AWS Big Data Blog
Category: Amazon Redshift

Federate Database User Authentication Easily with IAM and Amazon Redshift
Managing database users though federation allows you to manage authentication and authorization procedures centrally. Amazon Redshift now supports database authentication with IAM, enabling user authentication though enterprise federation. In this post, I demonstrate how you can extend the federation to enable single sign-on (SSO) to the Amazon Redshift data warehouse.

Amazon Redshift Dense Compute (DC2) Nodes Deliver Twice the Performance as DC1 at the Same Price
Today, we are making our Dense Compute (DC) family faster and more cost-effective with new second-generation Dense Compute (DC2) nodes at the same price as our previous generation DC1. DC2 is designed for demanding data warehousing workloads that require low latency and high throughput. DC2 features powerful Intel E5-2686 v4 (Broadwell) CPUs, fast DDR4 memory, and NVMe-based solid state disks.

Building a Real World Evidence Platform on AWS
Deriving insights from large datasets is central to nearly every industry, and life sciences is no exception. To combat the rising cost of bringing drugs to market, pharmaceutical companies are looking for ways to optimize their drug development processes. They are turning to big data analytics to better quantify the effect that their drug compounds […]

Amazon Redshift Spectrum Extends Data Warehousing Out to Exabytes—No Loading Required
When we first looked into the possibility of building a cloud-based data warehouse many years ago, we were struck by the fact that our customers were storing ever-increasing amounts of data, and yet only a small fraction of that data ever made it into a data warehouse or Hadoop system for analysis. We saw that […]
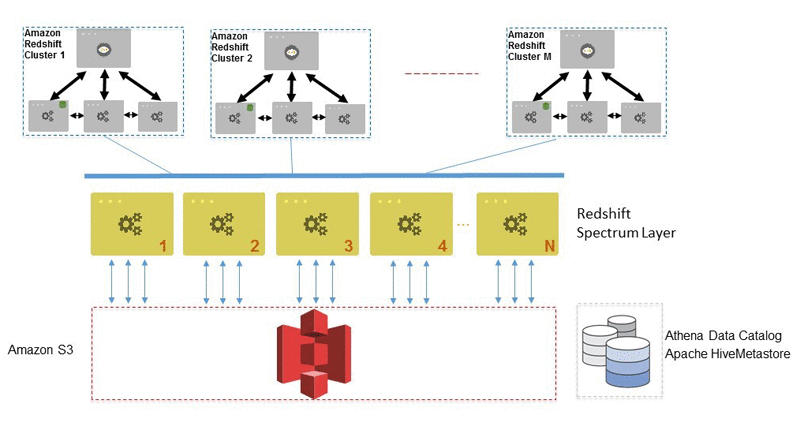
Best Practices for Amazon Redshift Spectrum
November 2022: This post was reviewed and updated for accuracy. Amazon Redshift Spectrum enables you to run Amazon Redshift SQL queries on data that is stored in Amazon Simple Storage Service (Amazon S3). With Amazon Redshift Spectrum, you can extend the analytic power of Amazon Redshift beyond the data that is stored natively in Amazon […]
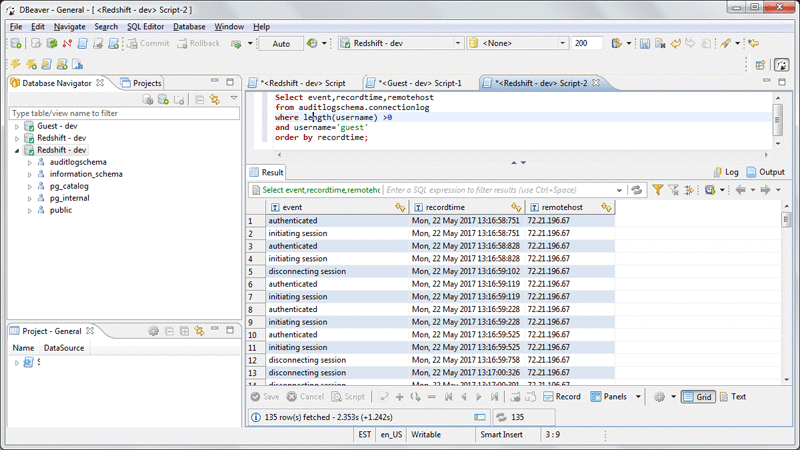
Analyze Database Audit Logs for Security and Compliance Using Amazon Redshift Spectrum
In this post, we’ll demonstrate querying the Amazon Redshift audit data logged in S3 to provide answers to common use cases described preceding.
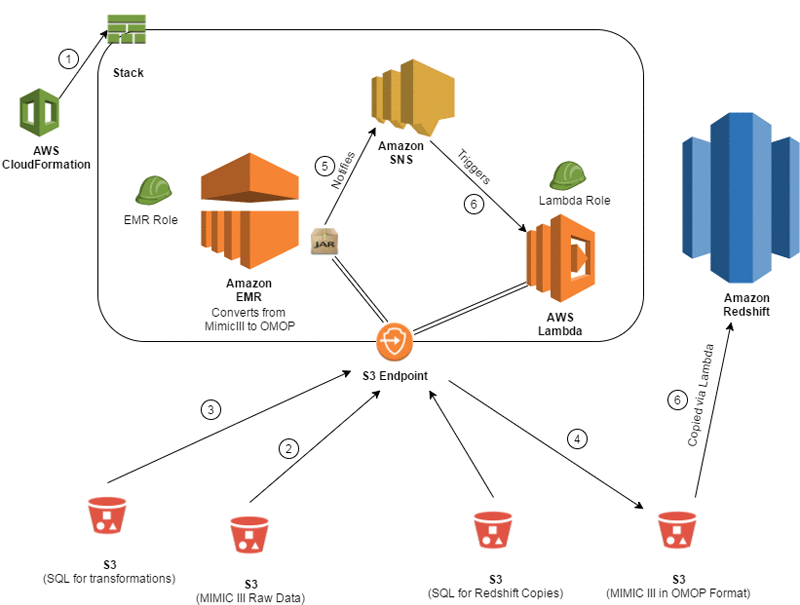
Build a Healthcare Data Warehouse Using Amazon EMR, Amazon Redshift, AWS Lambda, and OMOP
In the healthcare field, data comes in all shapes and sizes. Despite efforts to standardize terminology, some concepts (e.g., blood glucose) are still often depicted in different ways. This post demonstrates how to convert an openly available dataset called MIMIC-III, which consists of de-identified medical data for about 40,000 patients, into an open source data […]
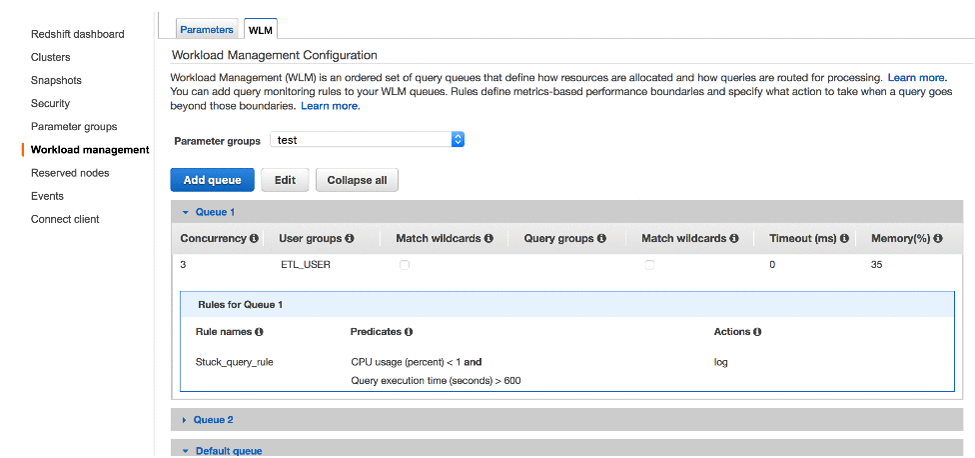
Manage Query Workloads with Query Monitoring Rules in Amazon Redshift
This blog post has been translated into Japanese and Chinese. Data warehousing workloads are known for high variability due to seasonality, potentially expensive exploratory queries, and the varying skill levels of SQL developers. To obtain high performance in the face of highly variable workloads, Amazon Redshift workload management (WLM) enables you to flexibly manage priorities and resource […]

Amazon Redshift Monitoring Now Supports End User Queries and Canaries
Ian Meyers is a Solutions Architecture Senior Manager with AWS The serverless Amazon Redshift Monitoring utility lets you gather important performance metrics from your Redshift cluster’s system tables and persists the results in Amazon CloudWatch. This serverless solution leverages AWS Lambda to schedule custom SQL queries and process the results. With this utility, you can use […]
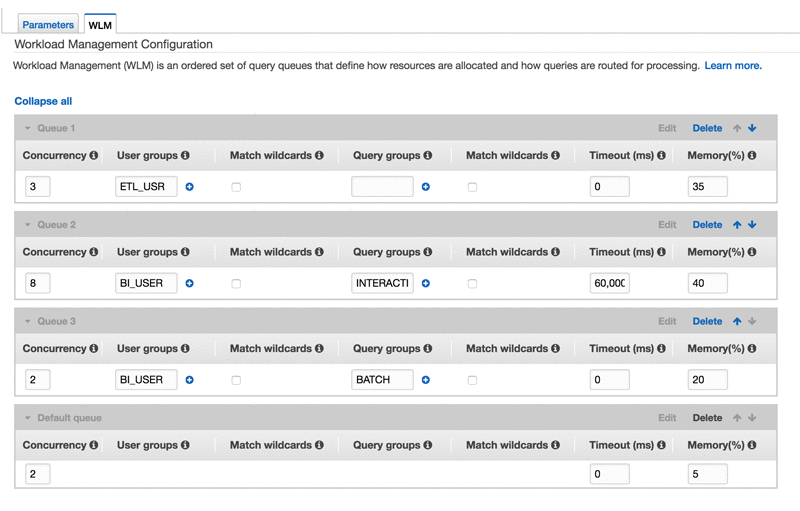
Run Mixed Workloads with Amazon Redshift Workload Management
This blog post has been translated into Japanese. Mixed workloads run batch and interactive workloads (short-running and long-running queries or reports) concurrently to support business needs or demand. Typically, managing and configuring mixed workloads requires a thorough understanding of access patterns, how the system resources are being used and performance requirements. It’s common for mixed […]