AWS Big Data Blog

Automated data governance with AWS Glue Data Quality, sensitive data detection, and AWS Lake Formation
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in data lakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your data lake. In this post, we showcase how to use AWS Glue with AWS Glue Data Quality, sensitive data detection transforms, and AWS Lake Formation tag-based access control to automate data governance.

Using AWS AppSync and AWS Lake Formation to access a secure data lake through a GraphQL API
Data lakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, data lake administrators often need to implement fine-grained access controls for different user profiles. They might need to restrict access to certain tables or columns depending on […]

Simplify data transfer: Google BigQuery to Amazon S3 using Amazon AppFlow
In today’s data-driven world, the ability to effortlessly move and analyze data across diverse platforms is essential. Amazon AppFlow, a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery. In this blog post, you explore the new Google BigQuery connector in Amazon AppFlow and discover how it simplifies the process of transferring data from Google’s data warehouse to Amazon Simple Storage Service (Amazon S3), providing significant benefits for data professionals and organizations, including the democratization of multi-cloud data access.

Define per-team resource limits for big data workloads using Amazon EMR Serverless
Customers face a challenge when distributing cloud resources between different teams running workloads such as development, testing, or production. The resource distribution challenge also occurs when you have different line-of-business users. The objective is not only to ensure sufficient resources be consistently available to production workloads and critical teams, but also to prevent adhoc jobs […]

Unlock data across organizational boundaries using Amazon DataZone – now generally available
We are excited to announce the general availability of Amazon DataZone. Amazon DataZone enables customers to discover, access, share, and govern data at scale across organizational boundaries, reducing the undifferentiated heavy lifting of making data and analytics tools accessible to everyone in the organization. With Amazon DataZone, data users like data engineers, data scientists, and data analysts can share and access […]

Automate legacy ETL conversion to AWS Glue using Cognizant Data and Intelligence Toolkit (CDIT) – ETL Conversion Tool
In this post, we describe how Cognizant’s Data & Intelligence Toolkit (CDIT)- ETL Conversion Tool can help you automatically convert legacy ETL code to AWS Glue quickly and effectively. We also describe the main steps involved, the supported features, and their benefits.

Query big data with resilience using Trino in Amazon EMR with Amazon EC2 Spot Instances for less cost
New enhancements in Trino with Amazon EMR provide improved resiliency for running ETL and batch workloads on Spot Instances with reduced costs. This post showcases the resilience of Amazon EMR with Trino using fault-tolerant configuration to run long-running queries on Spot Instances to save costs. We simulate Spot interruptions on Trino worker nodes by using AWS Fault Injection Simulator (AWS FIS).
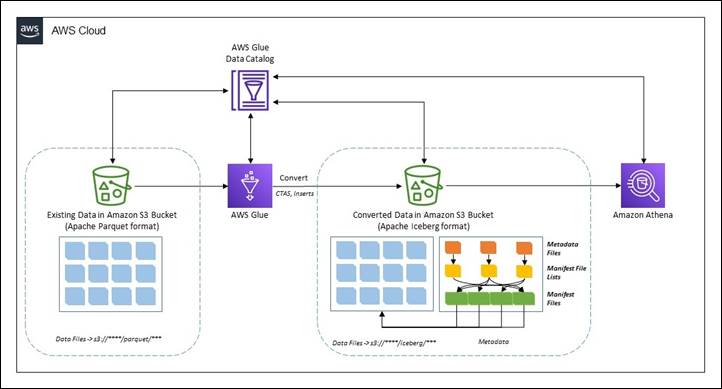
Migrate an existing data lake to a transactional data lake using Apache Iceberg
A data lake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Over the years, data lakes on Amazon Simple Storage […]

Apache Iceberg optimization: Solving the small files problem in Amazon EMR
Currently, Iceberg provides a compaction utility that compacts small files at a table or partition level. But this approach requires you to implement the compaction job using your preferred job scheduler or manually triggering the compaction job. In this post, we discuss the new Iceberg feature that you can use to automatically compact small files while writing data into Iceberg tables using Spark on Amazon EMR or Amazon Athena.

Non-JSON ingestion using Amazon Kinesis Data Streams, Amazon MSK, and Amazon Redshift Streaming Ingestion
Organizations are grappling with the ever-expanding spectrum of data formats in today’s data-driven landscape. From Avro’s binary serialization to the efficient and compact structure of Protobuf, the landscape of data formats has expanded far beyond the traditional realms of CSV and JSON. As organizations strive to derive insights from these diverse data streams, the challenge […]