AWS Big Data Blog
Category: Artificial Intelligence
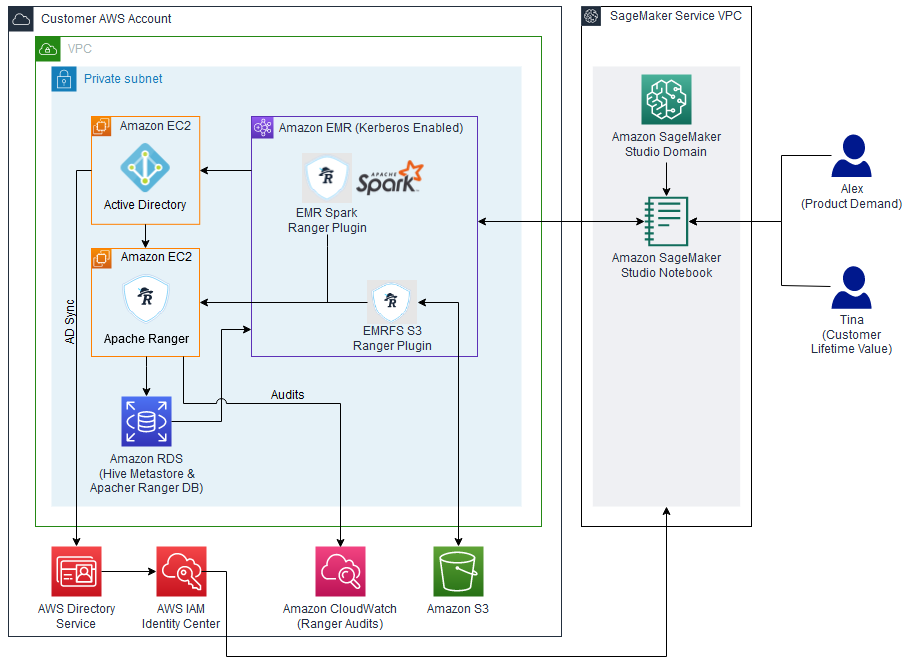
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.

Create, train, and deploy Amazon Redshift ML model integrating features from Amazon SageMaker Feature Store
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers rely on to power their analytics workloads. Data analysts and database developers want to use this data to train machine learning (ML) models, which can then be used to generate insights on new data for use cases such as forecasting […]

Unstructured data management and governance using AWS AI/ML and analytics services
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
How Chime Financial uses AWS to build a serverless stream analytics platform and defeat fraudsters
This is a guest post by Khandu Shinde, Staff Software Engineer and Edward Paget, Senior Software Engineering at Chime Financial. Chime is a financial technology company founded on the premise that basic banking services should be helpful, easy, and free. Chime partners with national banks to design member first financial products. This creates a more […]

Explore real-world use cases for Amazon CodeWhisperer powered by AWS Glue Studio notebooks
Many customers are interested in boosting productivity in their software development lifecycle by using generative AI. Recently, AWS announced the general availability of Amazon CodeWhisperer, an AI coding companion that uses foundational models under the hood to improve software developer productivity. With Amazon CodeWhisperer, you can quickly accept the top suggestion, view more suggestions, or […]

Perform time series forecasting using Amazon Redshift ML and Amazon Forecast
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Many businesses use different software tools to analyze historical data and past patterns to forecast future demand and trends to make more […]

Build data integration jobs with AI companion on AWS Glue Studio notebook powered by Amazon CodeWhisperer
Data is essential for businesses to make informed decisions, improve operations, and innovate. Integrating data from different sources can be a complex and time-consuming process. AWS offers AWS Glue to help you integrate your data from multiple sources on serverless infrastructure for analysis, machine learning (ML), and application development. AWS Glue provides different authoring experiences […]

Harmonize data using AWS Glue and AWS Lake Formation FindMatches ML to build a customer 360 view
In today’s digital world, data is generated by a large number of disparate sources and growing at an exponential rate. Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their data lake to derive […]

Amazon OpenSearch Service’s vector database capabilities explained
Using Amazon OpenSearch Service’s vector database capabilities, you can implement semantic search, Retrieval Augmented Generation (RAG) with LLMs, recommendation engines, and search in rich media. Learn how.

Real-time time series anomaly detection for streaming applications on Amazon Managed Service for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Detecting anomalies in real time from high-throughput streams is key for informing on timely decisions in order to adapt and respond to unexpected scenarios. Stream processing frameworks […]