AWS Big Data Blog
Category: Database

Amazon Redshift Engineering’s Advanced Table Design Playbook: Table Data Durability
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings Part 5: Table Data Durability (Translated into Japanese) In the fifth and final installment of the Advanced Table Design Playbook, I’ll discuss how to use two simple table durability properties to […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Compression Encodings
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings (Translated into Japanese) Part 5: Table Data Durability In part 4 of this blog series, I’ll be discussing when and when not to apply column encoding for compression, methods for determining ideal […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Compound and Interleaved Sort Keys
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys (Translated into Japanese) Part 4: Compression Encodings Part 5: Table Data Durability In this installment, I’ll cover different sort key options, when to use sort keys, and how to identify the most optimal sort key […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Distribution Styles and Distribution Keys
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys (Translated into Japanese) Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings Part 5: Table Data Durability The first table and column properties we discuss in this blog series are table distribution styles (DISTSTYLE) and distribution keys (DISTKEY). This blog […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Preamble, Prerequisites, and Prioritization
Part 1: Preamble, Prerequisites, and Prioritization (Translated into Japanese) Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings Part 5: Table Data Durability Amazon Redshift is a fully managed, petabyte scale, massively parallel data warehouse that offers simple operations and high performance. AWS customers use Amazon […]

Using pgpool and Amazon ElastiCache for Query Caching with Amazon Redshift
In this blog post, we’ll use a real customer scenario to show you how to create a caching layer in front of Amazon Redshift using pgpool and Amazon ElastiCache.
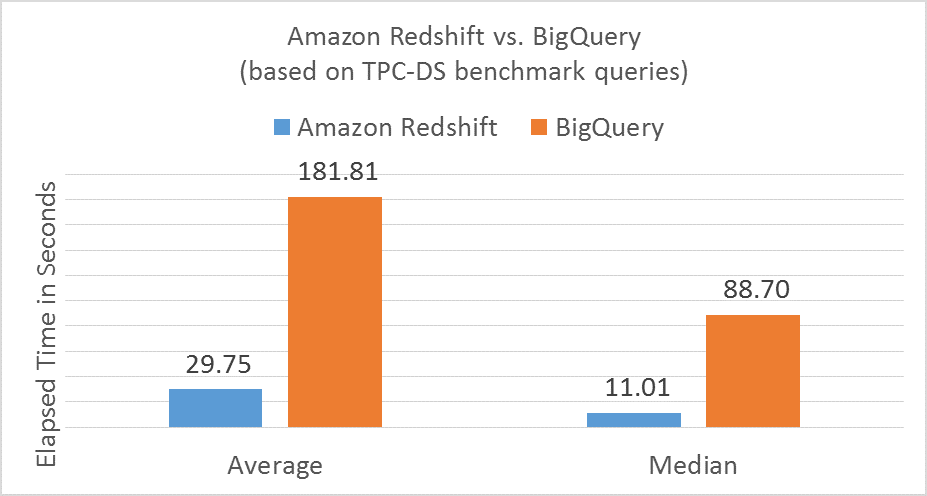
Fact or Fiction: Google BigQuery Outperforms Amazon Redshift as an Enterprise Data Warehouse?
Publishing misleading performance benchmarks is a classic old guard marketing tactic. It’s not surprising to see old guard companies (like Oracle) doing this, but we were kind of surprised to see Google take this approach, too. So, when Google presented their BigQuery vs. Amazon Redshift benchmark results at a private event in San Francisco on September 29, 2016, it piqued our interest and we decided to dig deeper.

Amazon EMR-DynamoDB Connector Repository on AWSLabs GitHub
Amazon Web Services is excited to announce that the Amazon EMR-DynamoDB Connector is now open-source. The code you see in the GitHub repository is exactly what is available on your EMR cluster, making it easier to build applications with this component.

Monitor Your Application for Processing DynamoDB Streams
In this post, I suggest ways you can monitor the Amazon Kinesis Client Library (KCL) application you use to process DynamoDB Streams to quickly track and resolve issues or failures so you can avoid losing data. Dashboards, metrics, and application logs all play a part. This post may be most relevant to Java applications running on Amazon EC2 instances.

Process Large DynamoDB Streams Using Multiple Amazon Kinesis Client Library (KCL) Workers
Asmita Barve-Karandikar is an SDE with DynamoDB Introduction Imagine you own a popular mobile health app, with millions of users worldwide, that continuously records new information. It sends over one million updates per second to its master data store and needs the updates to be relayed to various replicas across different regions in real time. […]