AWS Big Data Blog
Tag: Amazon Redshift

Using Amazon Redshift Spectrum, Amazon Athena, and AWS Glue with Node.js in Production
This is a guest post by Rafi Ton, founder and CEO of NUVIAD. The ability to provide fresh, up-to-the-minute data to our customers and partners was always a main goal with our platform. We saw other solutions provide data that was a few hours old, but this was not good enough for us. We insisted on providing the freshest data possible. For us, that meant loading Amazon Redshift in frequent micro batches and allowing our customers to query Amazon Redshift directly to get results in near real time. The benefits were immediately evident. Our customers could see how their campaigns performed faster than with other solutions, and react sooner to the ever-changing media supply pricing and availability. They were very happy.
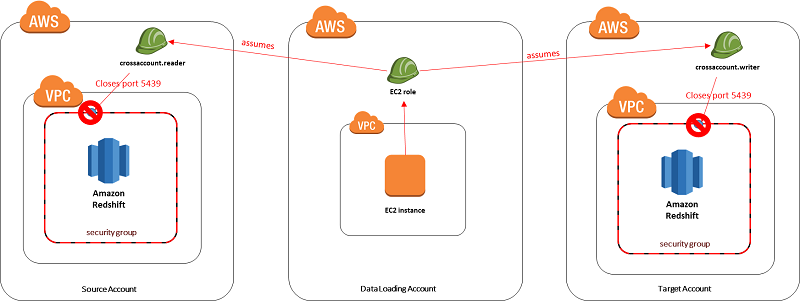
Create an Amazon Redshift Data Warehouse That Can Be Securely Accessed Across Accounts
Data security is paramount in many industries. Organizations that shift their IT infrastructure to the cloud must ensure that their data is protected and that the attack surface is minimized. This post focuses on a method of securely loading a subset of data from one Amazon Redshift cluster to another Amazon Redshift cluster that is located in a different AWS account.

Federate Database User Authentication Easily with IAM and Amazon Redshift
Managing database users though federation allows you to manage authentication and authorization procedures centrally. Amazon Redshift now supports database authentication with IAM, enabling user authentication though enterprise federation. In this post, I demonstrate how you can extend the federation to enable single sign-on (SSO) to the Amazon Redshift data warehouse.

Amazon Redshift Dense Compute (DC2) Nodes Deliver Twice the Performance as DC1 at the Same Price
Today, we are making our Dense Compute (DC) family faster and more cost-effective with new second-generation Dense Compute (DC2) nodes at the same price as our previous generation DC1. DC2 is designed for demanding data warehousing workloads that require low latency and high throughput. DC2 features powerful Intel E5-2686 v4 (Broadwell) CPUs, fast DDR4 memory, and NVMe-based solid state disks.
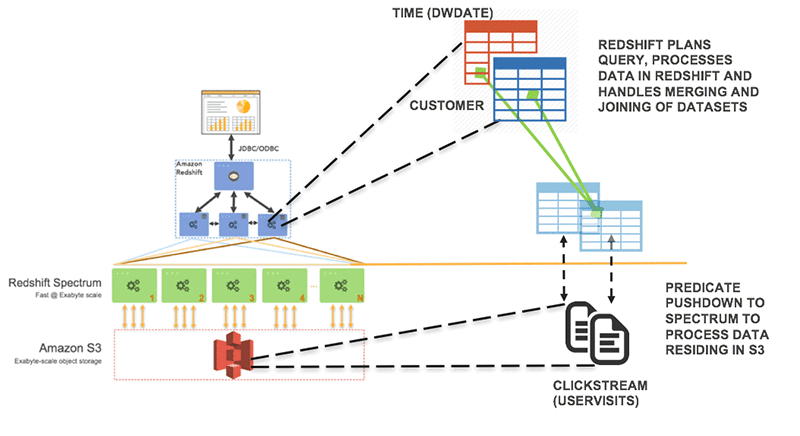
From Data Lake to Data Warehouse: Enhancing Customer 360 with Amazon Redshift Spectrum
Achieving a 360o-view of your customer has become increasingly challenging as companies embrace omni-channel strategies, engaging customers across websites, mobile, call centers, social media, physical sites, and beyond. The promise of a web where online and physical worlds blend makes understanding your customers more challenging, but also more important. Businesses that are successful in this […]

Upsert into Amazon Redshift using AWS Glue and SneaQL
This is a guest post by Jeremy Winters and Ritu Mishra, Solution Architects at Full 360. In their own words, “Full 360 is a cloud first, cloud native integrator, and true believers in the cloud since inception in 2007, our focus has been on helping customers with their journey into the cloud. Our practice areas […]

Deploy a Data Warehouse Quickly with Amazon Redshift, Amazon RDS for PostgreSQL and Tableau Server
One of the benefits of a data warehouse environment using both Amazon Redshift and Amazon RDS for PostgreSQL is that you can leverage the advantages of each service. Amazon Redshift is a high performance, petabyte-scale data warehouse service optimized for the online analytical processing (OLAP) queries typical of analytic reporting and business intelligence applications. On […]

Amazon Redshift Spectrum Extends Data Warehousing Out to Exabytes—No Loading Required
When we first looked into the possibility of building a cloud-based data warehouse many years ago, we were struck by the fact that our customers were storing ever-increasing amounts of data, and yet only a small fraction of that data ever made it into a data warehouse or Hadoop system for analysis. We saw that […]
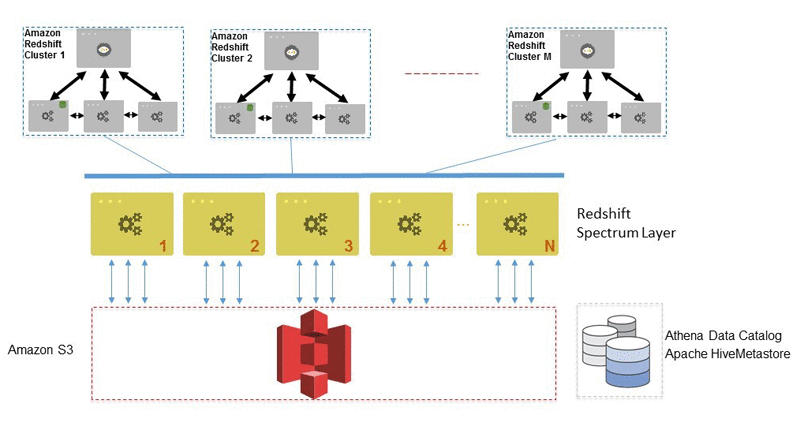
Best Practices for Amazon Redshift Spectrum
November 2022: This post was reviewed and updated for accuracy. Amazon Redshift Spectrum enables you to run Amazon Redshift SQL queries on data that is stored in Amazon Simple Storage Service (Amazon S3). With Amazon Redshift Spectrum, you can extend the analytic power of Amazon Redshift beyond the data that is stored natively in Amazon […]
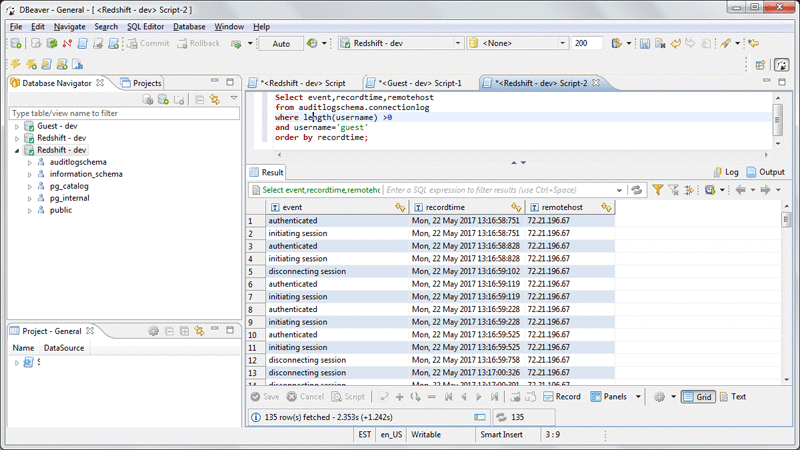
Analyze Database Audit Logs for Security and Compliance Using Amazon Redshift Spectrum
In this post, we’ll demonstrate querying the Amazon Redshift audit data logged in S3 to provide answers to common use cases described preceding.