AWS Big Data Blog
How Blueshift integrated their customer data environment with Amazon Redshift to unify and activate customer data for marketing
This post was co-written with Vijay Chitoor, Co-Founder & CEO, and Mehul Shah, Co-Founder and CTO from the Blueshift team, as the lead authors.
Blueshift is a San Francisco-based startup that helps marketers deliver exceptional customer experiences on every channel, delivering relevant personalized marketing. Blueshift’s SmartHub Customer Data Platform (CDP) empowers marketing teams to activate their first-party customer data to drive 1:1 personalization on owned (email, mobile) and paid (Google, Facebook, and so on) website and customer (CX) channels.
In this post, Blueshift’s founding team discuss how they used Amazon Redshift Data API to integrate data from their customer’s Amazon Redshift data warehouse with their CDP environment to help marketers activate their enterprise data and drive growth for their businesses.
Business need
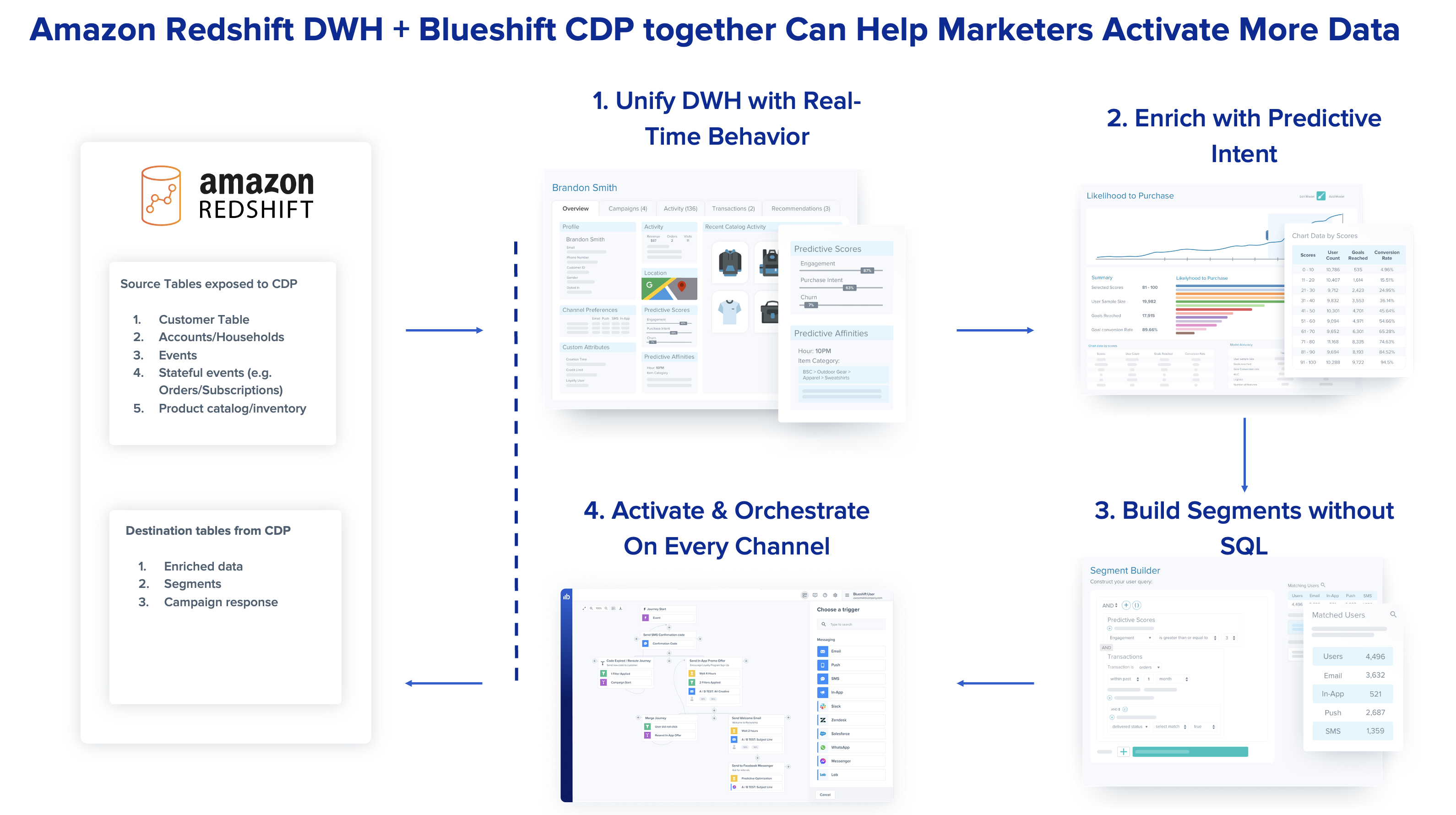
In today’s omnichannel world, marketing teams at modern enterprises are being tasked with engaging customers on multiple channels. To successfully deliver intelligent customer engagement, marketers need to operate with a 360 degree view of their customers that takes into account various types of data, including customer behavior, demographics, consent and preferences, transactions, data from human assisted and digital interactions, and more. However, unifying this data and making it actionable for marketers is often a herculean task. Now, for the first time, with the integration of Blueshift with Amazon Redshift, companies can use more data than ever for intelligent cross-channel engagement.
Amazon Redshift is a fast, fully managed cloud data warehouse. Tens of thousands of customers use Amazon Redshift as their analytics infrastructure. Users such as data analysts, database developers, and data scientists use SQL to analyze their data in Amazon Redshift data warehouses. Amazon Redshift provides a web-based query editor in addition to supporting connectivity via ODBC/JDBC or the Redshift Data API.
Blueshift aims at empowering business users to unlock data in such data warehouses and activate audiences with personalized journeys for segmentation, 1:1 messaging, website, mobile, and paid media use cases. Moreover, Blueshift can help combine this data in Amazon Redshift data warehouses with real-time website and mobile data for real-time profiles and activation, enabling this data to be used by marketers in these businesses.
Although the data in Amazon Redshift is incredibly powerful, marketers are unable to use it in it’s original form for customer engagement for a variety of reasons. Firstly, querying the data requires knowledge of query languages like SQL, which marketers aren’t necessarily adept at. Furthermore, marketers need to combine the data in the warehouse with additional sources of data that are critical for customer engagement, including real-time events (for example, a website page viewed by a customer), as well as channel-level permissions and identity.
With the new integration, Blueshift customers can ingest multidimensional data tables from Amazon Redshift (for example, a customer table, transactions table, and product catalog table) into Blueshift to build a single customer view that is accessible by marketers. The bi-directional integration also ensures that predictive data attributes computed in Blueshift, as well as campaign engagement data from Blueshift, are written back into Amazon Redshift tables, enabling technology and analytics teams to have a comprehensive view of the data.
In this post, we describe how Blueshift integrates with Amazon Redshift. We highlight the bi-directional integration with data flowing from a customer’s Amazon Redshift data warehouse to Blueshift’s CDP environment and vice versa. These mechanisms are facilitated through the use of the Redshift Data API.
Solution overview
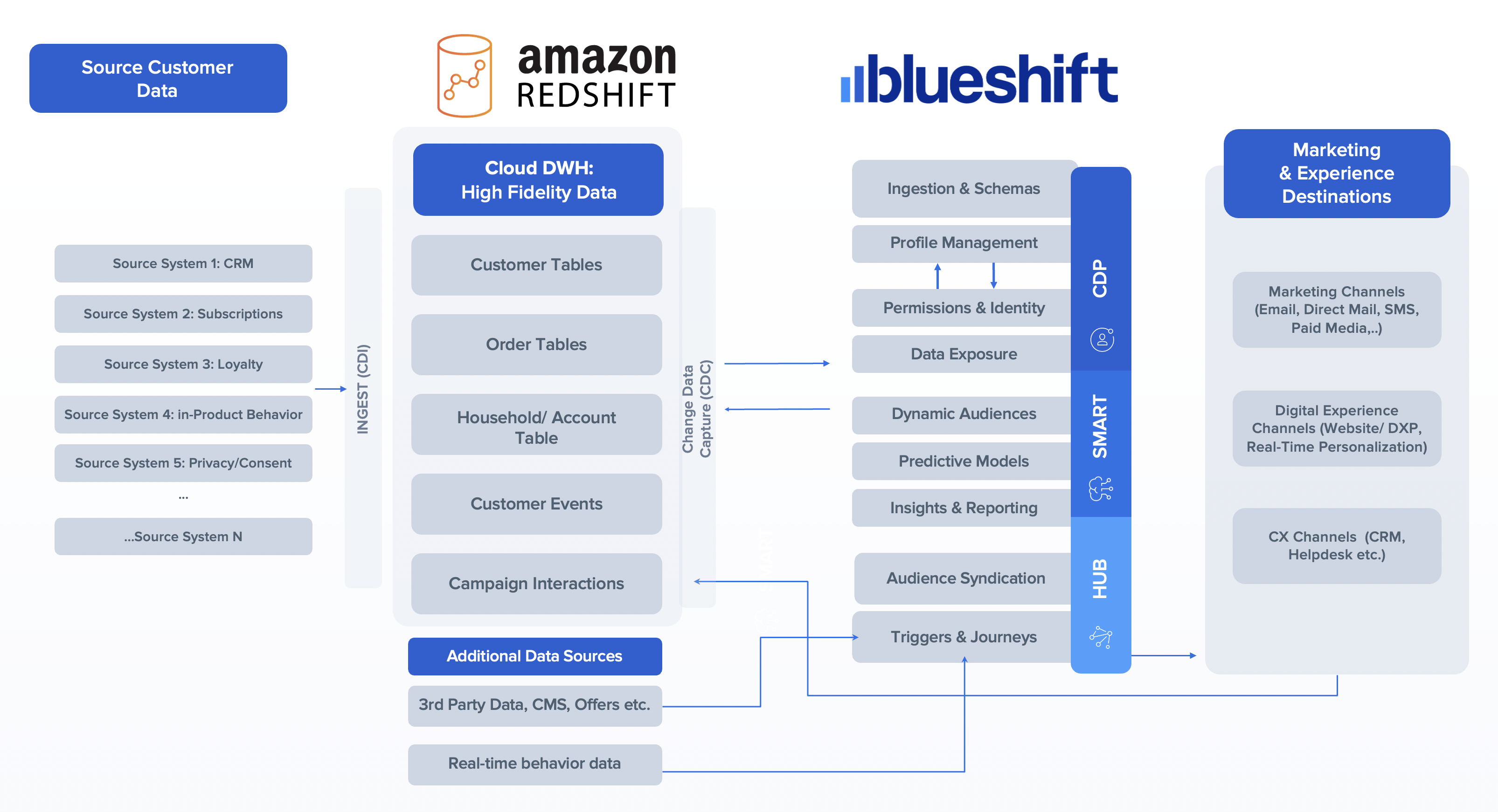
The integration between the two environments is achieved through a connector. We discuss the connector’s core components in this section. Blueshift uses a hybrid approach using Redshift S3 UNLOAD, Redshift S3 COPY, and the Redshift Data API to simplify the integration between Blueshift and Amazon Redshift, thereby facilitating the data needs to empower marketing teams. The following flow diagram shows the overview of the solution.
Blueshift uses container technology to ingest and process data. The data ingestion and egress containers are scaled up and down depending on the amount of data being processed. One of the key design tenets was to simplify the design by not having to manage connections or active connection pools. The Redshift Data API supports a HTTP-based SQL interface without the need for actively managing connections. As depicted in the process flow, the Redshift Data API lets you access data from Amazon Redshift with various types of traditional, cloud-native, containerized, serverless web service-based applications and event-driven applications. The Blueshift application includes a mix of programming languages, including Ruby (for the customer-facing dashboard), Go (for container workloads), and Python (for data science workloads). The Redshift Data API supports bindings in Python, Go, Java, Node.js, PHP, Ruby, and C++, which makes it simple for developer teams to integrate quickly.
With the Redshift Data API integration in place in Blueshift’s application, IT users from Blueshift customers can set up and validate the data connection, and subsequently Blueshift’s business users (marketers) can seamlessly extract value from data by developing insights and putting those insights into action for the customer data housed in AWS Redshift seamlessly. Therefore, the process developed by Blueshift using the Redshift Data API significantly lowers the barrier for entry for new users without needing data warehousing experience or ongoing IT dependencies for the business user.
The solution architecture depicted in the following figure shows how the various components of the CDP environment and Amazon Redshift integrate to provide the the end-to-end solution.
Prerequisites
In this section, we describe the requirements of the integration solution between the two infrastructures. A typical data implementation with customers involves data from Amazon Redshift ingesting into the Blueshift CDP environment. This ingestion mechanism must accommodate different data types, such as the following:
- Customer CRM data (user identifiers and various CRM fields). A typical range for data volume to be supported for this data type is 50–500 GB ingested once initially.
- Real-time behavior or events data (for example, playing or pausing a movie).
- Transactions data, such as subscription purchases. Typical data volumes ingested daily for events and transactions are in the 500 GB – 1 TB range.
- Catalog content (for example, a list of shows or movies for discovery), which is typically about 1 GB in size ingested daily.
The integration also needs to support Blueshift’s CDP platform environment to export data to Amazon Redshift. This includes data such as campaign activities like emails being viewed, which can run into tens of TB, and segment or user exports to support a list of users that are part of a segment definition, typically 50–500 GB exported daily.
Integrate Amazon Redshift with data applications
Amazon Redshift provides several ways to quickly integrate data applications.
For the initial data loads, Blueshift uses Redshift S3 UNLOAD to dump Amazon Redshift data into Amazon Simple Storage Service (Amazon S3). Blueshift natively uses Amazon S3 as a persistent object store and supports bulk ingestion and export from Amazon S3. Data loads from Amazon S3 are ingested in parallel and cut down on data load times, enabling Blueshift clients to quickly onboard.
For incremental data ingestion, Blueshift data import jobs track the last time an import was run, and import new rows of data that have been added or updated since the previous import ran. Blueshift stays in sync with changes (updates or inserts) to the Amazon Redshift data warehouse using the Redshift Data API. Blueshift uses the last_updated_at column in Amazon Redshift tables to determine new or updated rows and subsequently ingest those using the Redshift Data API. Blueshift’s data integration cron job syncs data in near-real time using the Redshift Data API by polling for updates on a regular cadence (for example, every 10 minutes, hourly, or daily). The cadence can be tuned depending on data freshness requirements.
The following table summarizes the integration types.
| Integration type | Integration mechanism | Advantage |
| Initial data ingestion from Amazon Redshift to Blueshift | Redshift S3 UNLOAD command | Initial data is exported from Amazon Redshift via Amazon S3 to allow faster parallel loads into Blueshift using the Amazon Redshift UNLOAD command. |
| Incremental data ingestion from Amazon Redshift to Blueshift | Redshift Data API | Incremental data changes are synchronized using the Redshift Data API in near-real time. |
| Data export from Blueshift to Amazon Redshift | Redshift S3 COPY command | Blueshift natively stores campaign activity and segment data in Amazon S3, which is loaded into Amazon Redshift using the Redshift S3 COPY command. |
Redshift supports numerous out-of-the-box mechanisms to provide data access. Blueshift was able to cut down the data onboarding time for clients by using a hybrid approach of integrating with Amazon Redshift with Redshift S3 UNLOAD, the Redshift Data API, and Redshift S3 COPY. Blueshift is able to cut down the initial data load time, as well as be updated in near-real time with changes in Amazon Redshift and vice versa.
Conclusion
In this post, we showed how Blueshift integrated with the Redshift Data API to ingest customer data. This integration was seamless and demonstrated how straightforward the Redshift Data API makes integration with external applications, such as Blueshift’s CDP environment for marketing, with Amazon Redshift. The outlined use cases in this post are just a few examples of how to use the Redshift Data API to simplify interactions between users and Amazon Redshift clusters.
Now go build and integrate Amazon Redshift with Blueshift.
About the authors
 Vijay Chittoor is the CEO & co-founder of Blueshift. Vijay has a wealth of experience in AI, marketing technology and e-commerce domains. Vijay was previously the co-founder & CEO of Mertado (acquired by Groupon to become Groupon Goods), and an early team member at Kosmix (acquired by Walmart to become @WalmartLabs). A former consultant with McKinsey & Co., Vijay is a graduate of Harvard Business School’s MBA Program. He also holds Bachelor’s and Master’s degrees in Electrical Engineering from the Indian Institute of Technology, Bombay.
Vijay Chittoor is the CEO & co-founder of Blueshift. Vijay has a wealth of experience in AI, marketing technology and e-commerce domains. Vijay was previously the co-founder & CEO of Mertado (acquired by Groupon to become Groupon Goods), and an early team member at Kosmix (acquired by Walmart to become @WalmartLabs). A former consultant with McKinsey & Co., Vijay is a graduate of Harvard Business School’s MBA Program. He also holds Bachelor’s and Master’s degrees in Electrical Engineering from the Indian Institute of Technology, Bombay.
 Mehul Shah is co-Founder & CTO at Blueshift. Previously, he was a co-founder & CTO at Mertado, which was acquired by Groupon to become Groupon Goods. Mehul was an early employee at Kosmix that was acquired by Walmart to become @WalmartLabs. Mehul is a Y Combinator alumni and a graduate of University of Southern California. Mehul is a co-inventor of 12+ patents, and coaches a middle school robotics team.
Mehul Shah is co-Founder & CTO at Blueshift. Previously, he was a co-founder & CTO at Mertado, which was acquired by Groupon to become Groupon Goods. Mehul was an early employee at Kosmix that was acquired by Walmart to become @WalmartLabs. Mehul is a Y Combinator alumni and a graduate of University of Southern California. Mehul is a co-inventor of 12+ patents, and coaches a middle school robotics team.
 Manohar Vellala is a Senior Solutions Architect at AWS working with digital native customers on their cloud native journey. He is based in San Francisco Bay Area and is passionate about helping customers build modern applications that can take the full advantage of the cloud. Prior to AWS he worked at H2O.ai where he helped customers build ML models. His interests are Storage, Data Analytics and AI/ML.
Manohar Vellala is a Senior Solutions Architect at AWS working with digital native customers on their cloud native journey. He is based in San Francisco Bay Area and is passionate about helping customers build modern applications that can take the full advantage of the cloud. Prior to AWS he worked at H2O.ai where he helped customers build ML models. His interests are Storage, Data Analytics and AI/ML.
 Prashant Tyagi joined AWS in September 2020, where he now manages the solutions architecture team focused on enabling digital native businesses. Prashant worked previously at ThermoFisher Scientific, and GE Digital where he held roles as Sr. Director for their Digital Transformation initiatives. Prashant has enabled digital transformation for customers in the Life Sciences and other industry verticals. He has experience in IoT, Data Lakes and AI/ML technical domains. He lives in the bay area in California.
Prashant Tyagi joined AWS in September 2020, where he now manages the solutions architecture team focused on enabling digital native businesses. Prashant worked previously at ThermoFisher Scientific, and GE Digital where he held roles as Sr. Director for their Digital Transformation initiatives. Prashant has enabled digital transformation for customers in the Life Sciences and other industry verticals. He has experience in IoT, Data Lakes and AI/ML technical domains. He lives in the bay area in California.