AWS Big Data Blog
Category: Analytics
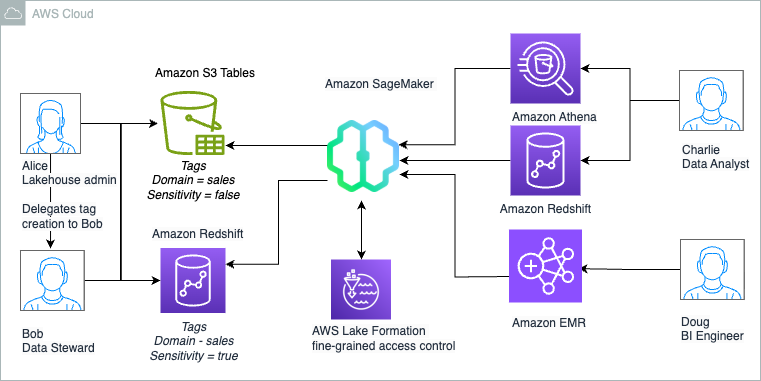
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Modernize Amazon Redshift authentication by migrating user management to AWS IAM Identity Center
Amazon Redshift is a powerful cloud-based data warehouse that organizations can use to analyze both structured and semi-structured data through advanced SQL queries. As a fully managed service, it provides high performance and scalability while allowing secure access to the data stored in the data warehouse. Organizations worldwide rely on Amazon Redshift to handle massive […]

Implement fine-grained access control using Amazon OpenSearch Service and JSON Web Tokens
This post demonstrates how to build a secure search application using Amazon OpenSearch Service and JSON Web Tokens (JWTs). We discuss the basics of OpenSearch Service and JWTs and how to implement user authentication and authorization through an existing identity provider (IdP). The focus is on enforcing fine-grained access control based on user roles and permissions.

How Ancestry optimizes a 100-billion-row Iceberg table
This is a guest post by Thomas Cardenas, Staff Software Engineer at Ancestry, in partnership with AWS. Ancestry, the global leader in family history and consumer genomics, uses family trees, historical records, and DNA to help people on their journeys of personal discovery. Ancestry has the largest collection of family history records, consisting of 40 […]

How AppZen enhances operational efficiency, scalability, and security with Amazon OpenSearch Serverless
AppZen is a leading provider of AI-driven finance automation solutions. The company’s core offering centers around an innovative AI platform designed for modern finance teams, featuring expense management, fraud detection, and autonomous accounts payable solutions. AppZen’s technology stack uses computer vision, deep learning, and natural language processing (NLP) to automate financial processes and ensure compliance. […]

Zero-ETL: How AWS is tackling data integration challenges
In this blog post, we show you how Amazon Web Services (AWS) is simplifying data integration with zero-ETL while realizing performance benefits and cost optimizations. As organizations gather data for analytics and AI, they are increasingly finding themselves caught in a complex web of extract, transform, and load (ETL) pipelines—the traditional backbone of data integration. […]

Best practices for migrating Teradata BTEQ scripts to Amazon Redshift RSQL
When migrating from Teradata BTEQ (Basic Teradata Query) to Amazon Redshift RSQL, following established best practices helps ensure maintainable, efficient, and reliable code. While the AWS Schema Conversion Tool (AWS SCT) automatically handles the basic conversion of BTEQ scripts to RSQL, it primarily focuses on SQL syntax translation and basic script conversion. However, to achieve […]

Amazon Redshift Serverless at 4 RPUs: High-value analytics at low cost
Amazon Redshift Serverless now supports 4 RPU configurations, helping you get started with a lower base capacity that runs scalable analytics workloads beginning at $1.50 per hour. In this post, we examine how this new sizing option makes Redshift Serverless accessible to smaller organizations while providing enterprises with cost-effective environments for development, testing, and variable workloads.

Zeta reduces banking incident response time by 80% with Amazon OpenSearch Service observability
In this post we explain how Zeta built a more unified monitoring solution using Amazon OpenSearch Service that improved performance, reduced manual processes, and increased end-user satisfaction. Zeta has achieved over an 80% reduction in mean time to resolution (MTTR), with incident response times decreasing from 30+ minutes to under 5 minutes.

Build enterprise-scale log ingestion pipelines with Amazon OpenSearch Service
In this post, we share field-tested patterns for log ingestion that have helped organizations successfully implement logging at scale, while maintaining optimal performance and managing costs effectively. A well-designed log analytics solution can help support proactive management in a variety of use cases, including debugging production issues, monitoring application performance, or meeting compliance requirements.