AWS Big Data Blog
Tag: Analytics
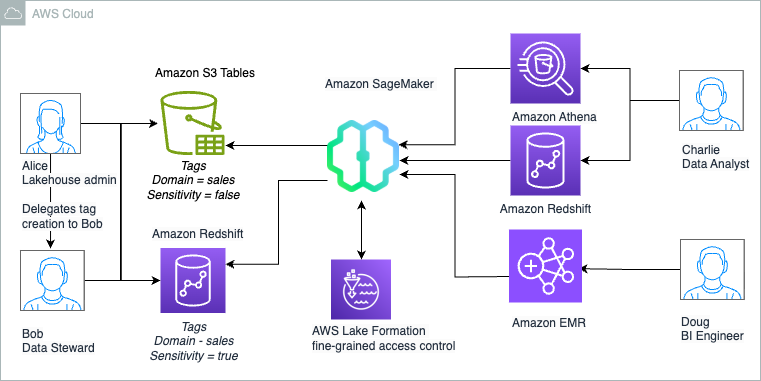
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Build data pipelines with dbt in Amazon Redshift using Amazon MWAA and Cosmos
In this post, we explore a streamlined, configuration-driven approach to orchestrate dbt Core jobs using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Cosmos, an open source package. These jobs run transformations on Amazon Redshift. With this setup, teams can collaborate effectively while maintaining data quality, operational efficiency, and observability.

Amazon OpenSearch Service 101: Create your first search application with OpenSearch
In this post, we walk you through a search application building process using Amazon OpenSearch Service. Whether you’re a developer new to search or looking to understand OpenSearch fundamentals, this hands-on post shows you how to build a search application from scratch—starting with the initial setup; diving into core components such as indexing, querying, result presentation; and culminating in the execution of your first search query.

Express brokers for Amazon MSK: Turbo-charged Kafka scaling with up to 20 times faster performance
In this post, we walk you through the implementation of MSK Express brokers, highlighting their core features, benefits, and best practices for rapid Kafka scaling.

Build Write-Audit-Publish pattern with Apache Iceberg branching and AWS Glue Data Quality
This post explores robust strategies for maintaining data quality when ingesting data into Apache Iceberg tables using AWS Glue Data Quality and Iceberg branches. We discuss two common strategies to verify the quality of published data. We dive deep into the Write-Audit-Publish (WAP) pattern, demonstrating how it works with Apache Iceberg.

Implement historical record lookup and Slowly Changing Dimensions Type-2 using Apache Iceberg
This post will explore how to look up the history of records and tables using Apache Iceberg, focusing on Slowly Changing Dimensions (SCD) Type-2. This method creates new records for each data change while preserving old ones, thus maintaining a full history. By the end, you’ll understand how to use Apache Iceberg to manage historical records effectively on a typical CDC architecture.

How Getir unleashed data democratization using a data mesh architecture with Amazon Redshift
In this post, we explain how ultrafast delivery pioneer, Getir, unleashed the power of data democratization on a large scale through their data mesh architecture using Amazon Redshift. We start by introducing Getir and their vision—to seamlessly, securely, and efficiently share business data across different teams within the organization for BI, extract, transform, and load (ETL), and other use cases. We’ll then explore how Amazon Redshift data sharing powered the data mesh architecture that allowed Getir to achieve this transformative vision.

Demystify data sharing and collaboration patterns on AWS: Choosing the right tool for the job
Adoption of data lakes and the data mesh framework emerges as a powerful approach. By decentralizing data ownership and distribution, enterprises can break down silos and enable seamless data sharing. In this post, we discuss how to choose the right tool for building an enterprise data platform and enabling data sharing, collaboration and access within your organization and with third-party providers. We address three business use cases using AWS Glue, AWS Data Exchange, AWS Clean Rooms, and Amazon DataZone through three different use cases.

Accelerate Amazon Redshift Data Lake queries with AWS Glue Data Catalog Column Statistics
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. In this post, we highlight the performance improvements we observed using industry standard TPC-DS benchmarks. Overall execution time of TPC-DS 3 TB benchmark improved by 3x. Some of the queries in our benchmark experienced up to 12x speed up.

Evaluating sample Amazon Redshift data sharing architecture using Redshift Test Drive and advanced SQL analysis
In this post, we walk you through the process of testing workload isolation architecture using Amazon Redshift Data Sharing and Test Drive utility. We demonstrate how you can use SQL for advanced price performance analysis and compare different workloads on different target Redshift cluster configurations.