AWS Big Data Blog
Category: AWS Lambda

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.

Orchestrate multiple ETL jobs using AWS Step Functions and AWS Lambda
In this post, I show you how to use AWS Step Functions and AWS Lambda for orchestrating multiple ETL jobs involving a diverse set of technologies in an arbitrarily-complex ETL workflow.
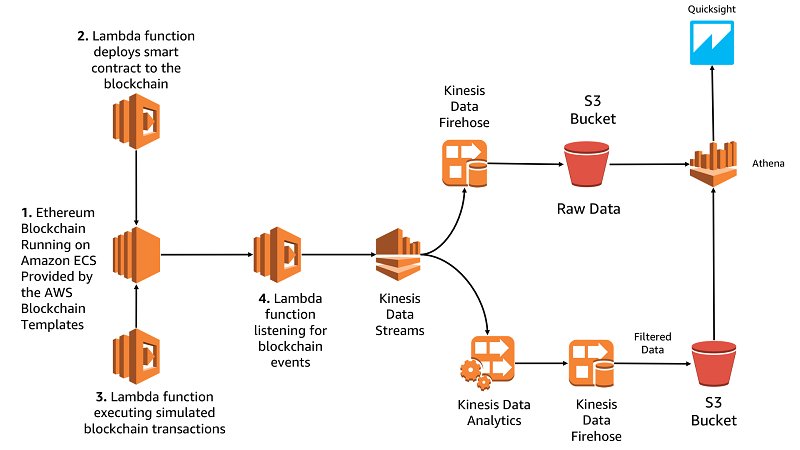
Build a blockchain analytic solution with AWS Lambda, Amazon Kinesis, and Amazon Athena
In this post, we’ll show you how to deploy an Ethereum blockchain using the AWS Blockchain Templates, deploy a smart contract, and build a serverless analytics pipeline for that contract based around AWS Lambda, Amazon Kinesis, and Amazon Athena.
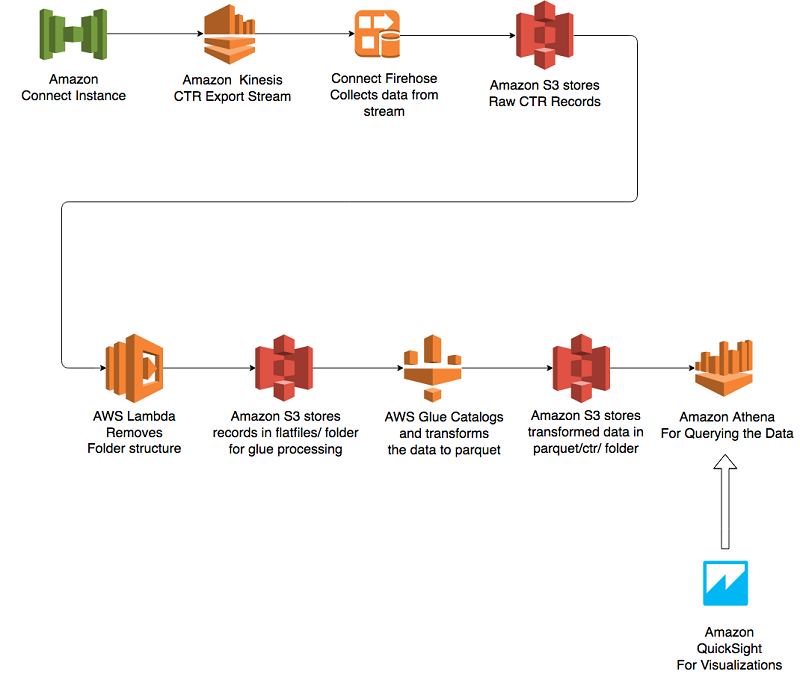
Analyze Amazon Connect records with Amazon Athena, AWS Glue, and Amazon QuickSight
In this blog post, we focus on how to get analytics out of the rich set of data published by Amazon Connect. We make use of an Amazon Connect data stream and create an end-to-end workflow to offer an analytical solution that can be customized based on need.

Orchestrate Apache Spark applications using AWS Step Functions and Apache Livy
In this post, I’ll show you how to use AWS Step Functions to orchestrate your Spark jobs that are running on Amazon EMR.
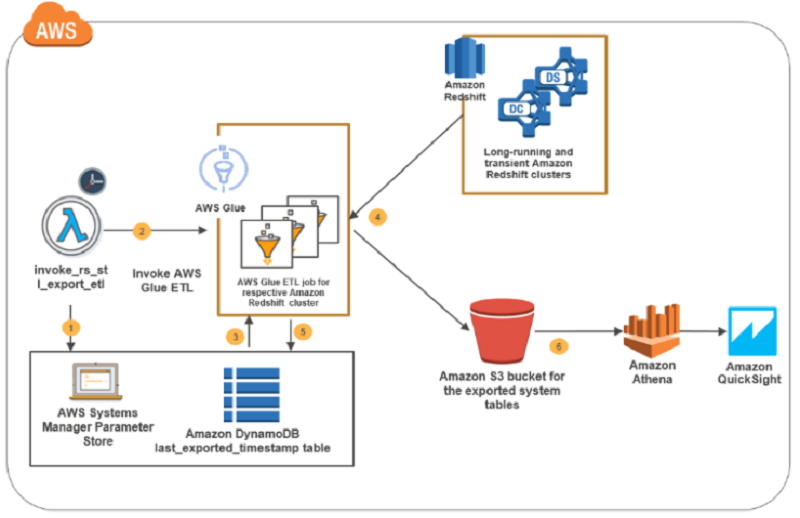
How to retain system tables’ data spanning multiple Amazon Redshift clusters and run cross-cluster diagnostic queries
In this blog post, I present a solution that exports system tables from multiple Amazon Redshift clusters into an Amazon S3 bucket. This solution is serverless, and you can schedule it as frequently as every five minutes. The AWS CloudFormation deployment template that I provide automates the solution setup in your environment. The system tables’ data in the Amazon S3 bucket is partitioned by cluster name and query execution date to enable efficient joins in cross-cluster diagnostic queries.

Dynamically Create Friendly URLs for Your Amazon EMR Web Interfaces
This solution provides a serverless approach to automatically assigning a friendly name for your EMR cluster for easy access to popular notebooks and other web interfaces.
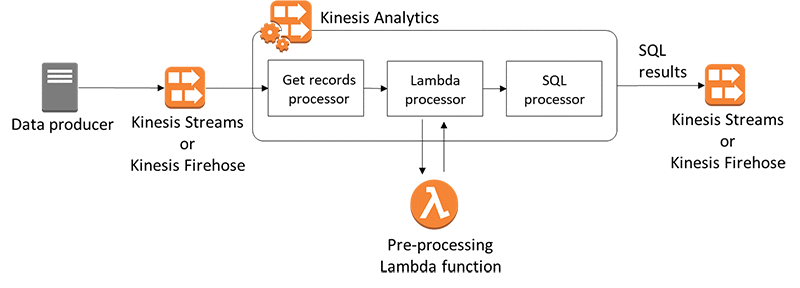
Preprocessing Data in Amazon Kinesis Analytics with AWS Lambda
Kinesis Analytics now gives you the option to preprocess your data with AWS Lambda. This gives you a great deal of flexibility in defining what data gets analyzed by your Kinesis Analytics application. In this post, I discuss some common use cases for preprocessing, and walk you through an example to help highlight its applicability.

Implement Continuous Integration and Delivery of Apache Spark Applications using AWS
In this post, we walk you through a solution that implements a continuous integration and deployment pipeline supported by AWS services. You can use the sample template and Spark application shared in this post and adapt them for the specific needs of your own application.

Building a Real World Evidence Platform on AWS
Deriving insights from large datasets is central to nearly every industry, and life sciences is no exception. To combat the rising cost of bringing drugs to market, pharmaceutical companies are looking for ways to optimize their drug development processes. They are turning to big data analytics to better quantify the effect that their drug compounds […]