AWS Big Data Blog
Category: Database

Join a streaming data source with CDC data for real-time serverless data analytics using AWS Glue, AWS DMS, and Amazon DynamoDB
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, data lakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets. Data lakes are not transactional by default; however, there […]
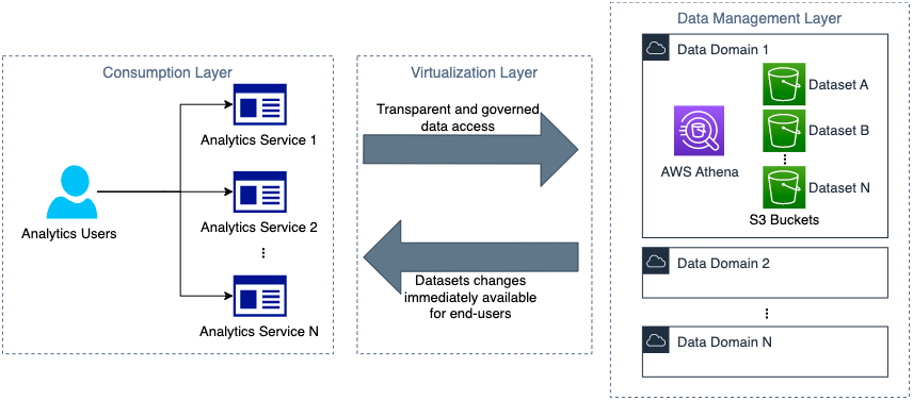
How Novo Nordisk built distributed data governance and control at scale
This is a guest post co-written with Jonatan Selsing and Moses Arthur from Novo Nordisk. This is the second post of a three-part series detailing how Novo Nordisk, a large pharmaceutical enterprise, partnered with AWS Professional Services to build a scalable and secure data and analytics platform. The first post of this series describes the […]

How Huron built an Amazon QuickSight Asset Catalogue with AWS CDK Based Deployment Pipeline
This is a guest blog post co-written with Corey Johnson from Huron. Having an accurate and up-to-date inventory of all technical assets helps an organization ensure it can keep track of all its resources with metadata information such as their assigned owners, last updated date, used by whom, how frequently, and more. It helps engineers, […]

Simplify and speed up Apache Spark applications on Amazon Redshift data with Amazon Redshift integration for Apache Spark
Customers use Amazon Redshift to run their business-critical analytics on petabytes of structured and semi-structured data. Apache Spark is a popular framework that you can use to build applications for use cases such as ETL (extract, transform, and load), interactive analytics, and machine learning (ML). Apache Spark enables you to build applications in a variety […]

Automate discovery of data relationships using ML and Amazon Neptune graph technology
Data mesh is a new approach to data management. Companies across industries are using a data mesh to decentralize data management to improve data agility and get value from data. However, when a data producer shares data products on a data mesh self-serve web portal, it’s neither intuitive nor easy for a data consumer to […]

Accelerate HiveQL with Oozie to Spark SQL migration on Amazon EMR
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a data warehouse on Hadoop. Apache Hive has performed pretty well for a long time. But with advancements in infrastructure such as cloud computing and multicore machines with large RAM, Apache Spark started to gain visibility by […]

Reference guide to build inventory management and forecasting solutions on AWS
Inventory management is a critical function for any business that deals with physical products. The primary challenge businesses face with inventory management is balancing the cost of holding inventory with the need to ensure that products are available when customers demand them. The consequences of poor inventory management can be severe. Overstocking can lead to […]

How AWS Payments migrated from Redash to Amazon Redshift Query Editor v2
AWS Payments is part of the AWS Commerce Platform (CP) organization that owns the customer experience of paying AWS invoices. It helps AWS customers manage their payment methods and payment preferences, and helps customers make self-service payments to AWS. The Machine Learning, Data and Analytics (MLDA) team at AWS Payments enables data-driven decision-making across payments […]

How Tricentis unlocks insights across the software development lifecycle at speed and scale using Amazon Redshift
This is a guest post co-written with Parag Doshi, Guru Havanur, and Simon Guindon from Tricentis. Tricentis is a global leader in continuous testing for DevOps, cloud, and enterprise applications. It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more […]

Migrate Google BigQuery to Amazon Redshift using AWS Schema Conversion tool (SCT)
Amazon Redshift is a fast, fully-managed, petabyte scale data warehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. Using Amazon Redshift Serverless and Query Editor v2, you can load and query large datasets in just a few clicks and pay only for what you use. The decoupled compute and […]