AWS Compute Blog
Handling billions of invocations – best practices from AWS Lambda
This post is written by Anton Aleksandrov, Principal Solution Architect, AWS Serverless and Rajesh Kumar Pandey, Principal Engineer, AWS Lambda
AWS Lambda is a highly scalable and resilient serverless compute service. With over 1.5 million monthly active customers and tens of trillions of invocations processed, scalability and reliability are two of the most important service tenets. This post provides recommendations and insights for implementing highly distributed applications based on the Lambda service team’s experience building its robust asynchronous event processing system. It dives into challenges you might face, solution techniques, and best practices for handling noisy neighbors.
Overview
Developers building serverless applications create Lambda functions to run their code in the cloud. After uploading the code, the functions are invoked using synchronous or asynchronous mode.
Synchronous invocations are commonly used for interactive applications that expect immediate responses, such as web APIs. The Lambda service receives the invocation request, invokes the function handler, waits for the handler response, and returns it in response to the original request. With synchronous invocations, the client waits for the function handler to return, and is responsible for managing timeouts and retries for failed invocations.

Figure 1. Synchronous invocation sequence diagram
Asynchronous invocations enable decoupled function executions. Clients submit payloads for processing without expecting immediate responses. This is used for scenarios like asynchronous data processing or order/job submissions. The Lambda service immediately returns a confirmation for accepted invocation and proceeds to manage further handler invocation, timeouts, and retries asynchronously.
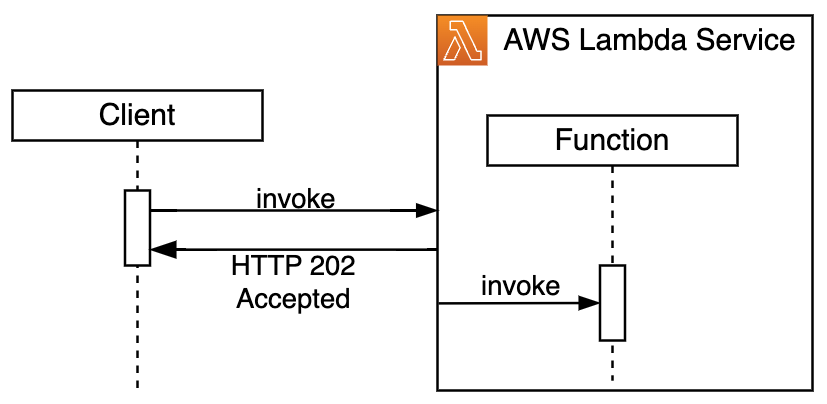
Figure 2. Asynchronous invocation sequence diagram
Asynchronous invocations under-the-hood
To accommodate asynchronous invocations, the Lambda service places requests into its internal queue and immediately returns HTTP 202 back to the client. After that, a separate internal poller component reads messages from the queue and synchronously invokes the function.

Figure 3. Asynchronous invocations workflow high-level topology
The same system also takes care of timeouts and retries in case of handler exceptions. When code execution completes, the system sends handler response to either onSuccess or onFailure destination, if configured.

Figure 4. Asynchronous invocations workflow detailed sequence diagram
Scaling highly distributed systems for billions of asynchronous requests presents unique challenges, such as managing noisy neighbors and potential traffic spikes to prevent system overload. Solutions vary by scale – what works for millions of requests may not suite billions. As workload size increases, solutions typically become more complex and costly, so right-sizing the approach is critical and should evolve with changing needs.
Simple queueing
A simple implementation of an asynchronous architecture can start with a single shared queue. This is a common approach for many asynchronous systems, particularly in early stages. It is effective when you’re not concerned about tenant isolation and when capacity planning indicates that a single queue can handle estimated incoming traffic efficiently.

Figure 5. Asynchronous workflow with a single queue
Even with this simple setup, it is critical to instrument your solution for observability to detect potential issues as soon as possible. You should monitor key metrics like queue backlog size, processing time, and errors, to indicate insufficient processing capacity early. Periods of unexpected traffic spikes and degraded performance may be a signal you have noisy neighbors impacting other tenants.
To address this, you can scale your solution horizontally. You can implement random request placement across multiple queues to spread the load. Using a serverless service like Amazon SQS allows you to easily add and remove queues on-demand. One notable benefit of this approach is its simplicity – you do not need to introduce any complex routing mechanisms; requests are evenly spread across the queues. The downside is that you still do not have tenant boundaries. As your system grows, high-volume tenants and noisy neighbors can potentially affect all queues, thus impacting all tenants.

Figure 6. Asynchronous workflow with multiple queues and random request placement
Intelligent partitioning with consistent hashing
In order to further reduce potential impact, you can partition your tenants using sticky tenant-to-partition assignment with a hashing technique such as consistent hashing. This method uses a hash function to assign each tenant to a queue on a consistent hash ring.

Figure 7. Asynchronous workflow with multiple queues and consistent hashing placement
This technique ensures individual tenants stay in their queue partitions without the risk of disturbing the whole system. It helps to solve the problem where a few noisy neighbors have the potential to overflow all queues and as such impact all other tenants.
The consistent hashing approach proved to be efficient and enabled Lambda to offer robust asynchronous invocation performance to customers. As the volume of traffic and number of customers continued to grow, the Lambda service team came up with an innovative shuffle-sharding technique to further optimize the experience, and proactively eliminate any potential noisy-neighbor issues.
Shuffle-sharding
Drawing inspiration from the “The Power of Two Random Choices” paper, the Lambda team explored the shuffle-sharding technique for its asynchronous invocations processing. Using this technique, you shuffle-shard tenants into several randomly assigned queues. Upon receiving an asynchronous invocation, you place the message in the queue with the smallest backlog to optimize load distribution. This approach helps to minimize the likelihood of assigning tenants to a busy queue.

Figure 8. Asynchronous workflow with multiple queues and shuffle-sharding placement
To illustrate the benefit of this approach, consider a scenario where you’re using а 100 queues. The following formula helps to calculate the number of unique queue shards (combinations), where n is the total number of queues and r is the shard size (the number of queues you’re assigning per tenant).

With n=100, r=2 (each tenant is assigned randomly to 2 out of 100 queues), you get 4,950 unique combinations (shards). The probability of two tenants assigned to exactly the same shard is 0.02%. In case of r=3, the number of combinations spikes to 161,700. The probability of two tenants assigned to exactly the same shard drops to 0.0006%.
The shuffle-sharding technique proved remarkably effective. By distributing tenants across shards, the approach ensures that only a very small subset of tenants could be affected by a noisy neighbor. The potential impact is also minimized since each affected tenant maintains access to unaffected queues. As your workloads grow, increasing the number of queues enhances resilience and further reduces the probability of multiple tenants being assigned to the same shard. This significantly lowers the risk of a single point of failure, making shuffle sharding a robust strategy for workload isolation and fault tolerance.
Proactive detection, automated isolation, sidelining
Many distributed services will have a cohort of tenants with legitimate spiky asynchronous invocation traffic. This can be driven by seasonal factors, such as holiday shopping, or periodical batch processing. Recognizing these as real business needs, not malicious actions, you want to improve service quality for these tenants as well, while maintaining the overall system stability. For example, you can further improve solution performance by continuously monitoring queue depth to detect traffic spikes and route traffic to dynamically allocated dedicated queues. When you use Lambda asynchronous invocations, this internal complexity is managed for you by the service, ensuring seamless consumption experience.

Figure 9. Tenant D is automatically reallocated to a dedicated queue
Resilience and failure handling
“Everything fails, all the time” is a famous quote from Amazon’s Chief Technology Officer Werner Vogels. Lambda’s distributed and resilient architecture is built to withstand potential outages of its dependencies and internal components to limit the fallout for customers. Specifically for asynchronous invocation processing, the frontend service builds a processing backlog during an outage, allowing the backend to gradually recover without losing any in-flight messages.

Figure 10. Lambda service maintains resilience during component outage
Upon recovery, the service gradually ramps up the traffic to process the accumulated backlog. During this time, automated mechanisms are in place to coordinate between system components, preventing inadvertently DDoSing itself.
To further improve the recovery ramp-up process and provide a smooth restoration of normal operations, the Lambda service uses load-shedding technique to ensure fair resource allocation during recovery. While trying to drain the backlog as fast as possible, the service ensures that no single customer ends up consuming an outsized share of the available resources. Adopting such techniques can help you to improve your mean-time-to-recovery (MTTR).
Observability for asynchronous invocations processing
When using the Lambda service for asynchronous processing, you want to monitor your invocations for situational awareness and potential slowdowns. Use metrics such as AsyncEventReceived, AsyncEventAge, and AsyncEventDropped to get insights about internal processing.
AsyncEventReceived tracks the number of async invocations the Lambda service was able to successfully queue for processing. A drop in this metric indicates that invocations are not being delivered to the Lambda service and you should check your invocation source. Potential issues include misconfigurations, invalid access permissions, or throttling. Check your invocation source configuration, logs, and the function resource policy for further analysis.
AsyncEventAge tracks how long has a message spent in the internal queue before being processed by a function. This metric increases when async invocations processing is delayed due to insufficient concurrency, execution failures, or throttles. Increase your function concurrency to process more asynchronous invocations at a time and optimize function performance for better throughput, i.e. by increasing memory allocation to add more vCPU capacity. Experiment with adjusting batch size to enable functions to process more messages at a time. Use invocation logs to identify whether the problem is caused by function code throwing exceptions. Check Throttles and Errors metrics for further analysis.
AsyncEventDropped tracks the number of messages in the internal queue that were dropped because Lambda could not process them. This can be due to throttling, exceeding number of retries, exceeding maximum message age, or function code throwing an exception. Configure OnFailure destination or a dead-letter queue to avoid losing data and save dropped messages for re-processing. Use function logs and metrics described above to investigate whether you can address the issue by increasing function concurrency or allocating more memory.
By monitoring these metrics and addressing the underlying issues, you can ensure that your Lambda functions run smoothly, with minimal event processing delays and failures. You can also enable AWS X-Ray tracing to capture Lambda service traces. The AWS::Lambda trace segment captures the breakdown of the time that Lambda service spends routing requests to internal queues, the time a message spends in a queue, and the time before a function is invoked. This is a powerful tool to get insights into Lambda’s internal processing.
Conclusion
AWS Lambda processes tens of trillions of monthly invocations across more than 1.5 million active customers, demonstrating its exceptional scalability and resilience. Gaining an understanding of the underlying mechanisms of AWS services like Lambda enables you to proactively address potential challenges in your own applications. By learning how these services handle traffic, manage resources, and recover from failures, you can incorporate similar capabilities into your own solutions. For instance, leveraging Lambda’s asynchronous invocation metrics allows you to optimize workflow performance. This knowledge empowers you to implement strategies such as automated scaling, proactive monitoring, and graceful recovery during outages.
See below resources to learn about using queues and shuffle sharding at scale at Amazon
- Avoiding insurmountable queue backlogs
- Workload isolation using shuffle-sharding in Route53
- Improve workload resiliency using shuffle sharding
- Shuffle Sharding: Massive and Magical Fault Isolation
To learn more about Serverless architectures and asynchronous Lambda invocation patterns, see Serverless Land.