AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)
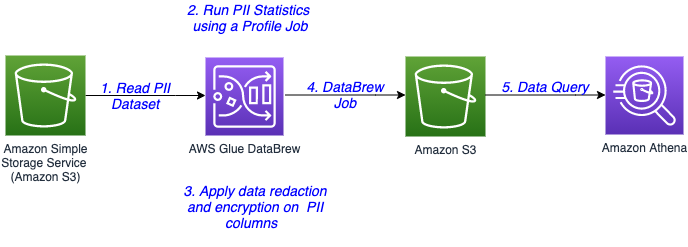
Introducing PII data identification and handling using AWS Glue DataBrew
AWS Glue DataBrew, a visual data preparation tool, now allows users to identify and handle sensitive data by applying advanced transformations like redaction, replacement, encryption, and decryption on their personally identifiable information (PII) data, and other types of data they deem sensitive. With exponential growth of data, companies are handling huge volumes and a wide […]
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platform
This post was co-written with Alcuin Weidus, Principal Architect from GE Aviation. GE Aviation, an operating unit of GE, is a world-leading provider of jet and turboprop engines, as well as integrated systems for commercial, military, business, and general aviation aircraft. GE Aviation has a global service network to support these offerings. From the turbosupercharger […]

Create a serverless event-driven workflow to ingest and process Microsoft data with AWS Glue and Amazon EventBridge
Microsoft SharePoint is a document management system for storing files, organizing documents, and sharing and editing documents in collaboration with others. Your organization may want to ingest SharePoint data into your data lake, combine the SharePoint data with other data that’s available in the data lake, and use it for reporting and analytics purposes. AWS […]

Copy large datasets from Google Cloud Storage to Amazon S3 using Amazon EMR
Data migration between GCS and Amazon S3 is possible by utilizing Hadoop’s native support for S3 object storage and using a Google-provided Hadoop connector for GCS. This post demonstrates how to configure an EMR cluster for DistCp and S3DistCP, goes over the settings and parameters for both tools, performs a copy of a test 9.4 TB dataset, and compares the performance of the copy.
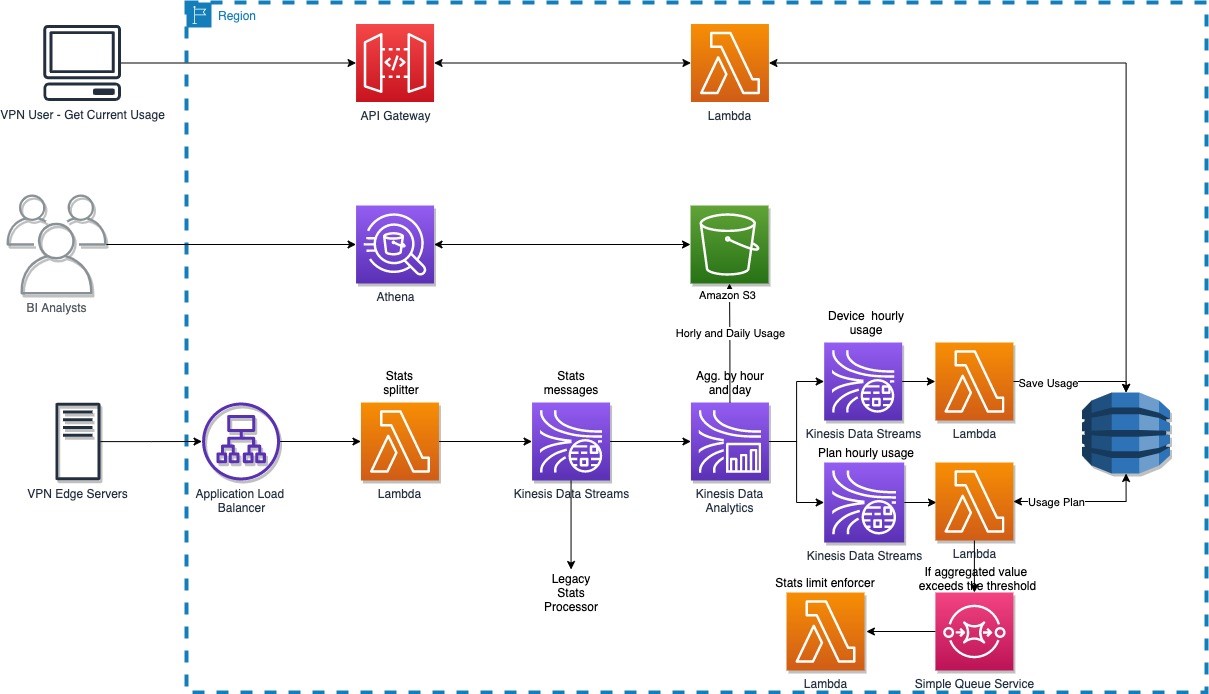
How NortonLifelock built a serverless architecture for real-time analysis of their VPN usage metrics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This post presents a reference architecture and optimization strategies for building serverless data analytics solutions on AWS using Amazon Kinesis Data Analytics. In addition, this post shows […]

Integral Ad Science secures self-service data lake using AWS Lake Formation
This post is co-written with Mat Sharpe, Technical Lead, AWS & Systems Engineering from Integral Ad Science. Integral Ad Science (IAS) is a global leader in digital media quality. The company’s mission is to be the global benchmark for trust and transparency in digital media quality for the world’s leading brands, publishers, and platforms. IAS […]

Create a custom Amazon S3 Storage Lens metrics dashboard using Amazon QuickSight
Companies use Amazon Simple Storage Service (Amazon S3) for its flexibility, durability, scalability, and ability to perform many things besides storing data. This has led to an exponential rise in the usage of S3 buckets across numerous AWS Regions, across tens or even hundreds of AWS accounts. To optimize costs and analyze security posture, Amazon […]

How Comcast uses AWS to rapidly store and analyze large-scale telemetry data
This blog post is co-written by Russell Harlin from Comcast Corporation. Comcast Corporation creates incredible technology and entertainment that connects millions of people to the moments and experiences that matter most. At the core of this is Comcast’s high-speed data network, providing tens of millions of customers across the country with reliable internet connectivity. This […]

How GE Healthcare modernized their data platform using a Lake House Architecture
GE Healthcare (GEHC) operates as a subsidiary of General Electric. The company is headquartered in the US and serves customers in over 160 countries. As a leading global medical technology, diagnostics, and digital solutions innovator, GE Healthcare enables clinicians to make faster, more informed decisions through intelligent devices, data analytics, applications, and services, supported by […]

Create a secure data lake by masking, encrypting data, and enabling fine-grained access with AWS Lake Formation
You can build data lakes with millions of objects on Amazon Simple Storage Service (Amazon S3) and use AWS native analytics and machine learning (ML) services to process, analyze, and extract business insights. You can use a combination of our purpose-built databases and analytics services like Amazon EMR, Amazon OpenSearch Service, and Amazon Redshift as […]