AWS Big Data Blog
Category: Amazon CloudWatch

Push Amazon EMR step logs from Amazon EC2 instances to Amazon CloudWatch logs
Amazon EMR is a big data service offered by AWS to run Apache Spark and other open-source applications on AWS to build scalable data pipelines in a cost-effective manner. Monitoring the logs generated from the jobs deployed on EMR clusters is essential to help detect critical issues in real time and identify root causes quickly. […]

Monitor AWS workloads without a single line of code with Logz.io and Kinesis Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Observability data provides near real-time insights into the health and performance of AWS workloads, so that engineers can quickly address production issues and troubleshoot them before widespread customer impact. As AWS workloads […]

Use AWS CloudWatch as a destination for Amazon Redshift Audit logs
Amazon Redshift is a fast, scalable, secure, and fully-managed cloud data warehouse that makes it simple and cost-effective to analyze all of your data using standard SQL. Amazon Redshift has comprehensive security capabilities to satisfy the most demanding requirements. To help you to monitor the database for security and troubleshooting purposes, Amazon Redshift logs information […]

Monitor your Amazon QuickSight deployments using the new Amazon CloudWatch integration
Amazon QuickSight is a fully-managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards, and share these with tens of thousands of users, either within the QuickSight interface or embedded in software as a service (SaaS) applications or web portals. With QuickSight providing insights to power your […]

Gain insights into your Amazon Kinesis Data Firehose delivery stream using Amazon CloudWatch
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. The volume of data being generated globally is growing at an ever-increasing pace. Data is generated to support an increasing number of use cases, such as IoT, advertisement, gaming, security monitoring, machine […]
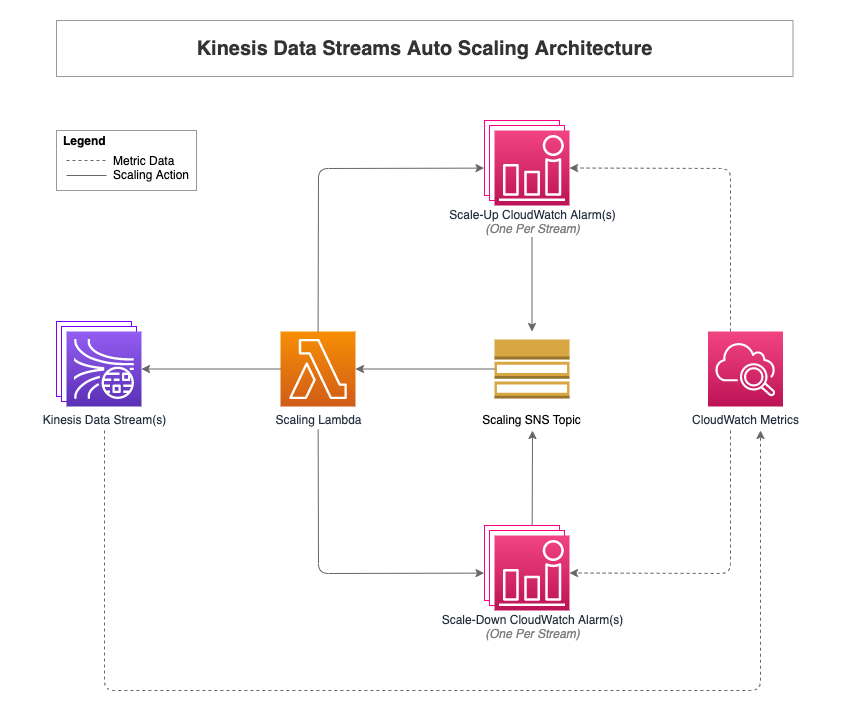
Auto scaling Amazon Kinesis Data Streams using Amazon CloudWatch and AWS Lambda
This post is co-written with Noah Mundahl, Director of Public Cloud Engineering at United Health Group. Update (12/1/2021): Amazon Kinesis Data Streams On-Demand mode is now the recommended way to natively auto scale your Amazon Kinesis Data Streams. In this post, we cover a solution to add auto scaling to Amazon Kinesis Data Streams. Whether […]
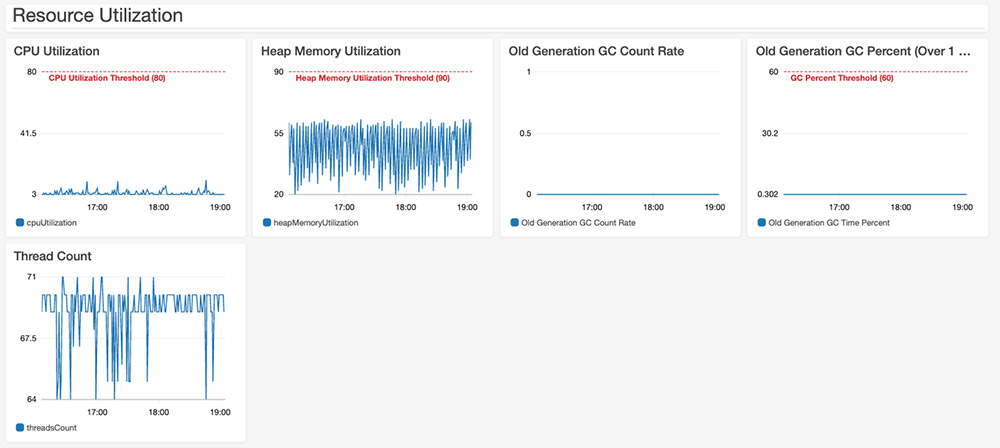
Enhanced monitoring and automatic scaling for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Thousands of developers use Apache Flink to build streaming applications to transform and analyze data in real time. Apache Flink is an open-source framework and engine for […]
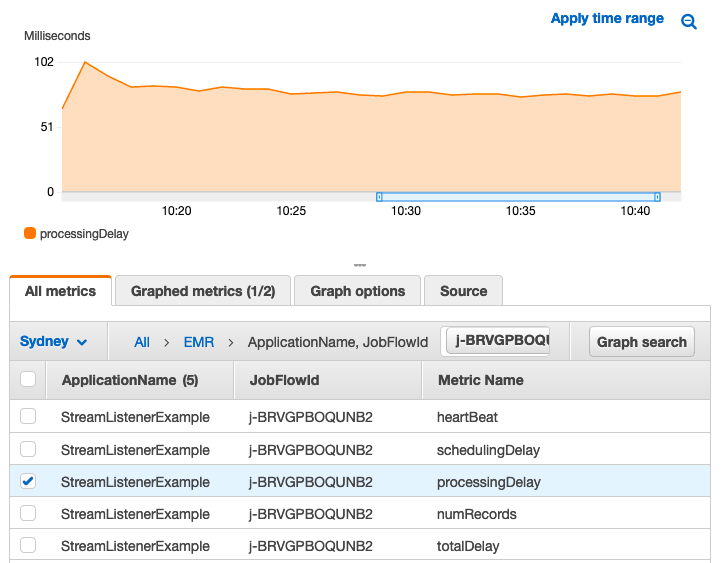
Monitor Spark streaming applications on Amazon EMR
This post demonstrates how to implement a simple SparkListener, monitor and observe Spark streaming applications, and set up some alerts. The post also shows how to use alerts to set up automatic scaling on Amazon EMR clusters, based on your CloudWatch custom metrics.

Optimize Amazon EMR costs with idle checks and automatic resource termination using advanced Amazon CloudWatch metrics and AWS Lambda
Many customers use Amazon EMR to run big data workloads, such as Apache Spark and Apache Hive queries, in their development environment. Data analysts and data scientists frequently use these types of clusters, known as analytics EMR clusters. Users often forget to terminate the clusters after their work is done. This leads to idle running […]

Build and automate a serverless data lake using an AWS Glue trigger for the Data Catalog and ETL jobs
September 2022: This post was reviewed and updated with latest screenshots and instructions. Today, data is flowing from everywhere, whether it is unstructured data from resources like IoT sensors, application logs, and clickstreams, or structured data from transaction applications, relational databases, and spreadsheets. Data has become a crucial part of every business. This has resulted […]