AWS Big Data Blog
Category: Intermediate (200)

Amazon MSK now provides up to 29% more throughput and up to 24% lower costs with AWS Graviton3 support
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that enables you to build and run applications that use Apache Kafka to process streaming data. Today, we’re excited to bring the benefits of Graviton3 to Kafka workloads, with Amazon MSK now offering M7g instances for new MSK provisioned clusters. AWS Graviton […]

Enhance query performance using AWS Glue Data Catalog column-level statistics
Today, we’re making available a new capability of AWS Glue Data Catalog that allows generating column-level statistics for AWS Glue tables. These statistics are now integrated with the cost-based optimizers (CBO) of Amazon Athena and Amazon Redshift Spectrum, resulting in improved query performance and potential cost savings. Data lakes are designed for storing vast amounts […]

Enhance monitoring and debugging for AWS Glue jobs using new job observability metrics
For any modern data-driven company, having smooth data integration pipelines is crucial. These pipelines pull data from various sources, transform it, and load it into destination systems for analytics and reporting. When running properly, it provides timely and trustworthy information. However, without vigilance, the varying data volumes, characteristics, and application behavior can cause data pipelines […]

Introducing AWS Glue serverless Spark UI for better monitoring and troubleshooting
Today, we are pleased to announce serverless Spark UI built into the AWS Glue console. You can now use Spark UI easily as it’s a built-in component of the AWS Glue console, enabling you to access it with a single click when examining the details of any given job run. There’s no infrastructure setup or teardown required. AWS Glue serverless Spark UI is a fully-managed serverless offering and generally starts up in a matter of seconds. Serverless Spark UI makes it significantly faster and easier to get jobs working in production because you have ready access to low level details for your job runs.

Speed up queries with the cost-based optimizer in Amazon Athena
Amazon Athena is a serverless, interactive analytics service built on open source frameworks, supporting open table file formats. Athena provides a simplified, flexible way to analyze petabytes of data where it lives. You can analyze data or build applications from an Amazon Simple Storage Service (Amazon S3) data lake and 30 data sources, including on-premises […]

Decentralize LF-tag management with AWS Lake Formation
In today’s data-driven world, organizations face unprecedented challenges in managing and extracting valuable insights from their ever-expanding data ecosystems. As the number of data assets and users grow, the traditional approaches to data management and governance are no longer sufficient. Customers are now building more advanced architectures to decentralize permissions management to allow for individual […]
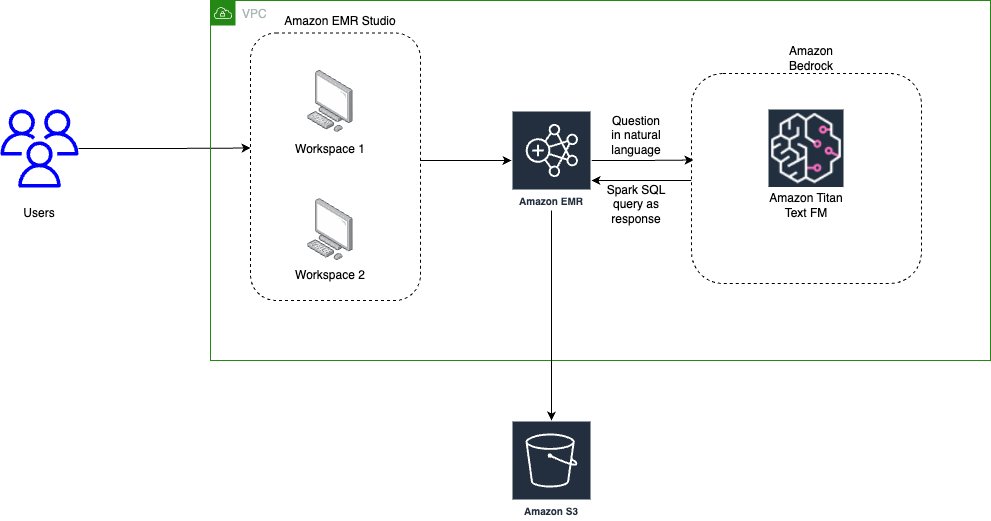
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently. Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine […]

Introducing shared VPC support on Amazon MWAA
In this post, we demonstrate automating deployment of Amazon Managed Workflows for Apache Airflow (Amazon MWAA) using customer-managed endpoints in a VPC, providing compatibility with shared, or otherwise restricted, VPCs. Data scientists and engineers have made Apache Airflow a leading open source tool to create data pipelines due to its active open source community, familiar […]

Configure dynamic tenancy for Amazon OpenSearch Dashboards
Amazon OpenSearch Service securely unlocks real-time search, monitoring, and analysis of business and operational data for use cases like application monitoring, log analytics, observability, and website search. In this post, we talk about new configurable dashboards tenant properties. OpenSearch Dashboards tenants in Amazon OpenSearch Service are spaces for saving index patterns, visualizations, dashboards, and other […]
Introducing Amazon MWAA support for Apache Airflow version 2.7.2 and deferrable operators
Today, we are announcing the availability of Apache Airflow version 2.7.2 environments and support for deferrable operators on Amazon MWAA. In this post, we provide an overview of deferrable operators and triggers, including a walkthrough of an example showcasing how to use them. We also delve into some of the new features and capabilities of Apache Airflow, and how you can set up or upgrade your Amazon MWAA environment to version 2.7.2.