AWS Big Data Blog
Category: Compute

Enable advanced search capabilities for Amazon Keyspaces data by integrating with Amazon OpenSearch Service
In this post, we explore the process of integrating Amazon Keyspaces and Amazon OpenSearch Service using AWS Lambda and Amazon OpenSearch Ingestion to enable advanced search capabilities. The content includes a reference architecture, a step-by-step guide on infrastructure setup, sample code for implementing the solution within a use case, and an AWS Cloud Development Kit (AWS CDK) application for deployment.

Disaster recovery strategies for Amazon MWAA – Part 1
In the dynamic world of cloud computing, ensuring the resilience and availability of critical applications is paramount. Disaster recovery (DR) is the process by which an organization anticipates and addresses technology-related disasters. For organizations implementing critical workload orchestration using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), it is crucial to have a DR plan […]

Enable metric-based and scheduled scaling for Amazon Managed Service for Apache Flink
Thousands of developers use Apache Flink to build streaming applications to transform and analyze data in real time. Apache Flink is an open source framework and engine for processing data streams. It’s highly available and scalable, delivering high throughput and low latency for the most demanding stream-processing applications. Monitoring and scaling your applications is critical […]

Amazon MSK now provides up to 29% more throughput and up to 24% lower costs with AWS Graviton3 support
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that enables you to build and run applications that use Apache Kafka to process streaming data. Today, we’re excited to bring the benefits of Graviton3 to Kafka workloads, with Amazon MSK now offering M7g instances for new MSK provisioned clusters. AWS Graviton […]

Introducing shared VPC support on Amazon MWAA
In this post, we demonstrate automating deployment of Amazon Managed Workflows for Apache Airflow (Amazon MWAA) using customer-managed endpoints in a VPC, providing compatibility with shared, or otherwise restricted, VPCs. Data scientists and engineers have made Apache Airflow a leading open source tool to create data pipelines due to its active open source community, familiar […]

GoDaddy benchmarking results in up to 24% better price-performance for their Spark workloads with AWS Graviton2 on Amazon EMR Serverless
This is a guest post co-written with Mukul Sharma, Software Development Engineer, and Ozcan IIikhan, Director of Engineering from GoDaddy. GoDaddy empowers everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their ideas, build a professional website, […]

Spark on AWS Lambda: An Apache Spark runtime for AWS Lambda
Spark on AWS Lambda (SoAL) is a framework that runs Apache Spark workloads on AWS Lambda. It’s designed for both batch and event-based workloads, handling data payload sizes from 10 KB to 400 MB. This post highlights the SoAL architecture, provides infrastructure as code (IaC), offers step-by-step instructions for setting up the SoAL framework in your AWS account, and outlines SoAL architectural patterns for enterprises.

Unstructured data management and governance using AWS AI/ML and analytics services
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
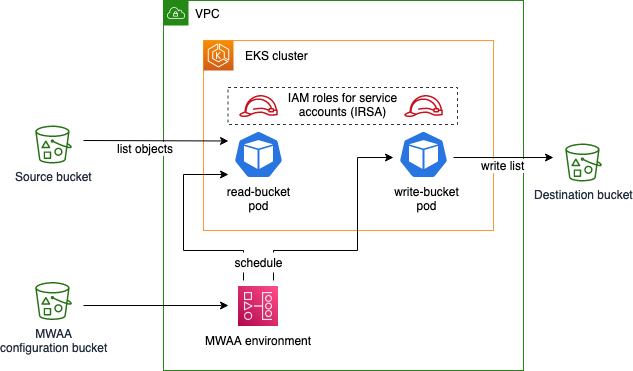
Set up fine-grained permissions for your data pipeline using MWAA and EKS
This blog post shows how to improve security in a data pipeline architecture based on Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Amazon Elastic Kubernetes Service (Amazon EKS) by setting up fine-grained permissions, using HashiCorp Terraform for infrastructure as code.

Simplify operational data processing in data lakes using AWS Glue and Apache Hudi
AWS has invested in native service integration with Apache Hudi and published technical contents to enable you to use Apache Hudi with AWS Glue (for example, refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started). In AWS ProServe-led customer engagements, the use cases we work on usually come with technical complexity and scalability requirements. In this post, we discuss a common use case in relation to operational data processing and the solution we built using Apache Hudi and AWS Glue.