AWS Big Data Blog
Category: Learning Levels

Top strategies for high volume tracing with Amazon OpenSearch Ingestion
Amazon OpenSearch Ingestion is a serverless, auto-scaled, managed data collector that receives, transforms, and delivers data to Amazon OpenSearch Service domains or Amazon OpenSearch Serverless collections. OpenSearch Ingestion is powered by Data Prepper, an open-source, streaming ETL (extract, transform, and load) solution that’s part of the OpenSearch project. When you use OpenSearch Ingestion, you don’t […]

Perform upserts in a data lake using Amazon Athena and Apache Iceberg
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your data lake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable). Apache Iceberg is an open table format for data lakes that manages large collections of files as […]

Working with percolators in Amazon OpenSearch Service
Amazon OpenSearch Service is a managed service that makes it easy to secure, deploy, and operate OpenSearch and legacy Elasticsearch clusters at scale in the AWS Cloud. Amazon OpenSearch Service provisions all the resources for your cluster, launches it, and automatically detects and replaces failed nodes, reducing the overhead of self-managed infrastructures. The service makes it […]

How Dafiti made Amazon QuickSight its primary data visualization tool
This is a guest post by Valdiney Gomes, Hélio Leal, and Flávia Lima from Dafiti. Data and its various uses is increasingly evident in companies, and each professional has their preferences about which technologies to use to visualize data, which isn’t necessarily in line with the technological needs and infrastructure of a company. At Dafiti, […]

Cross-account integration between SaaS platforms using Amazon AppFlow
Implementing an effective data sharing strategy that satisfies compliance and regulatory requirements is complex. Customers often need to share data between disparate software as a service (SaaS) platforms within their organization or across organizations. On many occasions, they need to apply business logic to the data received from the source SaaS platform before pushing it […]
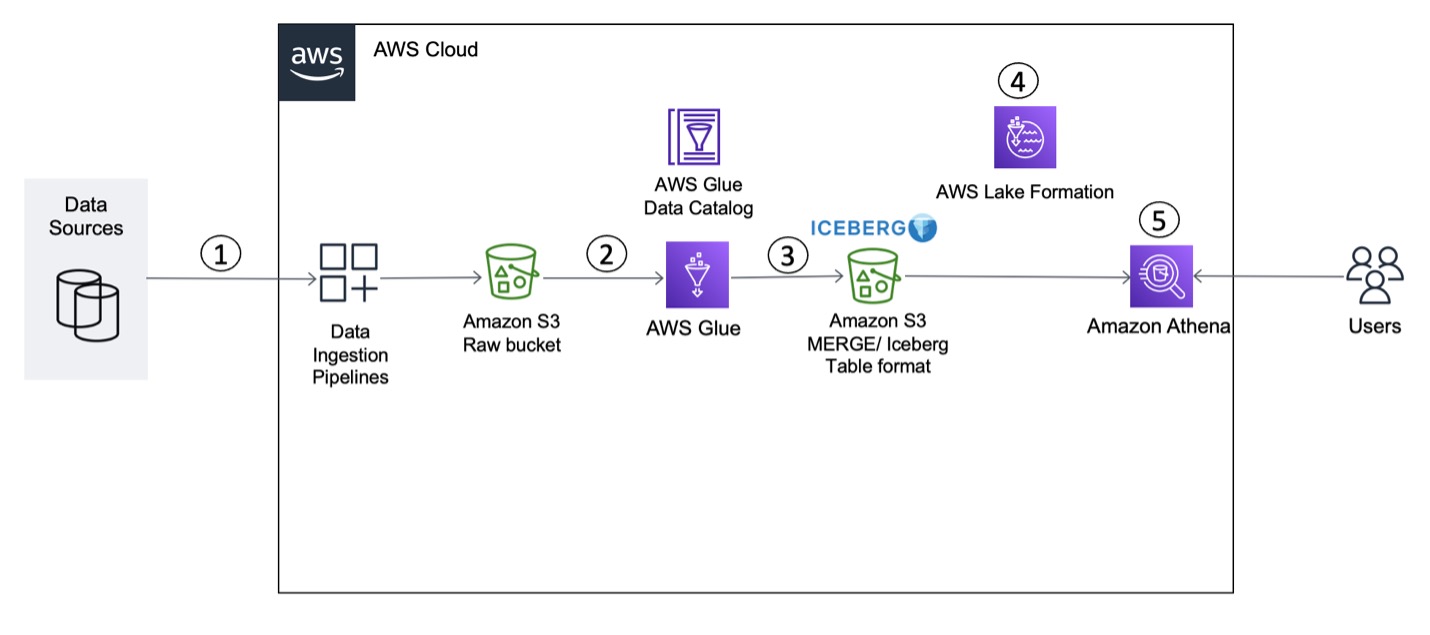
Build a transactional data lake using Apache Iceberg, AWS Glue, and cross-account data shares using AWS Lake Formation and Amazon Athena
Building a data lake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. It allows you to access diverse data sources, build business intelligence dashboards, build AI and machine learning (ML) models to provide customized customer experiences, and accelerate the curation of new datasets for consumption by adopting a modern data […]

Simplify and speed up Apache Spark applications on Amazon Redshift data with Amazon Redshift integration for Apache Spark
Customers use Amazon Redshift to run their business-critical analytics on petabytes of structured and semi-structured data. Apache Spark is a popular framework that you can use to build applications for use cases such as ETL (extract, transform, and load), interactive analytics, and machine learning (ML). Apache Spark enables you to build applications in a variety […]

Exploring new ETL and ELT capabilities for Amazon Redshift from the AWS Glue Studio visual editor
In a modern data architecture, unified analytics enable you to access the data you need, whether it’s stored in a data lake or a data warehouse. In particular, we have observed an increasing number of customers who combine and integrate their data into an Amazon Redshift data warehouse to analyze huge data at scale and […]

Automate discovery of data relationships using ML and Amazon Neptune graph technology
Data mesh is a new approach to data management. Companies across industries are using a data mesh to decentralize data management to improve data agility and get value from data. However, when a data producer shares data products on a data mesh self-serve web portal, it’s neither intuitive nor easy for a data consumer to […]

Accelerate HiveQL with Oozie to Spark SQL migration on Amazon EMR
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a data warehouse on Hadoop. Apache Hive has performed pretty well for a long time. But with advancements in infrastructure such as cloud computing and multicore machines with large RAM, Apache Spark started to gain visibility by […]