AWS Big Data Blog
Category: Amazon Redshift
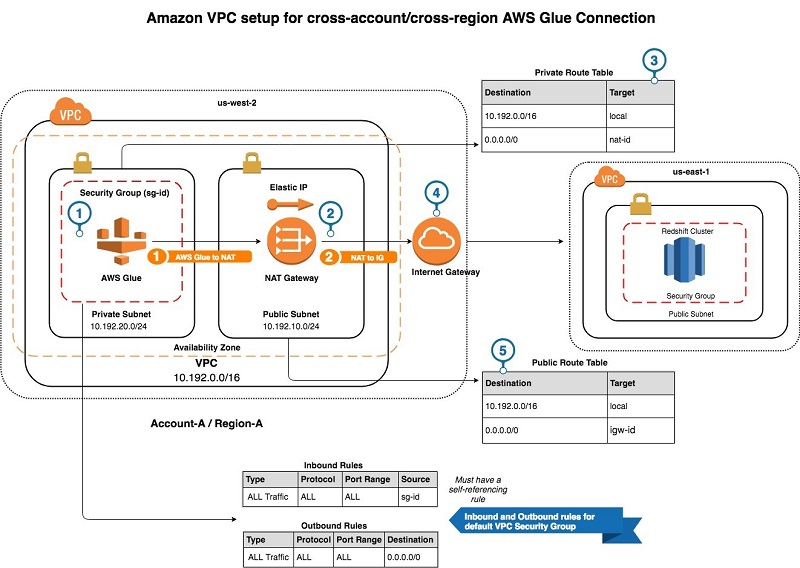
Create cross-account and cross-region AWS Glue connections
In this blog post, we describe how to configure the networking routes and interfaces to give AWS Glue access to a data store in an AWS Region different from the one with your AWS Glue resources. In our example, we connect AWS Glue, located in Region A, to an Amazon Redshift data warehouse located in Region B.
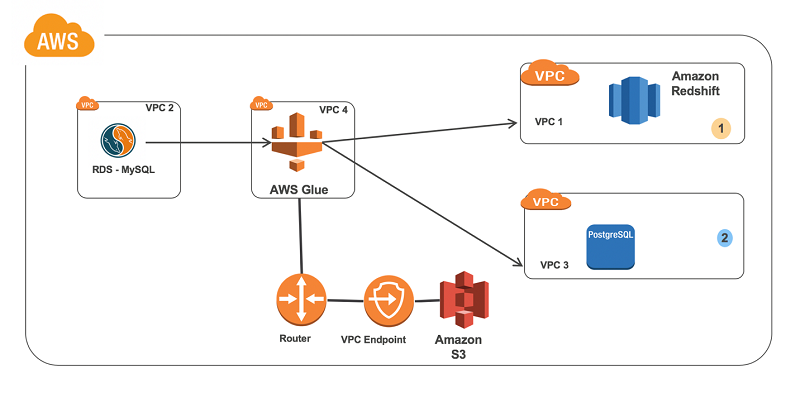
Connect to and run ETL jobs across multiple VPCs using a dedicated AWS Glue VPC
In this blog post, we’ll go through the steps needed to build an ETL pipeline that consumes from one source in one VPC and outputs it to another source in a different VPC. We’ll set up in multiple VPCs to reproduce a situation where your database instances are in multiple VPCs for isolation related to security, audit, or other purposes.

Chasing earthquakes: How to prepare an unstructured dataset for visualization via ETL processing with Amazon Redshift
As organizations expand analytics practices and hire data scientists and other specialized roles, big data pipelines are growing increasingly complex. Sophisticated models are being built using the troves of data being collected every second. The bottleneck today is often not the know-how of analytical techniques. Rather, it’s the difficulty of building and maintaining ETL (extract, transform, and load) jobs using tools that might be unsuitable for the cloud. In this post, I demonstrate a solution to this challenge.
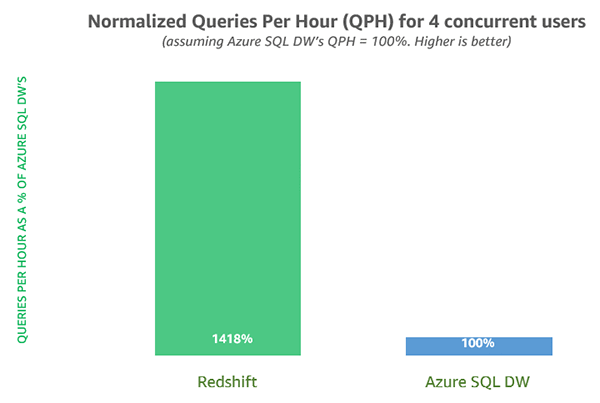
Performance matters: Amazon Redshift is now up to 3.5x faster for real-world workloads
Since we launched Amazon Redshift, thousands of customers have trusted us to get uncompromising speed for their most complex analytical workloads. Over the course of 2017, our customers benefited from a 3x to 5x performance gain, resulting from short query acceleration, result caching, late materialization, and many other under-the-hood improvements. In this post, we highlight […]
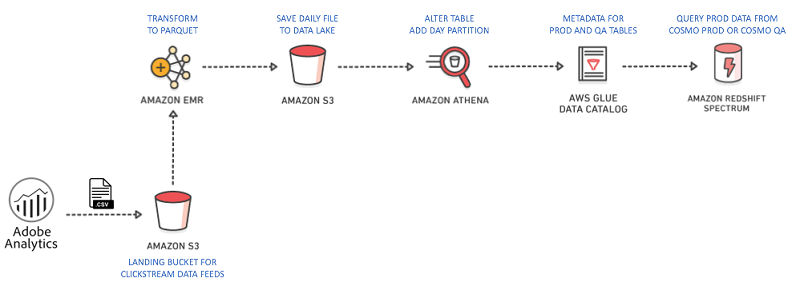
Close the customer journey loop with Amazon Redshift at Equinox Fitness Clubs
Clickstream analysis tools handle their data well, and some even have impressive BI interfaces. However, analyzing clickstream data in isolation comes with many limitations. For example, a customer is interested in a product or service on your website. They go to your physical store to purchase it. The clickstream analyst asks, “What happened after they […]
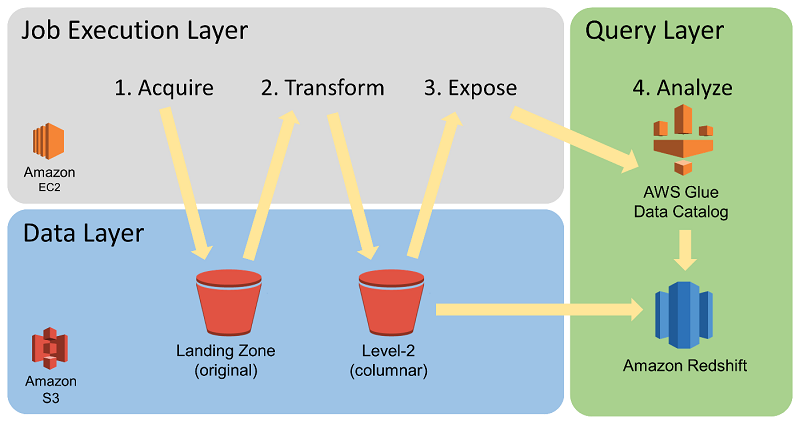
How Annalect built an event log data analytics solution using Amazon Redshift
By establishing a data warehouse strategy using Amazon S3 for storage and Redshift Spectrum for analytics, we increased the size of the datasets we support by over an order of magnitude. In addition, we improved our ability to ingest large volumes of data quickly, and maintained fast performance without increasing our costs. Our analysts and modelers can now perform deeper analytics to improve ad buying strategies and results.

Narrativ is helping producers monetize their digital content with Amazon Redshift
Narrativ, in their own words: Narrativ is building monetization technology for the next generation of digital content producers. Our product portfolio includes a real-time bidding platform and visual storytelling tools that together generate millions of dollars of advertiser value and billions of data points each month. At Narrativ, we have seen massive growth in our […]
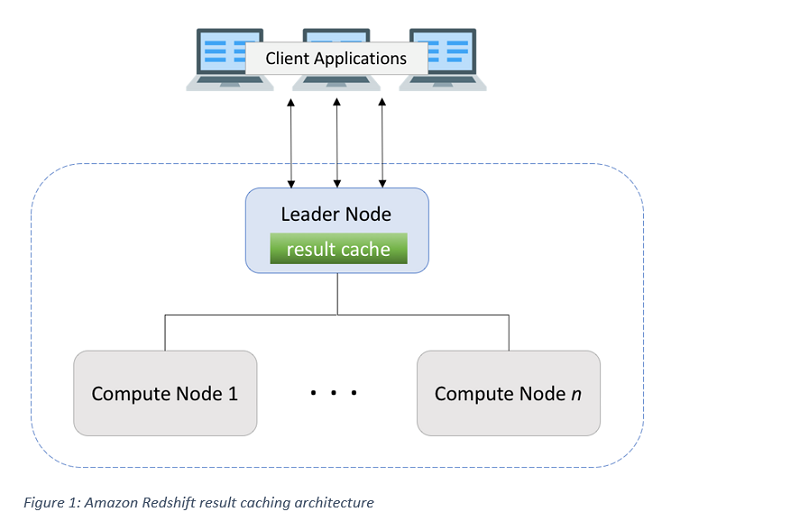
Get sub-second query response times with Amazon Redshift result caching
In this post, we take a look at query result caching in Amazon Redshift. Result caching does exactly what its name implies—it caches the results of a query.
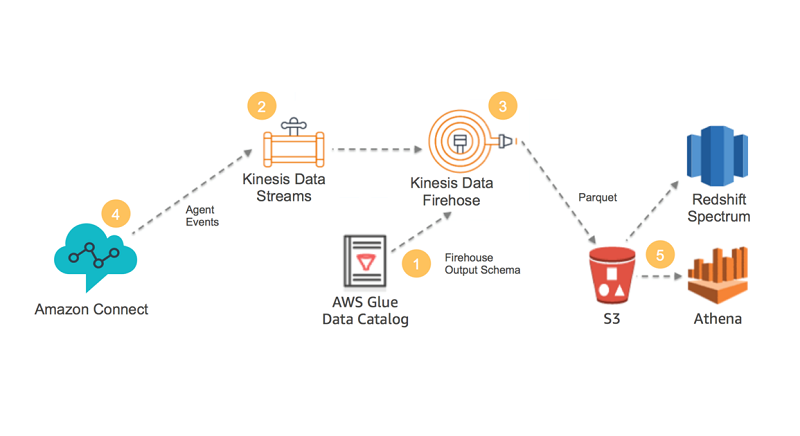
Analyze Apache Parquet optimized data using Amazon Kinesis Data Firehose, Amazon Athena, and Amazon Redshift
Kinesis Data Firehose can now save data to Amazon S3 in Apache Parquet or Apache ORC format. These are optimized columnar formats that are highly recommended for best performance and cost-savings when querying data in S3. This feature directly benefits you if you use Amazon Athena, Amazon Redshift, AWS Glue, Amazon EMR, or any other big data tools that are available from the AWS Partner Network and through the open-source community.
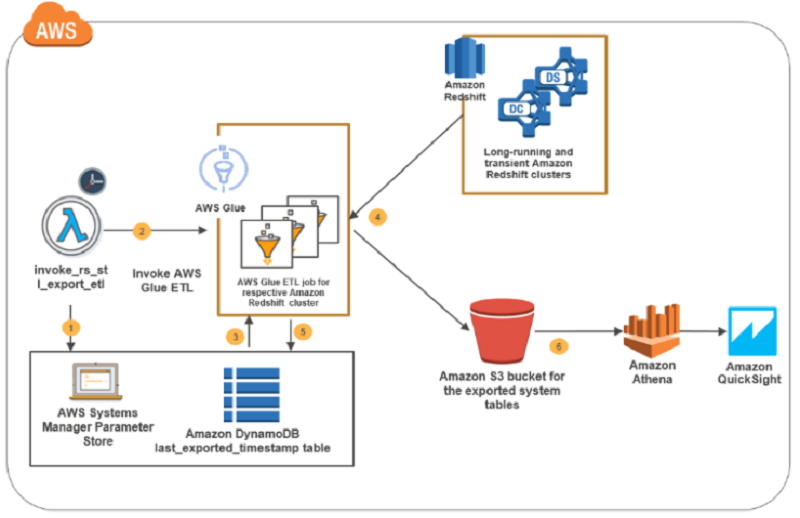
How to retain system tables’ data spanning multiple Amazon Redshift clusters and run cross-cluster diagnostic queries
In this blog post, I present a solution that exports system tables from multiple Amazon Redshift clusters into an Amazon S3 bucket. This solution is serverless, and you can schedule it as frequently as every five minutes. The AWS CloudFormation deployment template that I provide automates the solution setup in your environment. The system tables’ data in the Amazon S3 bucket is partitioned by cluster name and query execution date to enable efficient joins in cross-cluster diagnostic queries.