AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)

Orca Security’s journey to a petabyte-scale data lake with Apache Iceberg and AWS Analytics
This post is co-written with Eliad Gat and Oded Lifshiz from Orca Security. With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. One key component that plays a central role in modern data architectures is the data lake, which allows organizations to […]

Migrate data from Google Cloud Storage to Amazon S3 using AWS Glue
Today, we are pleased to announce a new AWS Glue connector for Google Cloud Storage that allows you to move data bi-directionally between Google Cloud Storage and Amazon Simple Storage Service (Amazon S3). In this post, we go over how the new connector works, introduce the connector’s functions, and provide you with key steps to set it up. We provide you with prerequisites, share how to subscribe to this connector in AWS Marketplace, and describe how to create and run AWS Glue for Apache Spark jobs with it.

Get started managing partitions for Amazon S3 tables backed by the AWS Glue Data Catalog
Large organizations processing huge volumes of data usually store it in Amazon Simple Storage Service (Amazon S3) and query the data to make data-driven business decisions using distributed analytics engines such as Amazon Athena. If you simply run queries without considering the optimal data layout on Amazon S3, it results in a high volume of […]

Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 data lakes
Apache Iceberg is an open table format for large datasets in Amazon Simple Storage Service (Amazon S3) and provides fast query performance over large tables, atomic commits, concurrent writes, and SQL-compatible table evolution. When you build your transactional data lake using Apache Iceberg to solve your functional use cases, you need to focus on operational […]

How Zoom implemented streaming log ingestion and efficient GDPR deletes using Apache Hudi on Amazon EMR
In today’s digital age, logging is a critical aspect of application development and management, but efficiently managing logs while complying with data protection regulations can be a significant challenge. Zoom, in collaboration with the AWS Data Lab team, developed an innovative architecture to overcome these challenges and streamline their logging and record deletion processes. In […]
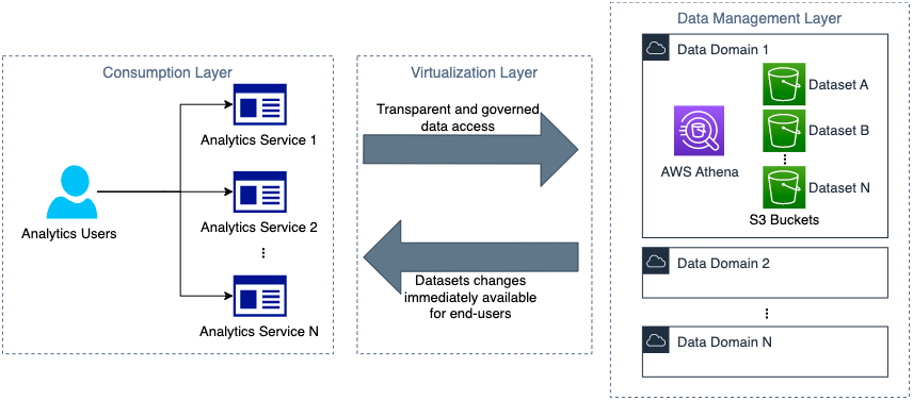
How Novo Nordisk built distributed data governance and control at scale
This is a guest post co-written with Jonatan Selsing and Moses Arthur from Novo Nordisk. This is the second post of a three-part series detailing how Novo Nordisk, a large pharmaceutical enterprise, partnered with AWS Professional Services to build a scalable and secure data and analytics platform. The first post of this series describes the […]

Build event-driven data pipelines using AWS Controllers for Kubernetes and Amazon EMR on EKS
An event-driven architecture is a software design pattern in which decoupled applications can asynchronously publish and subscribe to events via an event broker. By promoting loose coupling between components of a system, an event-driven architecture leads to greater agility and can enable components in the system to scale independently and fail without impacting other services. […]

Simplify data loading into Type 2 slowly changing dimensions in Amazon Redshift
Thousands of customers rely on Amazon Redshift to build data warehouses to accelerate time to insights with fast, simple, and secure analytics at scale and analyze data from terabytes to petabytes by running complex analytical queries. Organizations create data marts, which are subsets of the data warehouse and usually oriented for gaining analytical insights specific […]

Synchronize your Salesforce and Snowflake data to speed up your time to insight with Amazon AppFlow
This post was co-written with Amit Shah, Principal Consultant at Atos. Customers across industries seek meaningful insights from the data captured in their Customer Relationship Management (CRM) systems. To achieve this, they combine their CRM data with a wealth of information already available in their data warehouse, enterprise systems, or other software as a service […]

Analyze Amazon S3 storage costs using AWS Cost and Usage Reports, Amazon S3 Inventory, and Amazon Athena
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating data lakes, serving as object storage for consumer applications, storing logs, and archiving data. As the application portfolio grows, customers tend to store data from multiple application and different business functions […]