AWS Big Data Blog
Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container
Mar 2025: This post was written for AWS Glue 3.0 and 4.0. For AWS Glue 5.0, visit Develop and test AWS Glue 5.0 jobs locally using a Docker container.
Apr 2023: This post was reviewed and updated with enhanced support for Glue 4.0 Streaming jobs.
Jan 2023: This post was reviewed and updated with enhanced support for Glue 3.0 Streaming jobs, ARM64, and Glue 4.0.
AWS Glue is a fully managed serverless service that allows you to process data coming through different data sources at scale. You can use AWS Glue jobs for various use cases such as data ingestion, preprocessing, enrichment, and data integration from different data sources. AWS Glue version 3.0 provides a performance-optimized Apache Spark 3.1 runtime experience for batch and stream processing. AWS Glue version 4.0, the latest version of AWS Glue Spark jobs, provides a performance-optimized Apache Spark 3.3 runtime experience.
You can author AWS Glue jobs in different ways. If you prefer coding, AWS Glue allows you to write Python/Scala source code with the AWS Glue ETL library. If you prefer interactive scripting, AWS Glue interactive sessions and AWS Glue Studio notebooks helps you to write scripts in notebooks by inspecting and visualizing the data. If you prefer a graphical interface rather than coding, AWS Glue Studio helps you author data integration jobs visually without writing code.
For a production-ready data platform, a development process and CI/CD pipeline for AWS Glue jobs is key. We understand the huge demand for developing and testing AWS Glue jobs where you prefer to have flexibility, a local laptop, a Docker container on Amazon Elastic Compute Cloud (Amazon EC2), and so on. You can achieve that by using AWS Glue Docker images hosted on Docker Hub or the Amazon Elastic Container Registry (Amazon ECR) Public Gallery. The Docker images help you set up your development environment with additional utilities. You can use your preferred IDE, notebook, or REPL using the AWS Glue ETL library.
This post is a continuation of blog post “Developing AWS Glue ETL jobs locally using a container“. While the earlier post introduced the pattern of development for AWS Glue ETL Jobs on a Docker container using a Docker image, this post focuses on how to develop and test AWS Glue version 3.0 and 4.0 jobs using the same approach.
Available Docker images
Spark
The following Docker images are available for AWS Glue on Docker Hub:
- AWS Glue version 4.0 –
amazon/aws-glue-libs:glue_libs_4.0.0_image_01 - AWS Glue version 3.0 –
amazon/aws-glue-libs:glue_libs_3.0.0_image_01 - AWS Glue version 2.0 –
amazon/aws-glue-libs:glue_libs_2.0.0_image_01
You can also obtain the images from the Amazon ECR Public Gallery:
- AWS Glue version 4.0 –
public.ecr.aws/glue/aws-glue-libs:glue_libs_4.0.0_image_01 - AWS Glue version 3.0 –
public.ecr.aws/glue/aws-glue-libs:glue_libs_3.0.0_image_01 - AWS Glue version 2.0 –
public.ecr.aws/glue/aws-glue-libs:glue_libs_2.0.0_image_01
Spark Streaming
The following Docker image is available for AWS Glue on Docker Hub:
- AWS Glue version 4.0 –
amazon/aws-glue-streaming-libs:glue_streaming_libs_4.0.0_image_01 - AWS Glue version 3.0 –
amazon/aws-glue-streaming-libs:glue_streaming_libs_3.0.0_image_01
You can also obtain the image from the Amazon ECR Public Gallery:
- AWS Glue version 4.0 –
public.ecr.aws/glue/aws-glue-streaming-libs:glue_streaming_libs_4.0.0_image_01 - AWS Glue version 3.0 –
public.ecr.aws/glue/aws-glue-streaming-libs:glue_streaming_libs_3.0.0_image_01
Note: AWS Glue Docker images are compatible with both x86_64 and arm64.
In this post, we use amazon/aws-glue-libs:glue_libs_3.0.0_image_01 and run the container on a local machine (Mac, Windows, or Linux). This container image has been tested for AWS Glue version 3.0 Spark jobs. The image contains the following:
- Amazon Linux
- AWS Glue ETL Library (aws-glue-libs)
- Apache Spark 3.1.1
- Spark history server
- JupyterLab
- Livy
- Other library dependencies (the same as the ones of the AWS Glue job system)
To set up your container, you pull the image from Docker Hub and then run the container. We demonstrate how to run your container with the following methods, depending on your requirements:
spark-submit- REPL shell (
pyspark) pytest- JupyterLab
- Visual Studio Code
Prerequisites
Before you start, make sure that Docker is installed and the Docker daemon is running. For installation instructions, see the Docker documentation for Mac, Windows, or Linux. Also make sure that you have at least 7 GB of disk space for the image on the host running Docker.
For more information about restrictions when developing AWS Glue code locally, see Local Development Restrictions.
Configure AWS credentials
To enable AWS API calls from the container, set up your AWS credentials with the following steps:
- Create an AWS named profile.
- Open
cmdon Windows or a terminal on Mac/Linux, and run the following command:
In the following sections, we use this AWS named profile.
Pull the image from Docker Hub
If you’re running Docker on Windows, choose the Docker icon (right-click) and choose Switch to Linux containers… before pulling the image.
Run the following command to pull the image from Docker Hub:
Run the container
Now you can run a container using this image. You can choose any of following methods based on your requirements.
spark-submit
You can run an AWS Glue job script by running the spark-submit command on the container.
Write your ETL script (sample.py in the example below) and save it under the /local_path_to_workspace/src/ directory using the following commands:
These variables are used in the docker run command below. The sample code (sample.py) used in the spark-submit command below is included in the appendix at the end of this post.
Run the following command to run the spark-submit command on the container to submit a new Spark application:
REPL shell (pyspark)
You can run a REPL (read-eval-print loop) shell for interactive development. Run the following command to run the pyspark command on the container to start the REPL shell:
pytest
For unit testing, you can use pytest for AWS Glue Spark job scripts.
Run the following commands for preparation:
Run the following command to run pytest on the test suite:
JupyterLab
You can start Jupyter for interactive development and ad hoc queries on notebooks. Complete the following steps:
- Run the following command to start JupyterLab:
- Open http://127.0.0.1:8888/lab in your web browser in your local machine to access the JupyterLab UI.

- Choose Glue Spark Local (PySpark) under Notebook.
Now you can start developing code in the interactive Jupyter notebook UI.

Visual Studio Code
To set up the container with Visual Studio Code, complete the following steps:
- Install Visual Studio Code.
- Install Python.
- Install Visual Studio Code Remote – Containers.
- Open the workspace folder in Visual Studio Code.
- Choose Settings.
- Choose Workspace.
- Choose Open Settings (JSON).
- Enter the following JSON and save it:
Now you’re ready to set up the container.
- Run the Docker container:
- Start Visual Studio Code.
- Choose Remote Explorer in the navigation pane, and choose the container
amazon/aws-glue-libs:glue_libs_3.0.0_image_01.

- Right-click and choose Attach to Container.

- If the following dialog appears, choose Got it.
- Open
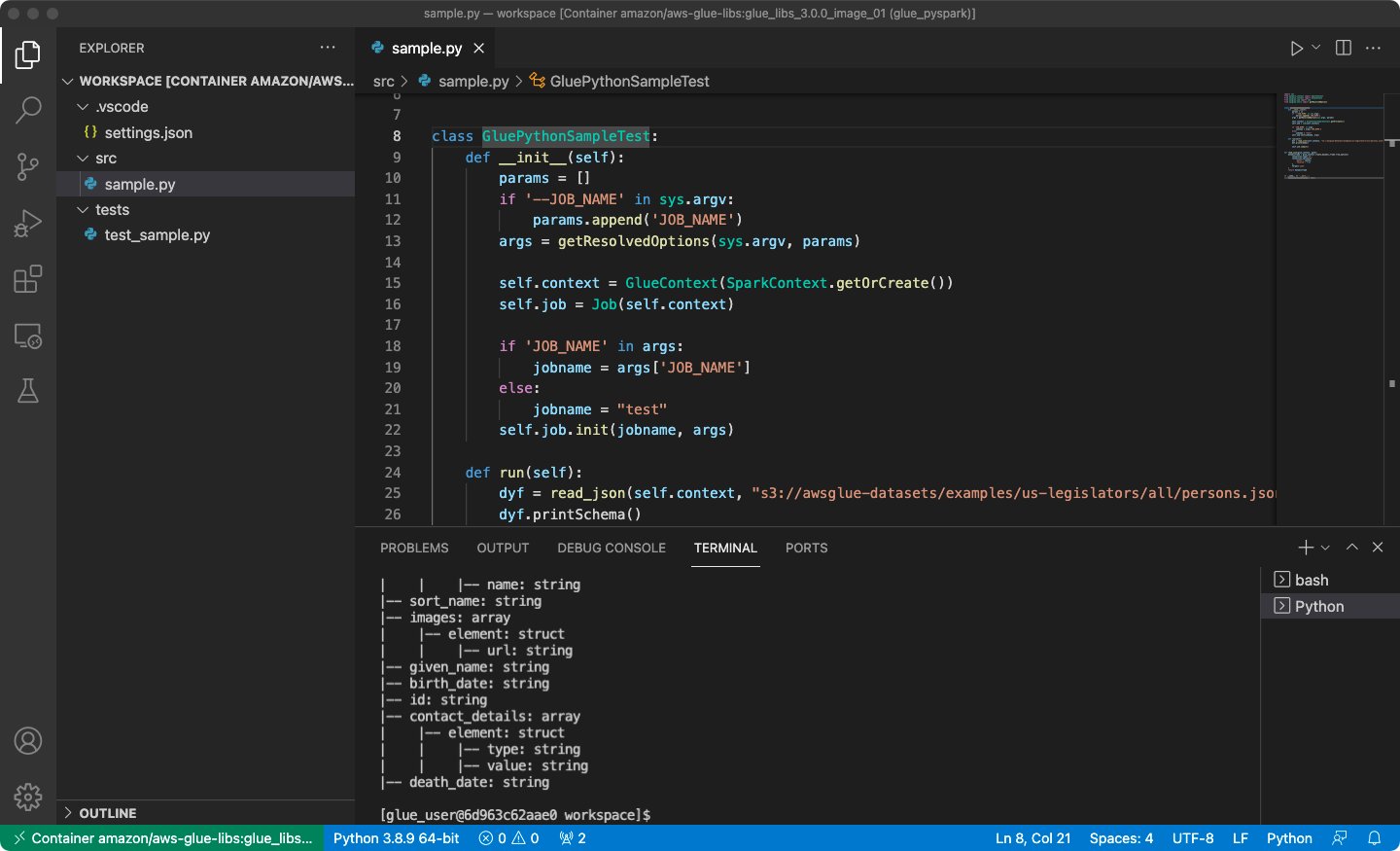
/home/glue_user/workspace/. - Create an AWS Glue PySpark script and choose Run.
You should see the successful run on the AWS Glue PySpark script.
Conclusion
In this post, we learned how to get started on AWS Glue Docker images. AWS Glue Docker images help you develop and test your AWS Glue job scripts anywhere you prefer. It is available on Docker Hub and Amazon ECR Public Gallery. Check it out, we look forward to getting your feedback.
Appendix A: AWS Glue job sample codes for testing
This appendix introduces three different scripts as AWS Glue job sample codes for testing purposes. You can use any of them in the tutorial.
The following sample.py code uses the AWS Glue ETL library with an Amazon Simple Storage Service (Amazon S3) API call. The code requires Amazon S3 permissions in AWS Identity and Access Management (IAM). You need to grant the IAM-managed policy arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess or IAM custom policy that allows you to make ListBucket and GetObject API calls for the S3 path.
The following test_sample.py code is a sample for a unit test of sample.py:
Appendix B: Add extra libraries
You can add extra libraries in each option. Following examples are to add Snowflake Connector for Spark and Snowflake JDBC driver into the local container.
spark-submit: Add local JAR files
For spark-submit, use --jars option on a Docker volume to add local libraries:
- Download JAR files
- Locate JAR files into the workspace directory
- Run
spark-submitcommand with--jarsoption
spark-submit: Add libraries from Maven
For spark-submit, use --packages option on a Docker volume to add libraries from Maven:
JupyterLab: Add local Python libraries
For JupyterLab, run %%configure magic on a notebook to add local libraries:
- Locate your python libraries under
$EXTRA_PYTHON_PACKAGE_LOCATION - Run
jupyter_start.shwith a newPYTHONPATHenvironment variable
JupyterLab: Add libraries from Maven
For JupyterLab, run %%configure magic on a notebook to add extra libraries from Maven:
Glue 4.0: Add native data lake libraries
AWS Glue 4.0 Docker image supports native data lake libraries; Apache Hudi, Delta Lake, and Apache Iceberg.
You can pass the environment variable DATALAKE_FORMATS to load the relevant JAR files.


