AWS Big Data Blog
Tag: Amazon EMR

Amazon EMR-DynamoDB Connector Repository on AWSLabs GitHub
Amazon Web Services is excited to announce that the Amazon EMR-DynamoDB Connector is now open-source. The code you see in the GitHub repository is exactly what is available on your EMR cluster, making it easier to build applications with this component.

Encrypt Data At-Rest and In-Flight on Amazon EMR with Security Configurations
ustomers running analytics, stream processing, machine learning, and ETL workloads on personally identifiable information, health information, and financial data have strict requirements for encryption of data at-rest and in-transit. The Apache Spark and Hadoop ecosystems lend themselves to these big data use cases, and customers have asked us to provide a quick and easy way to encrypt data at-rest and data in-transit between nodes in each execution framework.
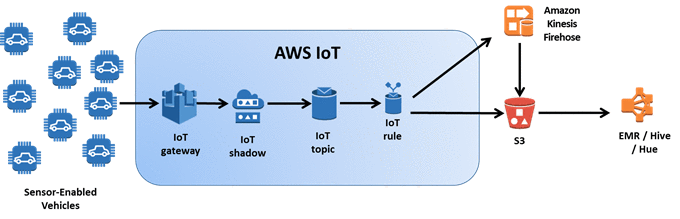
Integrating IoT Events into Your Analytic Platform
AWS IoT makes it easy to integrate and control your devices from other AWS services for even more powerful IoT applications. In particular, IoT provides tight integration with AWS Lambda, Amazon Kinesis, Amazon S3, Amazon Machine Learning, Amazon DynamoDB, Amazon CloudWatch, and Amazon OpenSearch Service.

Processing VPC Flow Logs with Amazon EMR
In this post, I show you how to gain valuable insight into your network by using Amazon EMR and Amazon VPC Flow Logs. The walkthrough implements a pattern often found in network equipment called ‘Top Talkers’, an ordered list of the heaviest network users, but the model can also be used for many other types of network analysis.

Building and Deploying Custom Applications with Apache Bigtop and Amazon EMR
This post shows you how to build a custom application for EMR for Apache Bigtop-based releases 4.x and greater. EMR nodes are based on the Amazon Linux AMI, so I will deploy on RPM packages and use Elasticsearch as the example application.

Use Spark 2.0, Hive 2.1 on Tez, and the latest from the Hadoop ecosystem on Amazon EMR release 5.0
Jonathan Fritz is a Senior Product Manager for Amazon EMR We are excited to launch Amazon EMR release 5.0 today, giving customers the latest versions of 16 supported open-source applications in the big data ecosystem, including new major versions of Spark and Hive. Almost exactly a year ago, we shipped release 4.0, which brought significant […]

Installing and Running JobServer for Apache Spark on Amazon EMR
In this blog post, you will learn how to install JobServer on EMR using a bootstrap action (BA) derived from the JobServer GitHub repository. Then we’ll run JobServer using a sample dataset.

How SmartNews Built a Lambda Architecture on AWS to Analyze Customer Behavior and Recommend Content
This is a guest post by Takumi Sakamoto, a software engineer at SmartNews. SmartNews in their own words: “SmartNews is a machine learning-based news discovery app that delivers the very best stories on the Web for more than 18 million users worldwide.” Data processing is one of the key technologies for SmartNews. Every team’s workload […]
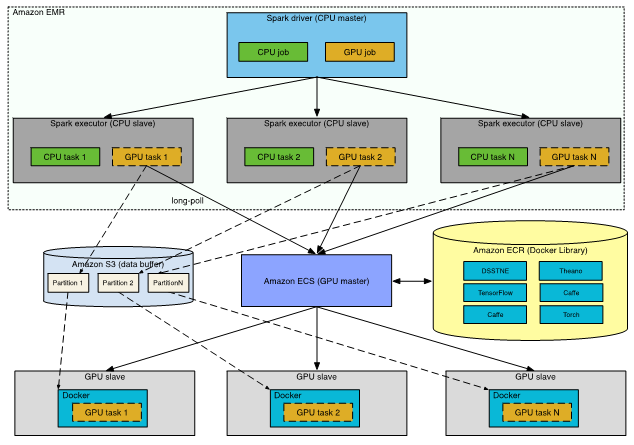
Generating Recommendations at Amazon Scale with Apache Spark and Amazon DSSTNE
In this post, I discuss an alternate solution; namely, running separate CPU and GPU clusters, and driving the end-to-end modeling process from Apache Spark.

Use Sqoop to Transfer Data from Amazon EMR to Amazon RDS
In this post, I will show you how to transfer data using Apache Sqoop, which is a tool designed to transfer data between Hadoop and relational databases. Support for Apache Sqoop is available in Amazon EMR releases 4.4.0 and later.