AWS Big Data Blog
Category: Database
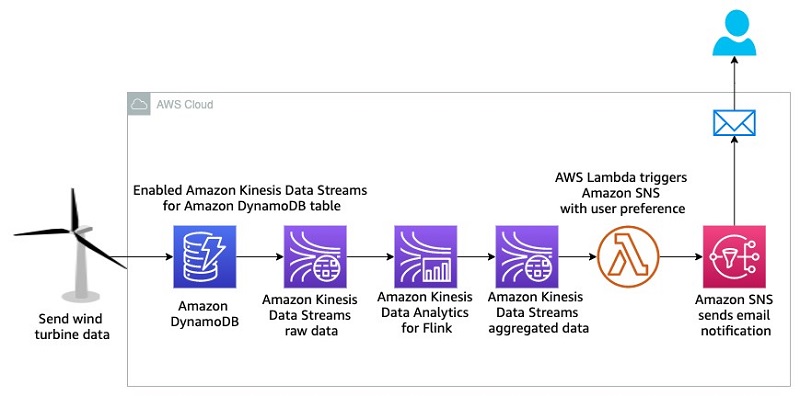
Building a real-time notification system with Amazon Kinesis Data Streams for Amazon DynamoDB and Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon DynamoDB helps you capture high-velocity data such as clickstream data to form customized user profiles and Internet of Things (IoT) data so that you can develop […]
Dream11’s journey to building their Data Highway on AWS
This is a guest post co-authored by Pradip Thoke of Dream11. In their own words, “Dream11, the flagship brand of Dream Sports, is India’s biggest fantasy sports platform, with more than 100 million users. We have infused the latest technologies of analytics, machine learning, social networks, and media technologies to enhance our users’ experience. Dream11 […]

Sharing Amazon Redshift data securely across Amazon Redshift clusters for workload isolation
Amazon Redshift data sharing allows for a secure and easy way to share live data for read purposes across Amazon Redshift clusters. Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. It allows […]

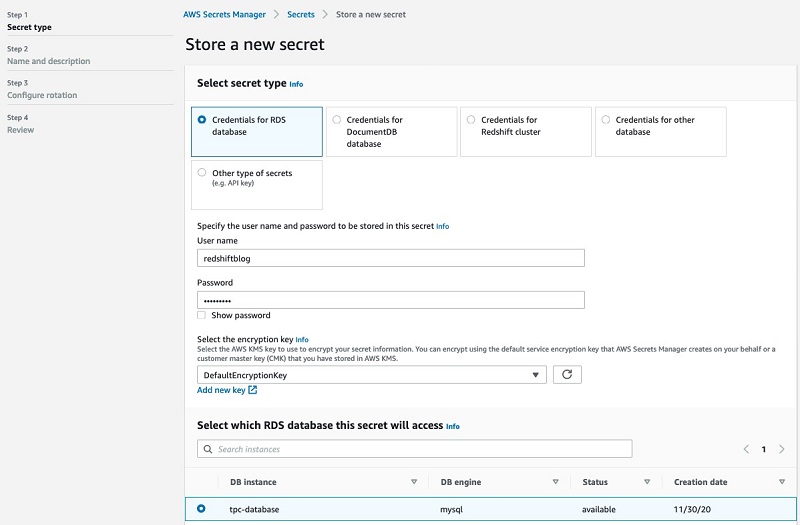
Accelerating Amazon Redshift federated query to Amazon Aurora MySQL with AWS CloudFormation
Amazon Redshift federated query allows you to combine data from one or more Amazon Relational Database Service (Amazon RDS) for MySQL and Amazon Aurora MySQL databases with data already in Amazon Redshift. You can also combine such data with data in an Amazon Simple Storage Service (Amazon S3) data lake. This post shows you how […]
Announcing Amazon Redshift federated querying to Amazon Aurora MySQL and Amazon RDS for MySQL
Since we launched Amazon Redshift as a cloud data warehouse service more than seven years ago, tens of thousands of customers have built analytics workloads using it. We’re always listening to your feedback and, in April 2020, we announced general availability for federated querying to Amazon Aurora PostgreSQL and Amazon Relational Database Service (Amazon RDS) […]

Bringing machine learning to more builders through databases and analytics services
Machine learning (ML) is becoming more mainstream, but even with the increasing adoption, it’s still in its infancy. For ML to have the broad impact that we think it can have, it has to get easier to do and easier to apply. We launched Amazon SageMaker in 2017 to remove the challenges from each stage […]

Accessing and visualizing external tables in an Apache Hive metastore with Amazon Athena and Amazon QuickSight
Many organizations have an Apache Hive metastore that stores the schemas for their data lake. You can use Amazon Athena due to its serverless nature; Athena makes it easy for anyone with SQL skills to quickly analyze large-scale datasets. You may also want to reliably query the rich datasets in the lake, with their schemas […]

Detect change points in your event data stream using Amazon Kinesis Data Streams, Amazon DynamoDB and AWS Lambda
The success of many modern streaming applications depends on the ability to sequentially detect each change as soon as possible after it occurs, while continuing to monitor the data stream as it evolves. Applications of change point detection range across genomics, marketing, and finance, to name a few. In genomics, change point detection can help […]

Creating a source to Lakehouse data replication pipe using Apache Hudi, AWS Glue, AWS DMS, and Amazon Redshift
February 2021 update – Please refer to the post Writing to Apache Hudi tables using AWS Glue Custom Connector to learn about an easier mechanism to write to Hudi tables using AWS Glue Custom Connector. In this post, we include the modified Apache Hudi JARs as an external dependency. The AWS Glue Custom Connector feature […]

Accessing external components using Amazon Redshift Lambda UDFs
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse. It makes it simple and cost-effective to analyze all your data using standard SQL, your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day […]