AWS Big Data Blog
Category: Open Source

Process millions of observability events with Apache Flink and write directly to Prometheus
In this post, we explain how the new connector works. We also show how you can manage your Prometheus metrics data cardinality by preprocessing raw data with Flink to build real-time observability with Amazon Managed Service for Prometheus and Amazon Managed Grafana.

Deploy real-time analytics with StarTree for managed Apache Pinot on AWS
In this post, we introduce StarTree as a managed solution on AWS for teams seeking the advantages of Pinot. We highlight the key distinctions between open-source Pinot and StarTree, and provide valuable insights for organizations considering a more streamlined approach to their real-time analytics infrastructure.

Build a high-performance quant research platform with Apache Iceberg
In our previous post Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg, we showed how to use Apache Iceberg in the context of strategy backtesting. In this post, we focus on data management implementation options such as accessing data directly in Amazon Simple Storage Service (Amazon S3), using popular data formats like Parquet, or using open table formats like Iceberg. Our experiments are based on real-world historical full order book data, provided by our partner CryptoStruct, and compare the trade-offs between these choices, focusing on performance, cost, and quant developer productivity.

Build a dynamic rules engine with Amazon Managed Service for Apache Flink
This post demonstrates how to implement a dynamic rules engine using Amazon Managed Service for Apache Flink. Our implementation provides the ability to create dynamic rules that can be created and updated without the need to change or redeploy the underlying code or implementation of the rules engine itself. We discuss the architecture, the key services of the implementation, some implementation details that you can use to build your own rules engine, and an AWS Cloud Development Kit (AWS CDK) project to deploy this in your own account.

Build a real-time analytics solution with Apache Pinot on AWS
In this, we will provide a step-by-step guide showing you how you can build a real-time OLAP datastore on Amazon Web Services (AWS) using Apache Pinot on Amazon Elastic Compute Cloud (Amazon EC2) and do near real-time visualization using Tableau. You can use Apache Pinot for batch processing use cases as well but, in this post, we will focus on a near real-time analytics use case.
How Cloudinary transformed their petabyte scale streaming data lake with Apache Iceberg and AWS Analytics
This post is co-written with Amit Gilad, Alex Dickman and Itay Takersman from Cloudinary. Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. Data-driven decisions lead to more effective responses to unexpected events, increase innovation and allow […]

Achieve high availability in Amazon OpenSearch Multi-AZ with Standby enabled domains: A deep dive into failovers
Amazon OpenSearch Service recently introduced Multi-AZ with Standby, a deployment option designed to provide businesses with enhanced availability and consistent performance for critical workloads. With this feature, managed clusters can achieve 99.99% availability while remaining resilient to zonal infrastructure failures. In this post, we explore how search and indexing works with Multi-AZ with Standby and […]

Choosing an open table format for your transactional data lake on AWS
August 2023: This post was updated to include Apache Iceberg support in Amazon Redshift. Disclaimer: Due to rapid advancements in AWS service support for open table formats, recent developments might not yet be reflected in this post. For the latest information on AWS service support for open table formats, refer to the official AWS service […]

Choose the k-NN algorithm for your billion-scale use case with OpenSearch
April 2024: This post was reviewed for accuracy. February 2023: This post was reviewed and updated for accuracy of the code. When organizations set out to build machine learning (ML) applications such as natural language processing (NLP) systems, recommendation engines, or search-based systems, often times k-Nearest Neighbor (k-NN) search will be used at some point […]
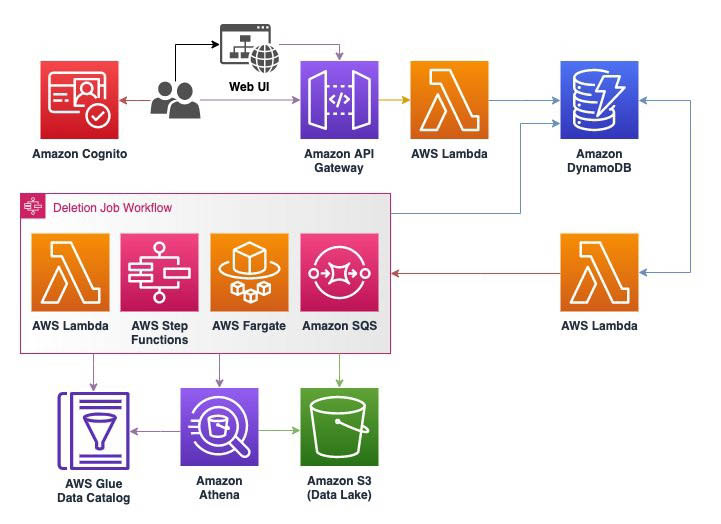
Handling data erasure requests in your data lake with Amazon S3 Find and Forget
February 2024: This post was reviewed and updated for accuracy. Data lakes are a popular choice for organizations to store data around their business activities. Best practice design of data lakes impose that data is immutable once stored, but new regulations such as the European General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), […]