AWS Compute Blog
Category: Amazon Simple Queue Service (SQS)

Choosing between messaging services for serverless applications
Messaging is an important part of serverless applications and AWS services provide queues, publish/subscribe, and event routing capabilities. This post reviews the main features of SNS, SQS, and EventBridge and how they provide different capabilities for your workloads.

Building storage-first serverless applications with HTTP APIs service integrations
Over the last year, I have been talking about “storage first” serverless patterns. With these patterns, data is stored persistently before any business logic is applied. The advantage of this pattern is increased application resiliency. By persisting the data before processing, the original data is still available, if or when errors occur. Common pattern for […]

ICYMI: Season one of Sessions with SAM
February 12, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Developers tell us they want to know how to easily build and manage their serverless applications. In 2017 AWS announced AWS Serverless Application Model (SAM) to help with just that. To help […]

Managing backend requests and frontend notifications in serverless web apps
Web and mobile applications usually interact with a backend service, often via an API. Many front-end applications pass requests for processing, wait for a result, and then display this to the user. This synchronous approach is only one way to handle messages, but modern applications have alternatives to provide a better user experience. There are […]
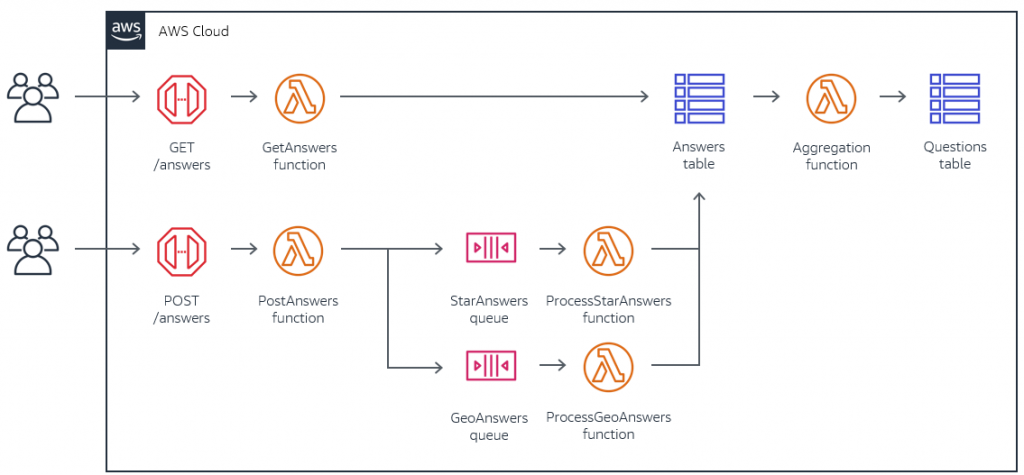
Building a location-based, scalable, serverless web app – part 3
In part 2, I cover the API configuration, geohashing algorithm, and real-time messaging architecture used in the Ask Around Me web application. These are needed for receiving and processing questions and answers, and sending results back to users in real time. In this post, I explain the backend processing architecture, how data is aggregated, and […]
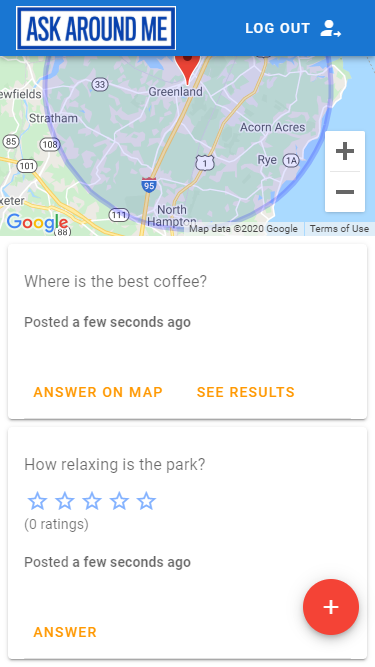
Building a location-based, scalable, serverless web app – part 1
In this post, I introduce the Ask Around Me example web application. Learn to build a serverless realtime, Vue.js web app in part 1 of this series.

Building scalable serverless applications with Amazon S3 and AWS Lambda
S3 and Lambda are two highly scalable AWS services that can be powerful when combined in serverless applications. In this post, I summarize many of the patterns shown across this series.

Creating a scalable serverless import process for Amazon DynamoDB
Amazon DynamoDB is a web-scale NoSQL database designed to provide low latency access to data. It’s well suited to many serverless applications as a primary data store, and fits into many common enterprise architectures. In this post, I show how you can import large amounts of data to DynamoDB using a serverless approach. This uses […]

Translating documents at enterprise scale with serverless
Developing a scalable translation solution for thousands of documents can be challenging using traditional, server-based architecture. Using a serverless approach, this becomes much easier since you can use storage and compute services that scale for you.

Creating a searchable enterprise document repository
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Enterprise customers frequently have repositories with thousands of documents, images and other media. While these contain valuable information for users, it’s often hard to index and search this content. One challenge is interpreting the data intelligently, and another issue is […]