AWS Big Data Blog
Category: Amazon Redshift
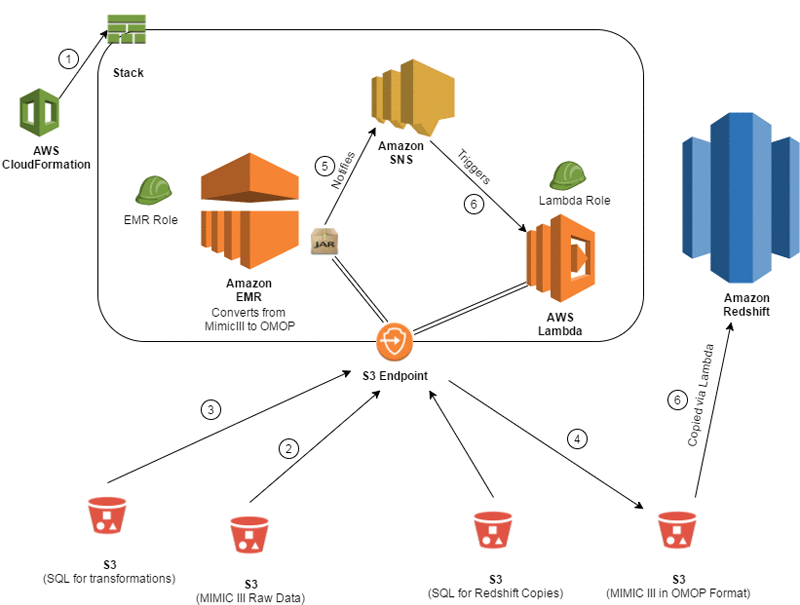
Build a Healthcare Data Warehouse Using Amazon EMR, Amazon Redshift, AWS Lambda, and OMOP
In the healthcare field, data comes in all shapes and sizes. Despite efforts to standardize terminology, some concepts (e.g., blood glucose) are still often depicted in different ways. This post demonstrates how to convert an openly available dataset called MIMIC-III, which consists of de-identified medical data for about 40,000 patients, into an open source data […]
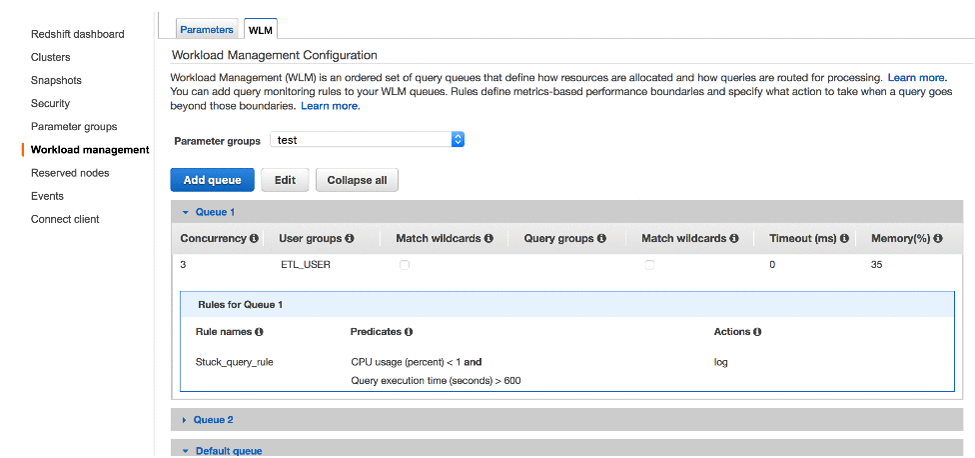
Manage Query Workloads with Query Monitoring Rules in Amazon Redshift
This blog post has been translated into Japanese and Chinese. Data warehousing workloads are known for high variability due to seasonality, potentially expensive exploratory queries, and the varying skill levels of SQL developers. To obtain high performance in the face of highly variable workloads, Amazon Redshift workload management (WLM) enables you to flexibly manage priorities and resource […]

Amazon Redshift Monitoring Now Supports End User Queries and Canaries
Ian Meyers is a Solutions Architecture Senior Manager with AWS The serverless Amazon Redshift Monitoring utility lets you gather important performance metrics from your Redshift cluster’s system tables and persists the results in Amazon CloudWatch. This serverless solution leverages AWS Lambda to schedule custom SQL queries and process the results. With this utility, you can use […]
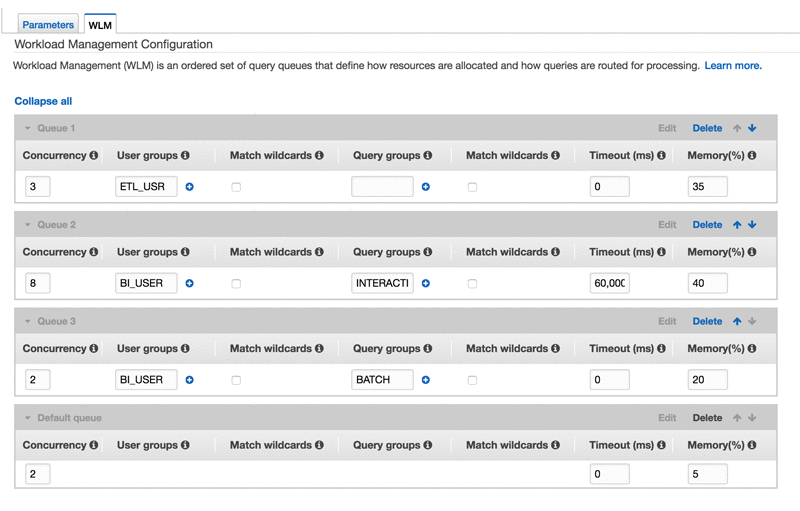
Run Mixed Workloads with Amazon Redshift Workload Management
This blog post has been translated into Japanese. Mixed workloads run batch and interactive workloads (short-running and long-running queries or reports) concurrently to support business needs or demand. Typically, managing and configuring mixed workloads requires a thorough understanding of access patterns, how the system resources are being used and performance requirements. It’s common for mixed […]
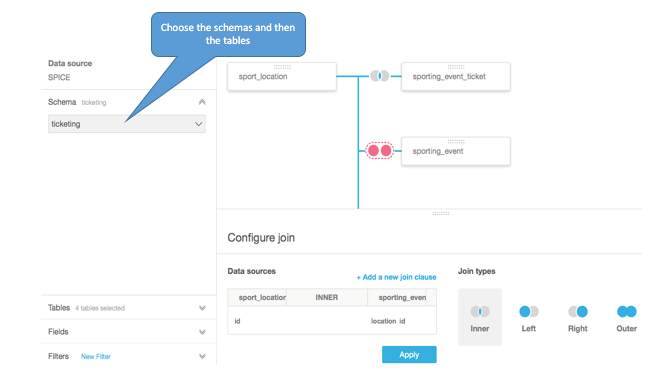
Converging Data Silos to Amazon Redshift Using AWS DMS
Organizations often grow organically—and so does their data in individual silos. Such systems are often powered by traditional RDBMS systems and they grow orthogonally in size and features. To gain intelligence across heterogeneous data sources, you have to join the data sets. However, this imposes new challenges, as joining data over dblinks or into a […]

Decreasing Game Churn: How Upopa used ironSource Atom and Amazon ML to Engage Users
This is a guest post by Tom Talpir, Software Developer at ironSource. ironSource is as an Advanced AWS Partner Network (APN) Technology Partner and an AWS Big Data Competency Partner. Ever wondered what it takes to keep a user from leaving your game or application after all the hard work you put in? Wouldn’t it be great […]
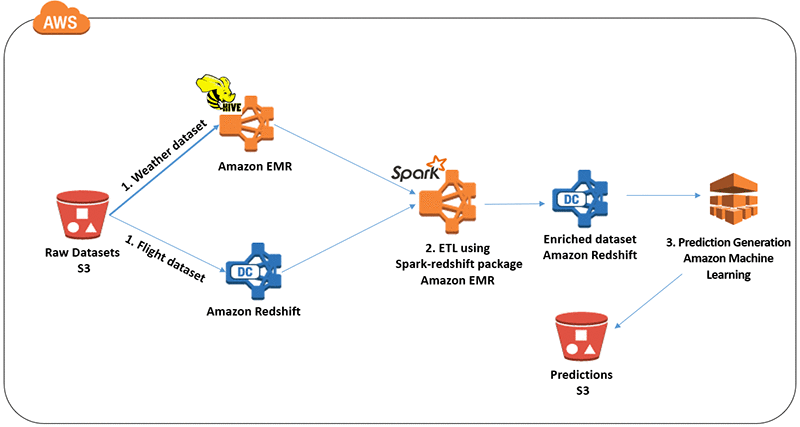
Powering Amazon Redshift Analytics with Apache Spark and Amazon Machine Learning
Air travel can be stressful due to the many factors that are simply out of airline passengers’ control. As passengers, we want to minimize this stress as much as we can. We can do this by using past data to make predictions about how likely a flight will be delayed based on the time of […]

Building an Event-Based Analytics Pipeline for Amazon Game Studios’ Breakaway
All software developers strive to build products that are functional, robust, and bug-free, but video game developers have an extra challenge: they must also create a product that entertains. When designing a game, developers must consider how the various elements—such as characters, story, environment, and mechanics—will fit together and, more importantly, how players will interact […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Table Data Durability
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings Part 5: Table Data Durability (Translated into Japanese) In the fifth and final installment of the Advanced Table Design Playbook, I’ll discuss how to use two simple table durability properties to […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Compression Encodings
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings (Translated into Japanese) Part 5: Table Data Durability In part 4 of this blog series, I’ll be discussing when and when not to apply column encoding for compression, methods for determining ideal […]