment set up, be sure to leave it intact if you plan on experimenting in the future with App Mesh on your own (or throughout this series of posts).
Prerequisites
To run App Mesh, your environment must meet the following requirements.
- An AWS account
- The AWS CLI installed and configured
- The minimal version supported is 1.16.133. You should have a Region set via the
aws configurecommand. For this tutorial, it should work against all Regions where App Mesh and Amazon EKS are supported. Use us-west-2 if you don’t have a preference or are in doubt:
aws configure set region us-west-2
- The minimal version supported is 1.16.133. You should have a Region set via the
- The jq utility
- The utility is required by scripts executed in this series. Make sure that you have it installed on the machine from which to run the tutorial steps.
- Kubernetes and kubectl
- The minimal Kubernetes and kubectl versions supported are 1.11. You need a Kubernetes cluster deployed on Amazon Elastic Compute Cloud (Amazon EC2) or on an Amazon EKS cluster. Although the steps in this tutorial demonstrate using App Mesh on Amazon EKS, the instructions also work on upstream k8s running on Amazon EC2.
Amazon EKS makes it easy to run Kubernetes on AWS. Start by creating an EKS cluster using eksctl. For more information about how to use eksctl to spin up an EKS cluster for this exercise, see eksworkshop.com. That site has a great tutorial for getting up and running quickly with an account, as well as an EKS cluster.
Clone the tutorial repository
Clone the tutorial’s repository by issuing the following command in a directory of your choice:
git clone https://github.com/aws/aws-app-mesh-examples
Next, navigate to the repo’s /djapp examples directory:
cd aws-app-mesh-examples/examples/apps/djapp/
All the steps in this tutorial are executed out of this directory.
IAM permissions for the user and k8s worker nodes
Both k8s worker nodes and any principals (including yourself) running App Mesh AWS CLI commands must have the proper permissions to access the App Mesh service, as shown in the following code example:
To provide users with the correct permissions, add the previous policy to the user’s role or group, or create it as an inline policy.
To verify as a user that you have the correct permissions set for App Mesh, issue the following command:
aws appmesh list-meshes
If you have the proper permissions and haven’t yet created a mesh, you should get back an empty response like the following. If you did have a mesh created, you get a slightly more verbose response.
{
"meshes": []
}
If you do not have the proper permissions, you’ll see a response similar to the following:
An error occurred (AccessDeniedException) when calling the ListMeshes operation: User: arn:aws:iam::123abc:user/foo is not authorized to perform: appmesh:ListMeshes on resource: *
As a user, these permissions (or even the Administrator Access role) enable you to complete this tutorial, but it’s critical to implement least-privileged access for production or internet-facing deployments.
Adding the permissions for EKS worker nodes
If you’re using an Amazon EKS-based cluster to follow this tutorial (suggested), you can easily add the previous permissions to your k8s worker nodes with the following steps.
First, get the role under which your k8s workers are running:
INSTANCE_PROFILE_NAME=$(aws iam list-instance-profiles | jq -r '.InstanceProfiles[].InstanceProfileName' | grep nodegroup)
ROLE_NAME=$(aws iam get-instance-profile --instance-profile-name $INSTANCE_PROFILE_NAME | jq -r '.InstanceProfile.Roles[] | .RoleName')
echo $ROLE_NAME
Upon running that command, the $ROLE_NAME environment variable should be output similar to:
eksctl-blog-nodegroup-ng-1234-NodeInstanceRole-abc123
Copy and paste the following code to add the permissions as an inline policy to your worker node instances:
aws iam put-role-policy --role-name $ROLE_NAME --policy-name AppMesh-Policy-For-Worker --policy-document file://k8s-appmesh-worker-policy.json
To verify that the policy was attached to the role, run the following command:
aws iam get-role-policy --role-name $ROLE_NAME --policy-name AppMesh-Policy-For-Worker
To test that your worker nodes are able to use these permissions correctly, run the following job from the project’s directory.
NOTE: The following YAML is configured for the us-west-2 Region. If you are running your cluster and App Mesh out of a different Region, modify the –region value found in the command attribute (not in the image attribute) in the YAML before proceeding, as shown below:
command: ["aws","appmesh","list-meshes","—region","us-west-2"]
Execute the job by running the following command:
kubectl apply -f awscli.yaml
Make sure that the job is completed by issuing the command:
kubectl get jobs
You should see that the desired and successful values are both one:
NAME DESIRED SUCCESSFUL AGE
awscli 1 1 1m
Inspect the output of the job:
kubectl logs jobs/awscli
Similar to the list-meshes call, the output of this command shows whether your nodes can make App Mesh API calls successfully.
This output shows that the workers have proper access:
{
"meshes": []
}
While this output shows that they don’t:
An error occurred (AccessDeniedException) when calling the ListMeshes operation: User: arn:aws:iam::123abc:user/foo is not authorized to perform: appmesh:ListMeshes on resource: *
If you have to troubleshoot further, you must first delete the job before you run it again to test it:
kubectl delete jobs/awscli
After you’ve verified that you have the proper permissions set, you are ready to move forward and understand more about the demo application you’re going to build on top of App Mesh.
Cleaning up
When you’re done experimenting and want to delete all the resources created during this series, run the cleanup script via the following command line:
./cleanup.sh
This script does not delete any nodes in your k8s cluster. It only deletes the DJ App and App Mesh components created throughout this series of posts.
Make sure to leave the cluster intact if you plan on experimenting in the future with App Mesh on your own or throughout this series of posts.
Conclusion of Part 2
In this second part of the series, I walked you through the prerequisites required to install and run App Mesh in an Amazon EKS-based Kubernetes environment. In part 3 , I show you how to create a simple microservice that can be implemented on an App Mesh service mesh.
PART 3: Creating example microservices on Amazon EKS
In part 2 of this series, I walked you through completing the setup steps needed to configure your environment to run AWS App Mesh. In this post, I walk you through creating three Amazon EKS-based microservices. These microservices work together to form an app called DJ App, which you use later to demonstrate App Mesh functionality.
Prerequisites
Make sure that you’ve completed parts 1 and 2 of this series before running through the steps in this post.
Overview of DJ App
I’ll now walk you through creating an example app on App Mesh called DJ App, which is used for a cloud-based music service. This application is composed of the following three microservices:
- dj
- metal-v1
- jazz-v1
The dj service makes requests to either the jazz or metal backends for artist lists. If the dj service requests from the jazz backend, then musical artists such as Miles Davis or Astrud Gilberto are returned. Requests made to the metal backend return artists such as Judas Priest or Megadeth.
Today, the dj service is hardwired to make requests to the metal-v1 service for metal requests and to the jazz-v1 service for jazz requests. Each time there is a new metal or jazz release, a new version of dj must also be rolled out to point to its new upstream endpoints. Although it works for now, it’s not an optimal configuration to maintain for the long term.
App Mesh can be used to simplify this architecture. By virtualizing the metal and jazz service via kubectl or the AWS CLI, routing changes can be made dynamically to the endpoints and versions of your choosing. That minimizes the need for the complete re-deployment of DJ App each time there is a new metal or jazz service release.
Create the initial architecture
To begin, I’ll walk you through creating the initial application architecture. As the following diagram depicts, in the initial architecture, there are three k8s services:
- The dj service, which serves as the DJ App entrypoint
- The metal-v1 service backend
- The jazz-v1 service backend
As depicted by the arrows, the dj service will make requests to either the metal-v1, or jazz-v1 backends.

First, deploy the k8s components that make up this initial architecture. To keep things organized, create a namespace for the app called prod, and deploy all of the DJ App components into that namespace. To create the prod namespace, issue the following command:
kubectl apply -f 1_create_the_initial_architecture/1_prod_ns.yaml
The output should be similar to the following:
namespace/prod created
Now that you’ve created the prod namespace, deploy the DJ App (the dj, metal, and jazz microservices) into it. Create the DJ App deployment in the prod namespace by issuing the following command:
kubectl apply -nprod -f 1_create_the_initial_architecture/1_initial_architecture_deployment.yaml
The output should be similar to:
deployment.apps "dj" created
deployment.apps "metal-v1" created
deployment.apps "jazz-v1" created
Create the services that front these deployments by issuing the following command:
kubectl apply -nprod -f 1_create_the_initial_architecture/1_initial_architecture_services.yaml
The output should be similar to:
service "dj" created
service "metal-v1" created
service "jazz-v1" created
Now, verify that everything has been set up correctly by getting all resources from the prod namespace. Issue this command:
kubectl get all -nprod
The output should display the dj, jazz, and metal pods, and the services, deployments, and replica sets, similar to the following:
NAME READY STATUS RESTARTS AGE
pod/dj-5b445fbdf4-qf8sv 1/1 Running 0 1m
pod/jazz-v1-644856f4b4-mshnr 1/1 Running 0 1m
pod/metal-v1-84bffcc887-97qzw 1/1 Running 0 1m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/dj ClusterIP 10.100.247.180 <none> 9080/TCP 15s
service/jazz-v1 ClusterIP 10.100.157.174 <none> 9080/TCP 15s
service/metal-v1 ClusterIP 10.100.187.186 <none> 9080/TCP 15s
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/dj 1 1 1 1 1m
deployment.apps/jazz-v1 1 1 1 1 1m
deployment.apps/metal-v1 1 1 1 1 1m
NAME DESIRED CURRENT READY AGE
replicaset.apps/dj-5b445fbdf4 1 1 1 1m
replicaset.apps/jazz-v1-644856f4b4 1 1 1 1m
replicaset.apps/metal-v1-84bffcc887 1 1 1 1m
When you’ve verified that all resources have been created correctly in the prod namespace, test out this initial version of DJ App. To do that, exec into the DJ pod, and issue a curl request out to the jazz-v1 and metal-v1 backends. Get the name of the DJ pod by listing all the pods with the dj app selector:
kubectl get pods -nprod -l app=dj
The output should be similar to:
NAME READY STATUS RESTARTS AGE
dj-5b445fbdf4-8xkwp 1/1 Running 0 32s
Next, exec into the DJ pod:
kubectl exec -nprod -it <your-dj-pod-name> bash
The output should be similar to:
root@dj-5b445fbdf4-8xkwp:/usr/src/app#
Now that you have a root prompt into the DJ pod, issue a curl request to the jazz-v1 backend service:
curl jazz-v1.prod.svc.cluster.local:9080;echo
The output should be similar to:
["Astrud Gilberto","Miles Davis"]
Try it again, but this time issue the command to the metal-v1.prod.svc.cluster.local backend on port 9080:
curl metal-v1.prod.svc.cluster.local:9080;echo
You should get a list of heavy metal bands:
["Megadeth","Judas Priest"]
When you’re done exploring this vast world of music, press CTRL-D, or type exit to exit the container’s shell:
root@dj-779566bbf6-cqpxt:/usr/src/app# exit
command terminated with exit code 1
$
Congratulations on deploying the initial DJ App architecture!
Cleaning up
When you’re done experimenting and want to delete all the resources created during this series, run the cleanup script via the following command line:
./cleanup.sh
This script does not delete any nodes in your k8s cluster. It only deletes the DJ app and App Mesh components created throughout this series of posts.
Make sure to leave the cluster intact if you plan on experimenting in the future with App Mesh on your own or throughout this series of posts.
Conclusion of Part 3
In this third part of the series, I demonstrated how to create three simple Kubernetes-based microservices, which working together, form an app called DJ App. This app is later used to demonstrate App Mesh functionality.
In part 4, I show you how to install the App Mesh sidecar injector and CRDs, which make defining and configuring App Mesh components easy.
PART 4: Installing the sidecar injector and CRDs
In part 3 of this series, I walked you through setting up a basic microservices-based application called DJ App on Kubernetes with Amazon EKS. In this post, I demonstrate how to set up and configure the AWS App Mesh sidecar injector and custom resource definitions (CRDs). As you will see later, the sidecar injector and CRD components make defining and configuring DJ App’s service mesh more convenient.
Prerequisites
Make sure that you’ve completed parts 1–3 of this series before running through the steps in this post.
Installing the App Mesh sidecar
As decoupled logic, an App Mesh sidecar container must run alongside each pod in the DJ App deployment. This can be set up in few different ways:
- Before installing the deployment, you could modify the DJ App deployment’s container specs to include App Mesh sidecar containers. When the app is deployed, it would run the sidecar.
- After installing the deployment, you could patch the deployment to include the sidecar container specs. Upon applying this patch, the old pods are torn down, and the new pods come up with the sidecar.
- You can implement the App Mesh injector controller, which watches for new pods to be created and automatically adds the sidecar data to the pods as they are deployed.
For this tutorial, I walk you through the App Mesh injector controller option, as it enables subsequent pod deployments to automatically come up with the App Mesh sidecar. This is not only quicker in the long run, but it also reduces the chances of typos that manual editing may introduce.
Creating the injector controller
To create the injector controller, run a script that creates a namespace, generates certificates, and then installs the injector deployment.
From the base repository directory, change to the injector directory:
cd 2_create_injector
Next, run the create.sh script:
./create.sh
The output should look similar to the following:
namespace/appmesh-inject created
creating certs in tmpdir /var/folders/02/qfw6pbm501xbw4scnk20w80h0_xvht/T/tmp.LFO95khQ
Generating RSA private key, 2048 bit long modulus
.........+++
..............................+++
e is 65537 (0x10001)
certificatesigningrequest.certificates.k8s.io/aws-app-mesh-inject.appmesh-inject created
NAME AGE REQUESTOR CONDITION
aws-app-mesh-inject.appmesh-inject 0s kubernetes-admin Pending
certificatesigningrequest.certificates.k8s.io/aws-app-mesh-inject.appmesh-inject approved
secret/aws-app-mesh-inject created
processing templates
Created injector manifest at:/2_create_injector/inject.yaml
serviceaccount/aws-app-mesh-inject-sa created
clusterrole.rbac.authorization.k8s.io/aws-app-mesh-inject-cr unchanged
clusterrolebinding.rbac.authorization.k8s.io/aws-app-mesh-inject-binding configured
service/aws-app-mesh-inject created
deployment.apps/aws-app-mesh-inject created
mutatingwebhookconfiguration.admissionregistration.k8s.io/aws-app-mesh-inject unchanged
Waiting for pods to come up...
App Inject Pods and Services After Install:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
aws-app-mesh-inject ClusterIP 10.100.165.254 <none> 443/TCP 16s
NAME READY STATUS RESTARTS AGE
aws-app-mesh-inject-5d84d8c96f-gc6bl 1/1 Running 0 16s
If you’re seeing this output, the injector controller has been installed correctly. By default, the injector doesn’t act on any pods—you must give it the criteria on what to act on. For the purpose of this tutorial, you’ll next configure it to inject the App Mesh sidecar into any new pods created in the prod namespace.
Return to the repo’s base directory:
cd ..
Run the following command to label the prod namespace:
kubectl label namespace prod appmesh.k8s.aws/sidecarInjectorWebhook=enabled
The output should be similar to the following:
namespace/prod labeled
Next, verify that the injector controller is running:
kubectl get pods -nappmesh-inject
You should see output similar to the following:
NAME READY STATUS RESTARTS AGE
aws-app-mesh-inject-78c59cc699-9jrb4 1/1 Running 0 1h
With the injector portion of the setup complete, I’ll now show you how to create the App Mesh components.
Choosing a way to create the App Mesh components
There are two ways to create the components of the App Mesh service mesh:
- With the AWS Command Line Interface (AWS CLI).
- With kubectl via CRDs.
For this tutorial, I show you how to use kubectl to define the App Mesh components. To do this, add the CRDs and the App Mesh controller logic that syncs your Kubernetes cluster’s CRD state with the AWS Cloud App Mesh control plane.
Adding the CRDs and App Mesh controller
To add the CRDs, run the following commands from the repository base directory:
kubectl apply -f 3_add_crds/mesh-definition.yaml
kubectl apply -f 3_add_crds/virtual-node-definition.yaml
kubectl apply -f 3_add_crds/virtual-service-definition.yaml
The output should be similar to the following:
customresourcedefinition.apiextensions.k8s.io/meshes.appmesh.k8s.aws created
customresourcedefinition.apiextensions.k8s.io/virtualnodes.appmesh.k8s.aws created
customresourcedefinition.apiextensions.k8s.io/virtualservices.appmesh.k8s.aws created
Next, add the controller by executing the following command:
kubectl apply -f 3_add_crds/controller-deployment.yaml
The output should be similar to the following:
namespace/appmesh-system created
deployment.apps/app-mesh-controller created
serviceaccount/app-mesh-sa created
clusterrole.rbac.authorization.k8s.io/app-mesh-controller created
clusterrolebinding.rbac.authorization.k8s.io/app-mesh-controller-binding created
Run the following command to verify that the App Mesh controller is running:
kubectl get pods -nappmesh-system
You should see output similar to the following:
NAME READY STATUS RESTARTS AGE
app-mesh-controller-85f9d4b48f-j9vz4 1/1 Running 0 7m
NOTE: The CRD and injector are AWS-supported open source projects. If you plan to deploy the CRD or injector for production projects, always build them from the latest AWS GitHub repos and deploy them from your own container registry. That way, you stay up-to-date on the latest features and bug fixes.
Cleaning up
When you’re done experimenting and want to delete all the resources created during this series, run the cleanup script via the following command line:
./cleanup.sh
This script does not delete any nodes in your k8s cluster. It only deletes the DJ app and App Mesh components created throughout this series of posts.
Make sure to leave the cluster intact if you plan on experimenting in the future with App Mesh on your own or throughout this series of posts.
Conclusion of Part 4
In this fourth part of the series, I walked you through setting up the App Mesh sidecar injector and CRD components. In part 5, I show you how to define the App Mesh components required to run DJ App on a service mesh.
PART 5: Configuring existing microservices
In part 4 of this series, I demonstrated how to set up the AWS App Mesh Sidecar Injector and CRDs. In this post, I’ll show how to configure the DJ App microservices to run on top of App Mesh by creating the required App Mesh components.
Prerequisites
Make sure that you’ve completed parts 1–4 of this series before running through the steps in this post.
DJ App revisited
As shown in the following diagram, the dj service is hardwired to make requests to either the metal-v1 or jazz-v1 backends.
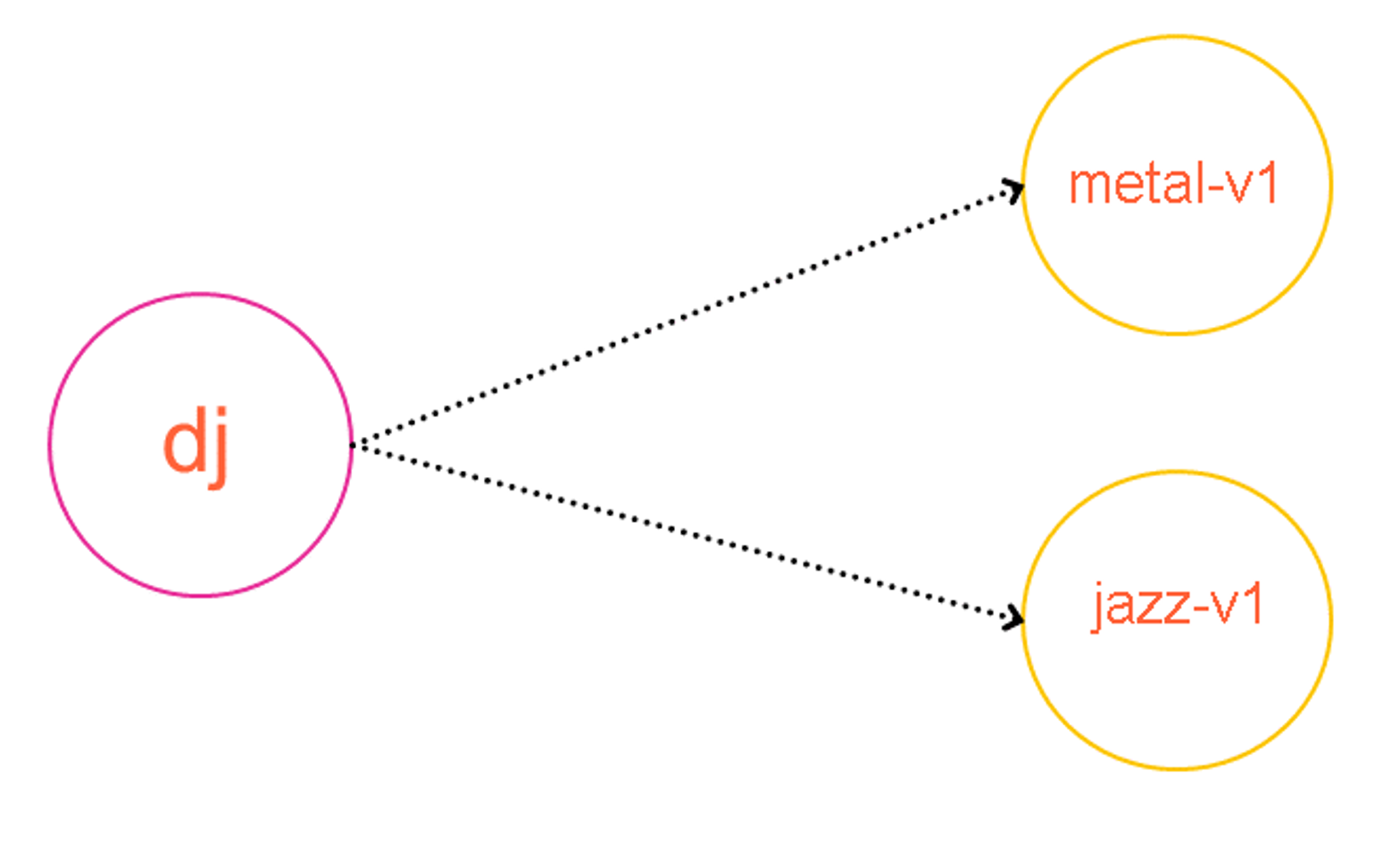 The service mesh-enabled version functionally does exactly what the current version does. The only difference is that you use App Mesh to create two new virtual services called metal and jazz. The dj service now makes a request to these metal or jazz virtual services, which route to their metal-v1 and jazz-v1 counterparts accordingly, based on the virtual services’ routing rules. The following diagram depicts this process.
The service mesh-enabled version functionally does exactly what the current version does. The only difference is that you use App Mesh to create two new virtual services called metal and jazz. The dj service now makes a request to these metal or jazz virtual services, which route to their metal-v1 and jazz-v1 counterparts accordingly, based on the virtual services’ routing rules. The following diagram depicts this process.
By virtualizing the metal and jazz services, you can dynamically configure routing rules to the versioned backends of your choosing. That eliminates the need to re-deploy the entire DJ App each time there’s a new metal or jazz service version release.

Now that you have a better idea of what you’re building, I’ll show you how to create the mesh.
Creating the mesh
The mesh component, which serves as the App Mesh foundation, must be created first. Call the mesh dj-app, and define it in the prod namespace by executing the following command from the repository’s base directory:
kubectl create -f 4_create_initial_mesh_components/mesh.yaml
You should see output similar to the following:
mesh.appmesh.k8s.aws/dj-app created
Because an App Mesh mesh is a custom resource, kubectl can be used to view it using the get command. Run the following command:
kubectl get meshes -nprod
This yields the following:
NAME AGE
dj-app 1h
As is the case for any of the custom resources you interact with in this tutorial, you can also view App Mesh resources using the AWS CLI:
aws appmesh list-meshes
aws appmesh describe-mesh --mesh-name dj-app
NOTE: If you do not see dj-app returned from the previous list-meshes command, then your user account (as well as your worker nodes) may not have the correct IAM permissions to access App Mesh resources. Verify that you and your worker nodes have the correct permissions per part 2 of this series.
Creating the virtual nodes and virtual services
With the foundational mesh component created, continue onward to define the App Mesh virtual node and virtual service components. All physical Kubernetes services that interact with each other in App Mesh must first be defined as virtual node objects.
Abstracting out services as virtual nodes helps App Mesh build rulesets around inter-service communication. In addition, as you define virtual service objects, virtual nodes may be referenced as inputs and target endpoints for those virtual services. Because of this, it makes sense to define the virtual nodes first.
Based on the first App Mesh-enabled architecture, the physical service dj makes requests to two new virtual services—metal and jazz. These services route requests respectively to the physical services metal-v1 and jazz-v1, as shown in the following diagram.
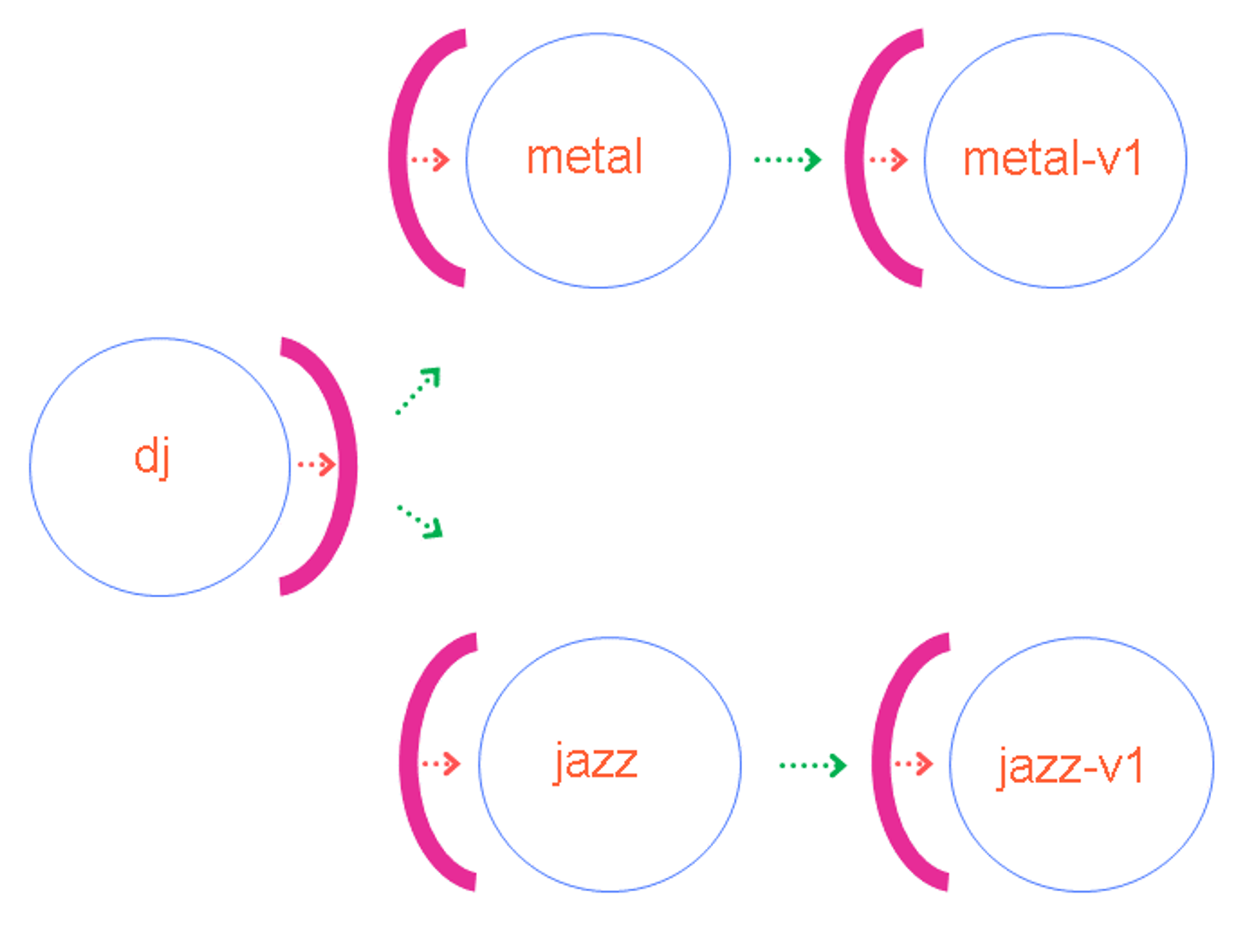
Because there are three physical services involved in this configuration, you’ll need to define three virtual nodes. To do that, enter the following:
kubectl create -nprod -f 4_create_initial_mesh_components/nodes_representing_physical_services.yaml
The output should be similar to:
virtualnode.appmesh.k8s.aws/dj created
virtualnode.appmesh.k8s.aws/jazz-v1 created
virtualnode.appmesh.k8s.aws/metal-v1 created
If you open up the YAML in your favorite editor, you may notice a few things about these virtual nodes.
They’re both similar, but for the purposes of this tutorial, examine just the metal-v1.prod.svc.cluster.local VirtualNode:
According to this YAML, this virtual node points to a service (spec.serviceDiscovery.dns.hostName: metal-v1.prod.svc.cluster.local) that listens on a given port for requests (spec.listeners.portMapping.port: 9080).
You may notice that jazz-v1 and metal-v1 are similar to the dj virtual node, with one key difference; the dj virtual node contains a backend attribute:
The backend attribute specifies that dj is allowed to make requests to the jazz and metal virtual services only.
At this point, you’ve created three virtual nodes:
kubectl get virtualnodes -nprod
NAME AGE
dj 6m
jazz-v1 6m
metal-v1 6m
The last step is to create the two App Mesh virtual services that intercept and route requests made to jazz and metal. To do this, run the following command:
kubectl apply -nprod -f 4_create_initial_mesh_components/virtual-services.yaml
The output should be similar to:
virtualservice.appmesh.k8s.aws/jazz.prod.svc.cluster.local created
virtualservice.appmesh.k8s.aws/metal.prod.svc.cluster.local created
If you inspect the YAML, you may notice that it created two virtual service resources. Requests made to jazz.prod.svc.cluster.local are intercepted by App Mesh and routed to the virtual node jazz-v1.
Similarly, requests made to metal.prod.svc.cluster.local are routed to the virtual node metal-v1:
NOTE: Remember to use fully qualified DNS names for the virtual service’s metadata.name field to prevent the chance of name collisions when using App Mesh cross-cluster.
With these virtual services defined, to access them by name, clients (in this case, the dj container) first perform a DNS lookup to jazz.prod.svc.cluster.local or metal.prod.svc.cluster.local before making the HTTP request.
If the dj container (or any other client) cannot resolve that name to an IP, the subsequent HTTP request fails with a name lookup error.
The existing physical services (jazz-v1, metal-v1, dj) are defined as physical Kubernetes services, and therefore have resolvable names:
kubectl get svc -nprod
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dj ClusterIP 10.100.247.180 <none> 9080/TCP 16h
jazz-v1 ClusterIP 10.100.157.174 <none> 9080/TCP 16h
metal-v1 ClusterIP 10.100.187.186 <none> 9080/TCP 16h
However, the new jazz and metal virtual services we just created don’t (yet) have resolvable names.
To provide the jazz and metal virtual services with resolvable IP addresses and hostnames, define them as Kubernetes services that do not map to any deployments or pods. Do this by creating them as k8s services without defining selectors for them. Because App Mesh is intercepting and routing requests made for them, they don’t have to map to any pods or deployments on the k8s-side.
To register the placeholder names and IP addresses for these virtual services, run the following command:
kubectl create -nprod -f 4_create_initial_mesh_components/metal_and_jazz_placeholder_services.yaml
The output should be similar to:
service/jazz created
service/metal created
You can now use kubectl to get the registered metal and jazz virtual services:
kubectl get -nprod virtualservices
NAME AGE
jazz.prod.svc.cluster.local 10m
metal.prod.svc.cluster.local 10m
You can also get the virtual service placeholder IP addresses and physical service IP addresses:
kubectl get svc -nprod
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dj ClusterIP 10.100.247.180 <none> 9080/TCP 17h
jazz ClusterIP 10.100.220.118 <none> 9080/TCP 27s
jazz-v1 ClusterIP 10.100.157.174 <none> 9080/TCP 17h
metal ClusterIP 10.100.122.192 <none> 9080/TCP 27s
metal-v1 ClusterIP 10.100.187.186 <none> 9080/TCP 17h
As such, when name lookup requests are made to your virtual services alongside their physical service counterparts, they resolve.
Currently, if you describe any of the pods running in the prod namespace, they are running with just one container (the same one with which you initially deployed it):
kubectl get pods -nprod
NAME READY STATUS RESTARTS AGE
dj-5b445fbdf4-qf8sv 1/1 Running 0 3h
jazz-v1-644856f4b4-mshnr 1/1 Running 0 3h
metal-v1-84bffcc887-97qzw 1/1 Running 0 3h
kubectl describe pods/dj-5b445fbdf4-qf8sv -nprod
The injector controller installed earlier watches for new pods to be created and ensures that any new pods created in the prod namespace are injected with the App Mesh sidecar. Because the dj pods were already running before the injector was created, you’ll now force them to be re-created, this time with the sidecars auto-injected into them.
In production, there are more graceful ways to do this. For the purpose of this tutorial, an easy way to have the deployment re-create the pods in an innocuous fashion is to patch a simple date annotation into the deployment.
To do that with your current deployment, first get all the prod namespace pod names:
kubectl get pods -nprod
The output is the pod names:
NAME READY STATUS RESTARTS AGE
dj-5b445fbdf4-qf8sv 1/1 Running 0 3h
jazz-v1-644856f4b4-mshnr 1/1 Running 0 3h
metal-v1-84bffcc887-97qzw 1/1 Running 0 3h
Under the READY column, you see 1/1, which indicates that one container is running for each pod.
Next, run the following commands to add a date label to each dj, jazz-v1, and metal-1 deployment, forcing the pods to be re-created:
kubectl patch deployment dj -nprod -p "{\"spec\":{\"template\":{\"metadata\":{\"labels\":{\"date\":\"`date +'%s'`\"}}}}}"
kubectl patch deployment metal-v1 -nprod -p "{\"spec\":{\"template\":{\"metadata\":{\"labels\":{\"date\":\"`date +'%s'`\"}}}}}"
kubectl patch deployment jazz-v1 -nprod -p "{\"spec\":{\"template\":{\"metadata\":{\"labels\":{\"date\":\"`date +'%s'`\"}}}}}"
Again, get the pods:
kubectl get pods -nprod
Under READY, you see 2/2, which indicates that two containers for each pod are running:
NAME READY STATUS RESTARTS AGE
dj-6cfb85cdd9-z5hsp 2/2 Running 0 10m
jazz-v1-79d67b4fd6-hdrj9 2/2 Running 0 16s
metal-v1-769b58d9dc-7q92q 2/2 Running 0 18s
NOTE: If you don’t see this exact output, wait about 10 seconds (your redeployment is underway), and re-run the command.
Now describe the new dj pod to get more detail:
Both the original container and the auto-injected sidecar are running for any new pods created in the prod namespace.
Testing the App Mesh architecture
To test if the new architecture is working as expected, exec into the dj container. Get the name of your dj pod by listing all pods with the dj selector:
kubectl get pods -nprod -lapp=dj
The output should be similar to the following:
NAME READY STATUS RESTARTS AGE
dj-5b445fbdf4-8xkwp 1/1 Running 0 32s
Next, exec into the dj pod returned from the last step:
kubectl exec -nprod -it <your-dj-pod-name> bash
The output should be similar to:
root@dj-5b445fbdf4-8xkwp:/usr/src/app#
Now that you have a root prompt into the dj pod, make a curl request to the virtual service jazz on port 9080. Your request simulates what would happen if code running in the same pod made a request to the jazz backend:
curl jazz.prod.svc.cluster.local:9080;echo
The output should be similar to the following:
["Astrud Gilberto","Miles Davis"]
Try it again, but issue the command to the virtual metal service:
curl metal.prod.svc.cluster.local:9080;echo
You should get a list of heavy metal bands:
["Megadeth","Judas Priest"]
When you’re done exploring this vast, service-mesh-enabled world of music, press CTRL-D, or type exit to exit the container’s shell:
root@dj-779566bbf6-cqpxt:/usr/src/app# exit
command terminated with exit code 1
$
Cleaning up
When you’re done experimenting and want to delete all the resources created during this series, run the cleanup script via the following command line:
./cleanup.sh
This script does not delete any nodes in your k8s cluster. It only deletes the DJ app and App Mesh components created throughout this series of posts.
Make sure to leave the cluster intact if you plan on experimenting in the future with App Mesh on your own or throughout this series of posts.
Conclusion of Part 5
In this fifth part of the series, you learned how to enable existing microservices to run on App Mesh. In part 6, I demonstrate the true power of App Mesh by walking you through adding new versions of the metal and jazz services and demonstrating how to route between them.
PART 6: Deploying with the canary technique
In part 5 of this series, I demonstrated how to configure an existing microservices-based application (DJ App) to run on AWS App Mesh. In this post, I demonstrate how App Mesh can be used to deploy new versions of Amazon EKS-based microservices using the canary technique.
Prerequisites
Make sure that you’ve completed parts 1–5 of this series before running through the steps in this post.
Canary testing with v2
A canary release is a method of slowly exposing a new version of software. The theory is that by serving the new version of the software to a small percentage of requests, any problems only affect the small percentage of users before they’re discovered and rolled back.
So now, back to the DJ App scenario. Version 2 of the metal and jazz services is out, and they now include the city that each artist is from in the response. You’ll now release v2 versions of the metal and jazz services in a canary fashion using App Mesh. When you complete this process, requests to the metal and jazz services are distributed in a weighted fashion to both the v1 and v2 versions.
The following diagram shows the final (v2) seven-microservices-based application, running on an App Mesh service mesh.

To begin, roll out the v2 deployments, services, and virtual nodes with a single YAML file:
kubectl apply -nprod -f 5_canary/jazz_v2.yaml
The output should be similar to the following:
deployment.apps/jazz-v2 created
service/jazz-v2 created
virtualnode.appmesh.k8s.aws/jazz-v2 created
Next, update the jazz virtual service by modifying the route to spread traffic 50/50 across the two versions. Look at it now, and see that the current route points 100% to jazz-v1:
kubectl describe virtualservice jazz -nprod
Name: jazz.prod.svc.cluster.local
Namespace: prod
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
Apply the updated service definition:
kubectl apply -nprod -f 5_canary/jazz_service_update.yaml
When you describe the virtual service again, you see the updated route:
kubectl describe virtualservice jazz -nprod
Name: jazz.prod.svc.cluster.local
Namespace: prod
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
To deploy metal-v2, perform the same steps. Roll out the v2 deployments, services, and virtual nodes with a single YAML file:
kubectl apply -nprod -f 5_canary/metal_v2.yaml
The output should be similar to the following:
deployment.apps/metal-v2 created
service/metal-v2 created
virtualnode.appmesh.k8s.aws/metal-v2 created
Update the metal virtual service by modifying the route to spread traffic 50/50 across the two versions:
kubectl apply -nprod -f 5_canary/metal_service_update.yaml
When you describe the virtual service again, you see the updated route:
kubectl describe virtualservice metal -nprod
Name: metal.prod.svc.cluster.local
Namespace: prod
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
Testing the v2 jazz and metal services
Now that the v2 services are deployed, it’s time to test them out. To test if it’s working as expected, exec into the DJ pod. To do that, get the name of your dj pod by listing all pods with the dj selector:
kubectl get pods -nprod -l app=dj
The output should be similar to the following:
NAME READY STATUS RESTARTS AGE
dj-5b445fbdf4-8xkwp 1/1 Running 0 32s
Next, exec into the DJ pod by running the following command:
kubectl exec -nprod -it <your dj pod name> bash
The output should be similar to the following:
root@dj-5b445fbdf4-8xkwp:/usr/src/app#
Now that you have a root prompt into the DJ pod, issue a curl request to the metal virtual service:
while [ 1 ]; do curl http://metal.prod.svc.cluster.local:9080/;echo; done
The output should loop about 50/50 between the v1 and v2 versions of the metal service, similar to:
...
["Megadeth","Judas Priest"]
["Megadeth (Los Angeles, California)","Judas Priest (West Bromwich, England)"]
["Megadeth","Judas Priest"]
["Megadeth (Los Angeles, California)","Judas Priest (West Bromwich, England)"]
...
Press CTRL-C to stop the looping.
Next, perform a similar test, but against the jazz service. Issue a curl request to the jazz virtual service from within the dj pod:
while [ 1 ]; do curl http://jazz.prod.svc.cluster.local:9080/;echo; done
The output should loop about in a 90/10 ratio between the v1 and v2 versions of the jazz service, similar to the following:
...
["Astrud Gilberto","Miles Davis"]
["Astrud Gilberto","Miles Davis"]
["Astrud Gilberto","Miles Davis"]
["Astrud Gilberto (Bahia, Brazil)","Miles Davis (Alton, Illinois)"]
["Astrud Gilberto","Miles Davis"]
...
Press CTRL-C to stop the looping, and then type exit to exit the pod’s shell.
Cleaning up
When you’re done experimenting and want to delete all the resources created during this tutorial series, run the cleanup script via the following command line:
./cleanup.sh
This script does not delete any nodes in your k8s cluster. It only deletes the DJ app and App Mesh components created throughout this series of posts.
Make sure to leave the cluster intact if you plan on experimenting in the future with App Mesh on your own.
Conclusion of Part 6
In this final part of the series, I demonstrated how App Mesh can be used to roll out new microservice versions using the canary technique. Feel free to experiment further with the cluster by adding or removing microservices, and tweaking routing rules by changing weights and targets.
Geremy is a solutions architect at AWS. He enjoys spending time with his family, BBQing, and breaking and fixing things around the house.