AWS Big Data Blog
Fact or Fiction: Google BigQuery Outperforms Amazon Redshift as an Enterprise Data Warehouse?
Randall Hunt is a Technical Evangelist for Amazon Web Services
A few weeks ago, 2nd Watch (a leading cloud native Systems Integrator) wrote the Benchmarking Amazon Aurora post, analyzing Google’s benchmark of their Cloud SQL database service against AWS’s Amazon Aurora. In that analysis, 2nd Watch found that Aurora outperforms Cloud SQL consistently and that Google’s benchmarks were incorrect and misleading. 2nd Watch also pointed out the peculiar aspects in Google’s approach (i.e., artificially constraining database threads to remove Aurora’s advantage of much better performance at high thread counts—something most Aurora customers take advantage of). 2nd Watch then provided their take on what a fair and reasonable performance benchmark would look like.
On September 29, 2016, Google began presenting a new data warehouse performance benchmark that had many people scratching their heads again. This time, Google compared AWS’s Amazon Redshift with Google BigQuery. Similar to the previous example, the approach taken on the tests and the marketing claims they derived from the results were oddly misleading.
Publishing misleading performance benchmarks is a classic old guard marketing tactic. It’s not surprising to see old guard companies (like Oracle) doing this, but we were kind of surprised to see Google take this approach, too. So, when Google presented their BigQuery vs. Amazon Redshift benchmark results at a private event in San Francisco on September 29, 2016, it piqued our interest and we decided to dig deeper.
For their tests, Google used the TPC-H benchmark, which measures performance against 22 different queries and is typically used to evaluate data warehouses and other decision support systems. Instead of presenting the results from all the queries, as is the standard practice, Google cherry-picked one single query that generated favorable results for BigQuery (Query #22, which happens to be one of the least sophisticated queries—one with simple filters and no joins), and used this data to make the broad claim that BigQuery outperforms Amazon Redshift.
To verify Google’s claim with our own testing, we ran the full TPC-H benchmark, consisting of all 22 queries, using a 10 TB dataset on Amazon Redshift against the latest version of BigQuery. We set up Amazon Redshift with basic configurations that our customers typically put in place, like compression, distribution keys on large tables, and sort keys on commonly filtered columns. We used an 8-node DC1.8XL Amazon Redshift cluster for the tests. Below is a summary of our findings.
Amazon Redshift outperformed BigQuery on 18 of 22 TPC-H benchmark queries by an average of 3.6X
When we ran the entire 22-query benchmark, we found that Amazon Redshift outperformed BigQuery by 3.6X on average on 18 of 22 TPC-H queries. Looking at relative performance for the entire set of queries, Amazon Redshift outperforms BigQuery by 2X. The chart below summarizes the comparison of elapsed times between the two services for the entire TPC-H benchmark (lower is better).
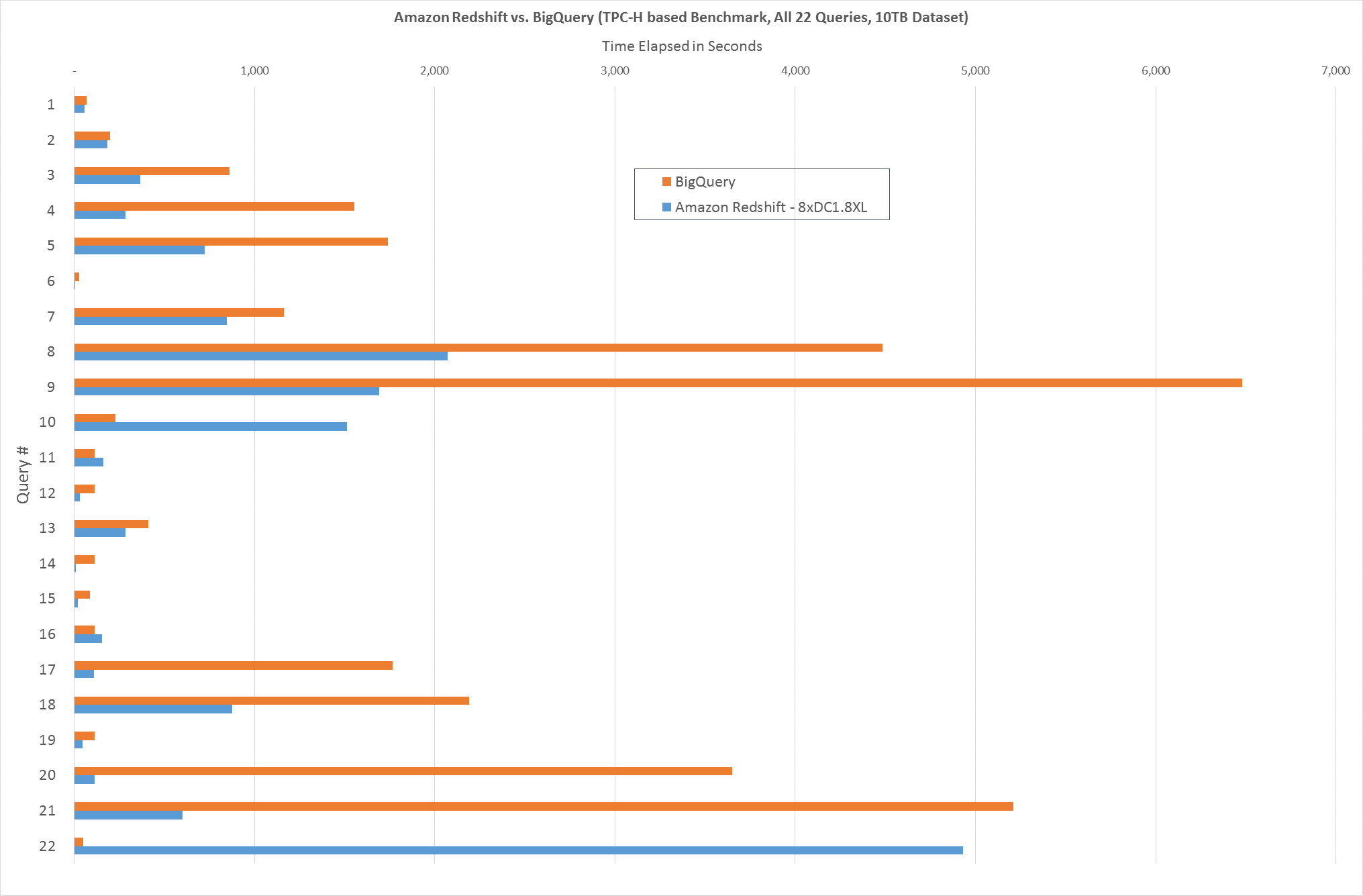
There’s a reason why TPC-H was carefully designed to evaluate the various aspects of data warehouse performance. You can’t just cherry-pick the one query where a given product is the fastest. The workloads in the database domain have broad requirements, so to get a complete view of how a database will perform for your workloads, you need to show how the benchmarked product does overall—anyone can be fast running one type of query that’s optimized for their service.
TPC-DS is a better data warehousing benchmark in which Amazon Redshift is 6 times more performant
Even though Google used the simpler TPC-H benchmark for their study, TPC-DS is well-known in the industry as the right benchmark for data warehousing workloads because it uses larger tables and more complex queries representative of real analytics use cases. We ran the entire TPC-DS consisting of 99 queries on Amazon Redshift and BigQuery. Amazon Redshift outperformed BigQuery on 94 of the 99 queries. Nine of the 99 queries did not even run successfully on BigQuery because it doesn’t fully support standard SQL and has other limitations. For the rest of the queries that did run on BigQuery, Amazon Redshift was on average 6X faster than BigQuery. The chart below summarizes the comparison of elapsed times between the two services for the TPC-DS benchmark.
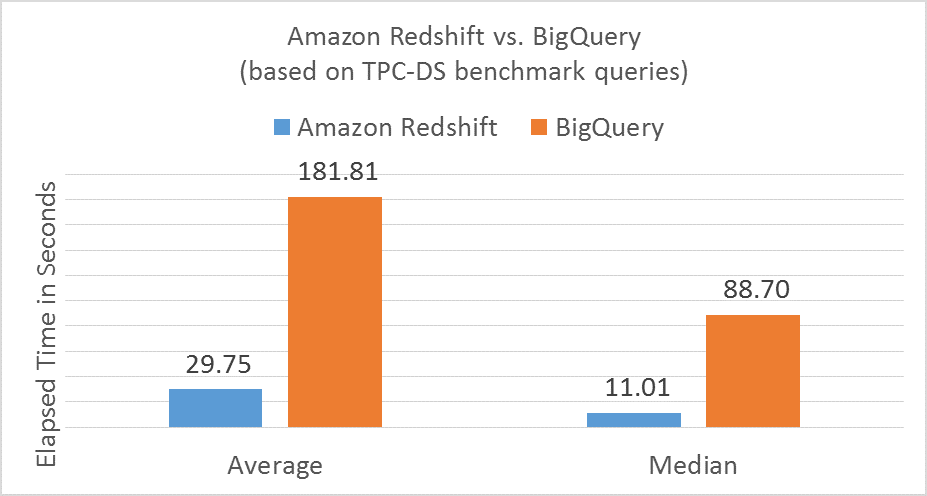
As an aside, we had to edit the SQL for 9 of the 99 TPC-DS queries to get them to run on BigQuery, which is technically not allowed in standard benchmark studies. Given Google’s claims that BigQuery now “supports standard SQL,” we were surprised to see incompatibility with queries that were completely within the standard ANSI SQL syntax. After some extensive testing, we determined that BigQuery doesn’t support at least 9 different pieces of standard ANSI SQL syntax. We believe that most customers are likely to struggle with BigQuery as an enterprise data warehouse if they can’t run their standard SQL queries without modifications. For details, see Appendix 1.
Additional factors to consider when benchmarking Amazon Redshift against BigQuery
Amazon Redshift offers customers far greater flexibility in configuring the service to get the desired level of performance for their workload. Amazon Redshift customers can choose a cluster configuration (1 to 125 nodes, HDD or SSD) that fits their price and performance requirements. Performance typically grows linearly with the number of nodes in a cluster. For example, a 10-node Amazon Redshift cluster can deliver an order of magnitude improvement in performance compared to a single-node cluster. Google’s BigQuery has no such option and distributes the data across a specific number of nodes by default. As a result, we have seen BigQuery’s performance fluctuate substantially as the same query against the same data set will often run twice (or ½) as fast on different days. This means that you have to live with the performance you get on BigQuery. This is also important to take into account when conducting your own benchmarking.
Conclusion
One of the great things about the cloud is the transparency that customers have in testing and debunking overstated performance claims and misleading “benchmark” tests. This transparency encourages the best cloud vendors to publish clear and repeatable performance metrics, making it faster and easier for their customers to select the right cloud service for a given workload. We encourage you to try benchmarking Amazon Redshift yourself to see how it will perform with your workload. Test it at scale, select the right tests for your application, and validate your assumptions. Many AWS customers, like NASDAQ, NTT Docomo, Amgen, Boingo Wireless, Cablevision, Johnson & Johnson and Philips Healthcare, have migrated their data warehouses to Amazon Redshift, increasing their performance while saving costs. We encourage you to review their experiences and apply it to your workloads as well.
Appendix 1: SQL limitations of BigQuery
While BigQuery claims to have added support for ANSI SQL, it still has several cases where query syntax deviates from ANSI SQL for unknown reasons. This requires users to learn these nuances and affects productivity. Below is a sample of such limitations:
- Does not support the ANSI SQL syntax of substring. Need to change to substr.
- Does not support Top N. Only supports LIMIT N at the end of the SQL
- Does not support NUMERIC. Only supports INT or FLOAT. There is a loss of precision on many queries (data quality). TPC-DS queries set a specific number of positions for intermediate calculations with CAST. It is not supported by BigQuery.
- DATE datatype is new and none of BigQuery’s functions support it yet in ANSI. Even if you try to convert to TIMESTAMP first, DATEDIFF and DATE_ADD does not work. BigQuery in “Legacy SQL” mode supports this but then joins don’t really work.
- While Group by <expression> allows positioning references, copying an expression (substr for example) from the projection down to the group by is not allowed. You have to use positioning.
- Does not support INTERSECT or EXCEPT.
- Does not support UNION syntax. Requires you to use UNION DISTINCT or ALL.
- Column Alias needs to be a valid identifier. Should only be letters or numbers. No quotes can be used. So “SUM OF SALES” is not a valid alias.
- You always have to prefix the dataset name on all SQL. No concept of search path or default schema/database.