AWS Big Data Blog
Category: Database

Query cross-account Amazon DynamoDB tables using Amazon Athena Federated Query
Amazon DynamoDB is ideal for applications that need a flexible NoSQL database with low read and write latencies and the ability to scale storage and throughput up or down as needed without code changes or downtime. You can use DynamoDB for use cases including mobile apps, gaming, digital ad serving, live voting, audience interaction for live […]

Run queries concurrently and see query history using Amazon Redshift Query Editor v2
Amazon Redshift is a fast, fully managed, petabyte-scale cloud data warehouse. You have the flexibility to choose from provisioned and serverless compute modes. You can start loading and querying large datasets conveniently in Amazon Redshift using Amazon Redshift Query Editor v2, a web-based SQL client application. Query Editor v2 empowers your technical and business teams […]

How SOCAR built a streaming data pipeline to process IoT data for real-time analytics and control
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. SOCAR is the leading Korean mobility company with strong competitiveness in car-sharing. SOCAR has become a comprehensive mobility platform in collaboration with Nine2One, an e-bike sharing service, […]

How a blockchain startup built a prototype solution to solve the need of analytics for decentralized applications with AWS Data Lab
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This post is co-written with Dr. Quan Hoang Nguyen, CTO at Fantom Foundation. Here at Fantom Foundation (Fantom), we have developed a high performance, highly scalable, and secure smart contract platform. It’s […]

Automate data archival for Amazon Redshift time series tables
Amazon Redshift is a fast, petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all of your data using standard SQL. Tens of thousands of customers today rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the most widely used cloud data warehouse. You can […]

Automate ETL jobs between Amazon RDS for SQL Server and Azure Managed SQL using AWS Glue Studio
Nowadays many customers are following a multi-cloud strategy. They might choose to use various cloud-managed services, such as Amazon Relational Database Service (Amazon RDS) for SQL Server and Azure SQL Managed Instances, to perform data analytics tasks, but still use traditional extract, transform, and load (ETL) tools to integrate and process the data. However, traditional ETL tools may […]

How ZS created a multi-tenant self-service data orchestration platform using Amazon MWAA
This is post is co-authored by Manish Mehra, Anirudh Vohra, Sidrah Sayyad, and Abhishek I S (from ZS), and Parnab Basak (from AWS). The team at ZS collaborated closely with AWS to build a modern, cloud-native data orchestration platform. ZS is a management consulting and technology firm focused on transforming global healthcare and beyond. We […]

Convert Oracle XML BLOB data using Amazon EMR and load to Amazon Redshift
In legacy relational database management systems, data is stored in several complex data types, such XML, JSON, BLOB, or CLOB. This data might contain valuable information that is often difficult to transform into insights, so you might be looking for ways to load and use this data in a modern cloud data warehouse such as […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]
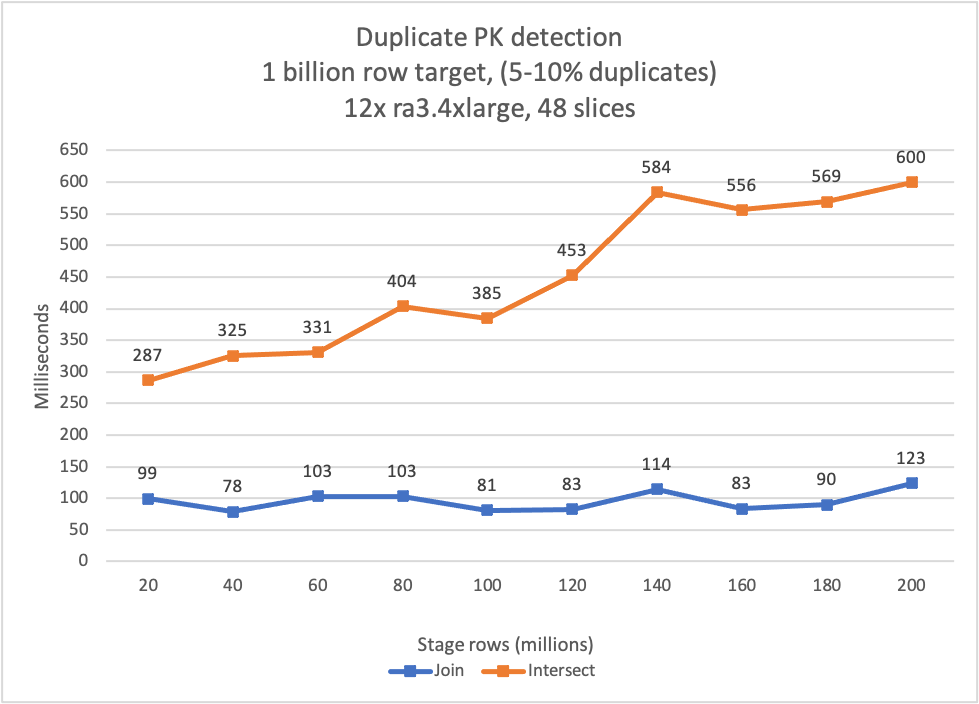
Accelerate your data warehouse migration to Amazon Redshift – Part 6
This is the sixth in a series of posts. We’re excited to share dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially simplify your migrations from legacy data warehouses to Amazon Redshift. Check out all the previous posts in this series: […]