AWS Big Data Blog
Empower your Jira data in a data lake with Amazon AppFlow and AWS Glue
In the world of software engineering and development, organizations use project management tools like Atlassian Jira Cloud. Managing projects with Jira leads to rich datasets, which can provide historical and predictive insights about project and development efforts.
Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. Companies often take a data lake approach to their analytics, bringing data from many different systems into one place to simplify how the analytics are done.
This post shows you how to use Amazon AppFlow and AWS Glue to create a fully automated data ingestion pipeline that will synchronize your Jira data into your data lake. Amazon AppFlow provides software as a service (SaaS) integration with Jira Cloud to load the data into your AWS account. AWS Glue is a serverless data discovery, load, and transformation service that will prepare data for consumption in BI and AI/ML activities. Additionally, this post strives to achieve a low-code and serverless solution for operational efficiency and cost optimization, and the solution supports incremental loading for cost optimization.
Solution overview
This solution uses Amazon AppFlow to retrieve data from the Jira Cloud. The data is synchronized to an Amazon Simple Storage Service (Amazon S3) bucket using an initial full download and subsequent incremental downloads of changes. When new data arrives in the S3 bucket, an AWS Step Functions workflow is triggered that orchestrates extract, transform, and load (ETL) activities using AWS Glue crawlers and AWS Glue DataBrew. The data is then available in the AWS Glue Data Catalog and can be queried by services such as Amazon Athena, Amazon QuickSight, and Amazon Redshift Spectrum. The solution is completely automated and serverless, resulting in low operational overhead. When this setup is complete, your Jira data will be automatically ingested and kept up to date in your data lake!
The following diagram illustrates the solution architecture.
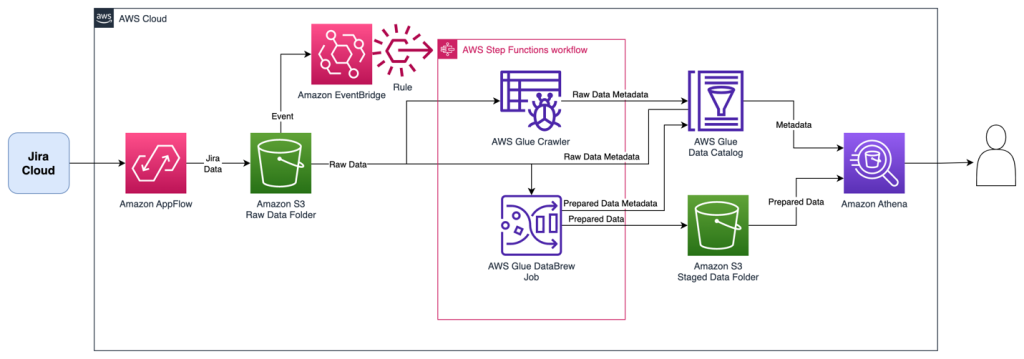
The Step Functions workflow orchestrates the following ETL activities, resulting in two tables:
- An AWS Glue crawler collects all downloads into a single AWS Glue table named
jira_raw. This table is comprised of a mix of full and incremental downloads from Jira, with many versions of the same records representing changes over time. - A DataBrew job prepares the data for reporting by unpacking key-value pairs in the fields, as well as removing depreciated records as they are updated in subsequent change data captures. This reporting-ready data will available in an AWS Glue table named
jira_data.
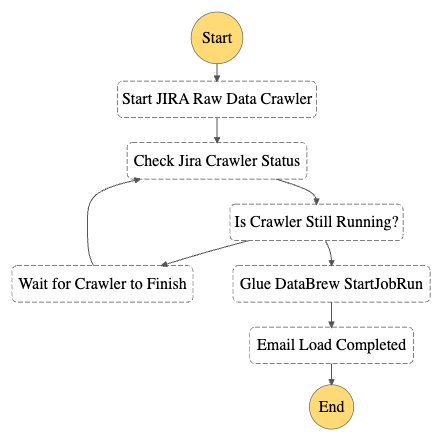
The following figure shows the Step Functions workflow.
Prerequisites
This solution requires the following:
- Administrative access to your Jira Cloud instance, and an associated Jira Cloud developer account.
- An AWS account and a login with access to the AWS Management Console. Your login will need AWS Identity and Access Management (IAM) permissions to create and access the resources in your AWS account.
- Basic knowledge of AWS and working knowledge of Jira administration.
Configure the Jira Instance
After logging in to your Jira Cloud instance, you establish a Jira project with associated epics and issues to download into a data lake. If you’re starting with a new Jira instance, it helps to have at least one project with a sampling of epics and issues for the initial data download, because it allows you to create an initial dataset without errors or missing fields. Note that you may have multiple projects as well.
After you have established your Jira project and populated it with epics and issues, ensure you also have access to the Jira developer portal. In later steps, you use this developer portal to establish authentication and permissions for the Amazon AppFlow connection.
Provision resources with AWS CloudFormation
For the initial setup, you launch an AWS CloudFormation stack to create an S3 bucket to store data, IAM roles for data access, and the AWS Glue crawler and Data Catalog components. Complete the following steps:
- Sign in to your AWS account.
- Click Launch Stack:

- For Stack name, enter a name for the stack (the default is
aws-blog-jira-datalake-with-AppFlow). - For GlueDatabaseName, enter a unique name for the Data Catalog database to hold the Jira data table metadata (the default is
jiralake). - For InitialRunFlag, choose Setup. This mode will scan all data and disable the change data capture (CDC) features of the stack. (Because this is the initial load, the stack needs an initial data load before you configure CDC in later steps.)
- Under Capabilities and transforms, select the acknowledgement check boxes to allow IAM resources to be created within your AWS account.
- Review the parameters and choose Create stack to deploy the CloudFormation stack. This process will take around 5–10 minutes to complete.

- After the stack is deployed, review the Outputs tab for the stack and collect the following values to use when you set up Amazon AppFlow:
- Amazon AppFlow destination bucket (
o01AppFlowBucket) - Amazon AppFlow destination bucket path (
o02AppFlowPath) - Role for Amazon AppFlow Jira connector (
o03AppFlowRole)

- Amazon AppFlow destination bucket (
Configure Jira Cloud
Next, you configure your Jira Cloud instance for access by Amazon AppFlow. For full instructions, refer to Jira Cloud connector for Amazon AppFlow. The following steps summarize these instructions and discuss the specific configuration to enable OAuth in the Jira Cloud:
- Open the Jira developer portal.
- Create the OAuth 2 integration from the developer application console by choosing Create an OAuth 2.0 Integration. This will provide a login mechanism for AppFlow.
- Enable fine-grained permissions. See Recommended scopes for the permission settings to grant AppFlow appropriate access to your Jira instance.
- Add the following permission scopes to your OAuth app:
manage:jira-configurationread:field-configuration:jira
- Under Authorization, set the Call Back URL to return to Amazon AppFlow with the URL
https://us-east-1.console.thinkwithwp.com/AppFlow/oauth. - Under Settings, note the client ID and secret to use in later steps to set up authentication from Amazon AppFlow.
Create the Amazon AppFlow Jira Cloud connection
In this step, you configure Amazon AppFlow to run a one-time full data fetch of all your data, establishing the initial data lake:
- On the Amazon AppFlow console, choose Connectors in the navigation pane.
- Search for the Jira Cloud connector.
- Choose Create flow on the connector tile to create the connection to your Jira instance.

- For Flow name, enter a name for the flow (for example,
JiraLakeFlow). - Leave the Data encryption setting as the default.
- Choose Next.

- For Source name, keep the default of Jira Cloud.
- Choose Create new connection under Jira Cloud connection.

- In the Connect to Jira Cloud section, enter the values for Client ID, Client secret, and Jira Cloud Site that you collected earlier. This provides the authentication from AppFlow to Jira Cloud.
- For Connection Name, enter a connection name (for example,
JiraLakeCloudConnection). - Choose Connect. You will be prompted to allow your OAuth app to access your Atlassian account to verify authentication.

- In the Authorize App window that pops up, choose Accept.
- With the connection created, return to the Configure flow section on the Amazon AppFlow console.
- For API version, choose V2 to use the latest Jira query API.
- For Jira Cloud object, choose Issue to query and download all issues and associated details.

- For Destination Name in the Destination Details section, choose Amazon S3.
- For Bucket details, choose the S3 bucket name that matches the Amazon AppFlow destination bucket value that you collected from the outputs of the CloudFormation stack.
- Enter the Amazon AppFlow destination bucket path to complete the full S3 path. This will send the Jira data to the S3 bucket created by the CloudFormation script.
- Leave Catalog your data in the AWS Glue Data Catalog unselected. The CloudFormation script uses an AWS Glue crawler to update the Data Catalog in a different manner, grouping all the downloads into a common table, so we disable the update here.
- For File format settings, select Parquet format and select Preserve source data types in Parquet output. Parquet is a columnar format to optimize subsequent querying.
- Select Add a timestamp to the file name for Filename preference. This will allow you to easily find data files downloaded at a specific date and time.

- For now, select Run on Demand for the Flow trigger to run the full load flow manually. You will schedule downloads in a later step when implementing CDC.
- Choose Next.

- On the Map data fields page, select Manually map fields.
- For Source to destination field mapping, choose the drop-down box under Source field name and select Map all fields directly. This will bring down all fields as they are received, because we will instead implement data preparation in later steps.

- Under Partition and aggregation settings, you can set up the partitions in a way that works for your use case. For this example, we use a daily partition, so select Date and time and choose Daily.
- For Aggregation settings, leave it as the default of Don’t aggregate.
- Choose Next.

- On the Add filters page, you can create filters to only download specific data. For this example, you download all the data, so choose Next.
- Review and choose Create flow.
- When the flow is created, choose Run flow to start the initial data seeding. After some time, you should receive a banner indicating the run finished successfully.

Review seed data
At this stage in the process, you now have data in your S3 environment. When new data files are created in the S3 bucket, it will automatically run an AWS Glue crawler to catalog the new data. You can see if it’s complete by reviewing the Step Functions state machine for a Succeeded run status. There is a link to the state machine on the CloudFormation stack’s Resources tab, which will redirect you to the Step Functions state machine.
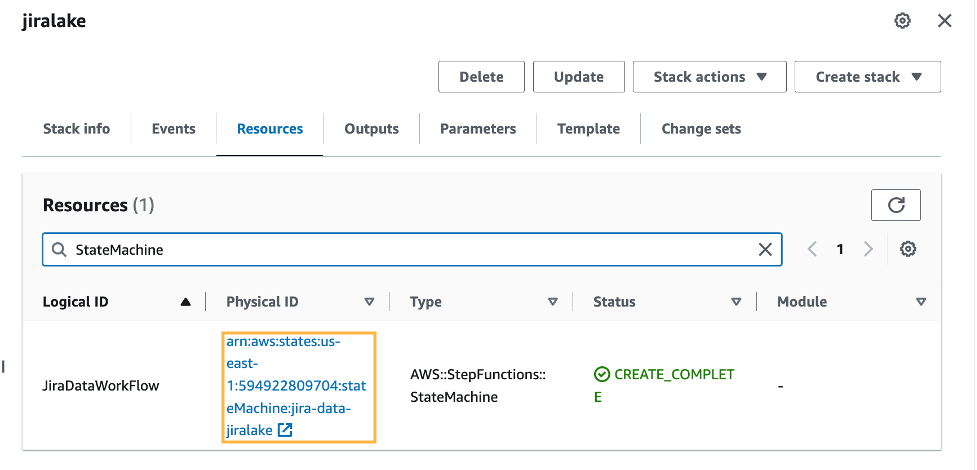
When the state machine is complete, it’s time to review the raw Jira data with Athena. The database is as you specified in the CloudFormation stack (jiralake by default), and the table name is jira_raw. If you kept the default AWS Glue database name of jiralake, the Athena SQL is as follows:
If you explore the data, you’ll notice that most of the data you would want to work with is actually packed into a column called fields. This means the data is not available as columns in your Athena queries, making it harder to select, filter, and sort individual fields within an Athena SQL query. This will be addressed in the next steps.
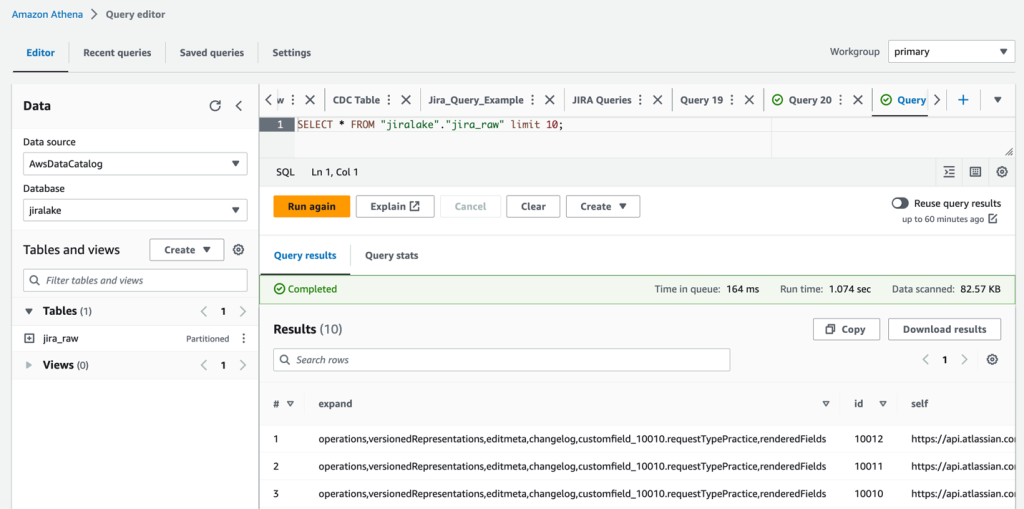
Set up CDC and unpack the fields columns
To add the ongoing CDC and reformat the data for analytics, we introduce a DataBrew job to transform the data and filter to the most recent version of each record as changes come in. You can do this by updating the CloudFormation stack with a flag that includes the CDC and data transformation steps.
- On the AWS CloudFormation console, return to the stack.
- Choose Update.
- Select Use current template and choose Next.

- For SetupOrCDC, choose CDC, then choose Next. This will enable both the CDC steps and the data transformation steps for the Jira data.

- Continue choosing Next until you reach the Review section.
- Select I acknowledge that AWS CloudFormation might create IAM resources, then choose Submit.

- Return to the Amazon AppFlow console and open your flow.
- On the Actions menu, choose Edit flow. We will now edit the flow trigger to run an incremental load on a periodic basis.
- Select Run flow on schedule.
- Configure the desired repeats, as well as start time and date. For this example, we choose Daily for Repeats and enter 1 for the number of days you’ll have the flow trigger. For Starting at, enter 01:00.
- Select Incremental transfer for Transfer mode.
- Choose Updated on the drop-down menu so that changes will be captured based on when the records were updated.
- Choose Save. With these settings in our example, the run will happen nightly at 1:00 AM.

Review the analytics data
When the next incremental load occurs that results in new data, the Step Functions workflow will start the DataBrew job and populate a new staged analytical data table named jira_data in your Data Catalog database. If you don’t want to wait, you can trigger the Step Functions workflow manually.
The DataBrew job performs data transformation and filtering tasks. The job unpacks the key-values from the Jira JSON data and the raw Jira data, resulting in a tabular data schema that facilitates use with BI and AI/ML tools. As Jira items are changed, the changed item’s data is resent, resulting in multiple versions of an item in the raw data feed. The DataBrew job filters the raw data feed so that the resulting data table only contains the most recent version of each item. You could enhance this DataBrew job to further customize the data for your needs, such as renaming the generic Jira custom field names to reflect their business meaning.
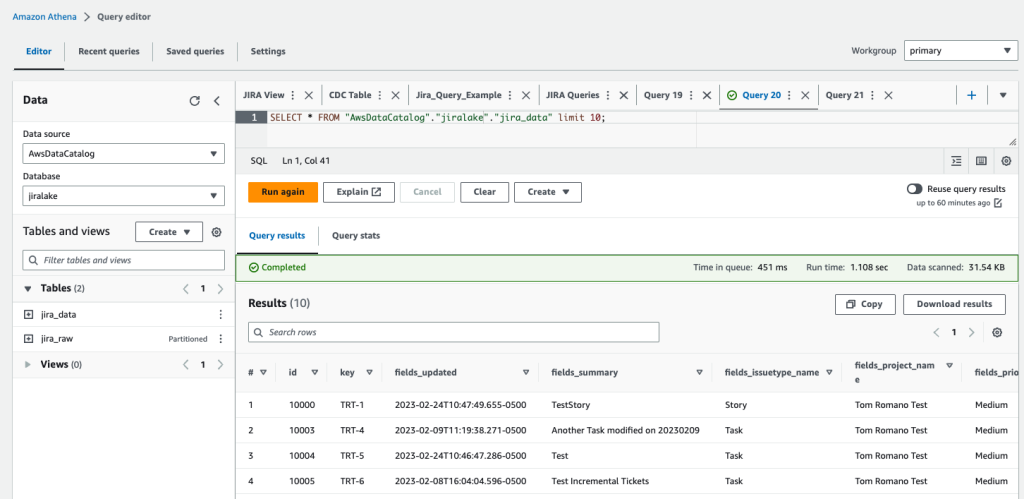
When the Step Functions workflow is complete, we can query the data in Athena again using the following query:
You can see that in our transformed jira_data table, the nested JSON fields are broken out into their own columns for each field. You will also notice that we’ve filtered out obsolete records that have been superseded by more recent record updates in later data loads so the data is fresh. If you want to rename custom fields, remove columns, or restructure what comes out of the nested JSON, you can modify the DataBrew recipe to accomplish this. At this point, the data is ready to be used by your analytics tools, such as Amazon QuickSight.
Clean up
If you would like to discontinue this solution, you can remove it with the following steps:
- On the Amazon AppFlow console, deactivate the flow for Jira, and optionally delete it.
- On the Amazon S3 console, select the S3 bucket for the stack, and empty the bucket to delete the existing data.
- On the AWS CloudFormation console, delete the CloudFormation stack that you deployed.
Conclusion
In this post, we created a serverless incremental data load process for Jira that will synchronize data while handling custom fields using Amazon AppFlow, AWS Glue, and Step Functions. The approach uses Amazon AppFlow to incrementally load the data into Amazon S3. We then use AWS Glue and Step Functions to manage the extraction of the Jira custom fields and load them in a format to be queried by analytics services such as Athena, QuickSight, or Redshift Spectrum, or AI/ML services like Amazon SageMaker.
To learn more about AWS Glue and DataBrew, refer to Getting started with AWS Glue DataBrew. With DataBrew, you can take the sample data transformation in this project and customize the output to meet your specific needs. This could include renaming columns, creating additional fields, and more.
To learn more about Amazon AppFlow, refer to Getting started with Amazon AppFlow. Note that Amazon AppFlow supports integrations with many SaaS applications in addition to the Jira Cloud.
To learn more about orchestrating flows with Step Functions, see Create a Serverless Workflow with AWS Step Functions and AWS Lambda. The workflow could be enhanced to load the data into a data warehouse, such as Amazon Redshift, or trigger a refresh of a QuickSight dataset for analytics and reporting.
In future posts, we will cover how to unnest parent-child relationships within the Jira data using Athena and how to visualize the data using QuickSight.
About the Authors
 Tom Romano is a Sr. Solutions Architect for AWS World Wide Public Sector from Tampa, FL, and assists GovTech and EdTech customers as they create new solutions that are cloud native, event driven, and serverless. He is an enthusiastic Python programmer for both application development and data analytics, and is an Analytics Specialist. In his free time, Tom flies remote control model airplanes and enjoys vacationing with his family around Florida and the Caribbean.
Tom Romano is a Sr. Solutions Architect for AWS World Wide Public Sector from Tampa, FL, and assists GovTech and EdTech customers as they create new solutions that are cloud native, event driven, and serverless. He is an enthusiastic Python programmer for both application development and data analytics, and is an Analytics Specialist. In his free time, Tom flies remote control model airplanes and enjoys vacationing with his family around Florida and the Caribbean.
 Shane Thompson is a Sr. Solutions Architect based out of San Luis Obispo, California, working with AWS Startups. He works with customers who use AI/ML in their business model and is passionate about democratizing AI/ML so that all customers can benefit from it. In his free time, Shane loves to spend time with his family and travel around the world.
Shane Thompson is a Sr. Solutions Architect based out of San Luis Obispo, California, working with AWS Startups. He works with customers who use AI/ML in their business model and is passionate about democratizing AI/ML so that all customers can benefit from it. In his free time, Shane loves to spend time with his family and travel around the world.