AWS Big Data Blog
Category: Learning Levels

Build an end-to-end change data capture with Amazon MSK Connect and AWS Glue Schema Registry
The value of data is time sensitive. Real-time processing makes data-driven decisions accurate and actionable in seconds or minutes instead of hours or days. Change data capture (CDC) refers to the process of identifying and capturing changes made to data in a database and then delivering those changes in real time to a downstream system. […]

How gaming companies can use Amazon Redshift Serverless to build scalable analytical applications faster and easier
This post provides guidance on how to build scalable analytical solutions for gaming industry use cases using Amazon Redshift Serverless. It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. This post […]

Improve productivity by using keyboard shortcuts in Amazon Athena query editor
Amazon Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open-table and file formats. Athena provides a simplified, flexible way to analyze petabytes of data where it lives. You can analyze data or build applications from an Amazon Simple Storage Service (Amazon S3) data lake and over 25 data sources, including on-premises […]

Build incremental data pipelines to load transactional data changes using AWS DMS, Delta 2.0, and Amazon EMR Serverless
Building data lakes from continuously changing transactional data of databases and keeping data lakes up to date is a complex task and can be an operational challenge. A solution to this problem is to use AWS Database Migration Service (AWS DMS) for migrating historical and real-time transactional data into the data lake. You can then […]

Access Amazon Athena in your applications using the WebSocket API
In this post, we present a solution that can integrate with your front-end application to query data from Amazon S3 using an Athena synchronous API invocation. With this solution, you can add a layer of abstraction to your application on direct Athena API calls and promote the access using the WebSocket API developed with Amazon API Gateway. The query results are returned back to the application as Amazon S3 presigned URLs.

Use Apache Iceberg in a data lake to support incremental data processing
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. It adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. Iceberg has […]
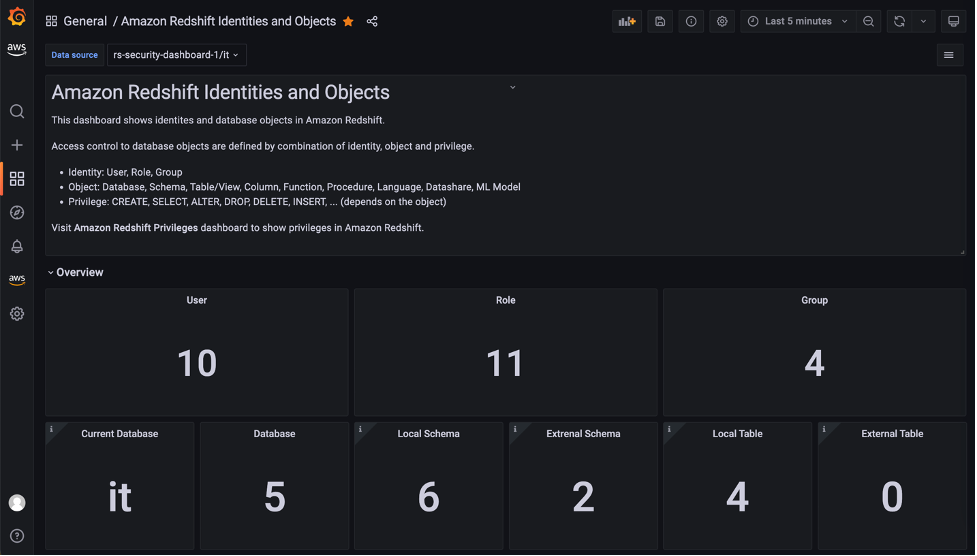
Visualize database privileges on Amazon Redshift using Grafana
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift enables you to use SQL for analyzing structured and semi-structured data with best price performance along with secure access to the data. As more users start querying data in a data warehouse, access control is paramount to protect valuable organizational […]

Build a semantic search engine for tabular columns with Transformers and Amazon OpenSearch Service
Finding similar columns in a data lake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. The inability to accurately find and analyze data from disparate sources represents a potential efficiency killer for everyone from data scientists, medical researchers, academics, to financial and government analysts. Conventional […]

Enhance operational insights for Amazon MSK using Amazon Managed Service for Prometheus and Amazon Managed Grafana
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is an event streaming platform that you can use to build asynchronous applications by decoupling producers and consumers. Monitoring of different Amazon MSK metrics is critical for efficient operations of production workloads. Amazon MSK gathers Apache Kafka metrics and sends them to Amazon CloudWatch, where you can […]

Reduce Amazon EMR cluster costs by up to 19% with new enhancements in Amazon EMR Managed Scaling
In June 2020, AWS announced the general availability of Amazon EMR Managed Scaling. With EMR Managed Scaling, you specify the minimum and maximum compute limits for your clusters, and Amazon EMR automatically resizes your cluster for optimal performance and resource utilization. EMR Managed Scaling constantly monitors key workload-related metrics and uses an algorithm that optimizes the […]