AWS Big Data Blog
Category: Amazon Redshift
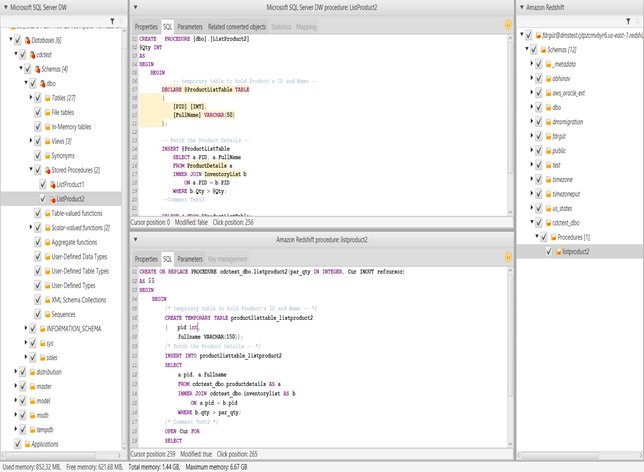
Bringing your stored procedures to Amazon Redshift
Amazon always works backwards from the customer’s needs. Customers have made strong requests that they want stored procedures in Amazon Redshift, to make it easier to migrate their existing workloads from legacy, on-premises data warehouses.
With that primary goal in mind, AWS chose to implement PL/pqSQL stored procedure to maximize compatibility with existing procedures and simplify migrations. In this post, we discuss how and where to use stored procedures to improve operational efficiency and security. We also explain how to use stored procedures with AWS Schema Conversion Tool.
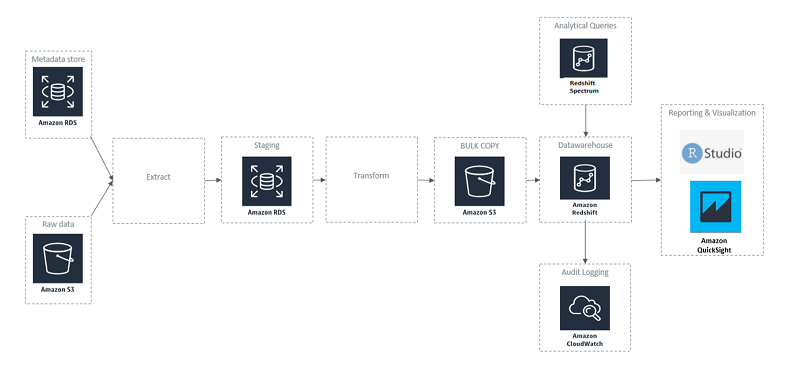
How 3M Health Information Systems built a healthcare data reporting tool with Amazon Redshift
After reviewing many solutions, 3M HIS chose Amazon Redshift as the appropriate data warehouse solution. We concluded Amazon Redshift met our needs; a fast, fully managed, petabyte-scale data warehouse solution that uses columnar storage to minimize I/O, provides high data compression rates, and offers fast performance. We quickly spun up a cluster in our development environment, built out the dimensional model, loaded data, and made it available to perform benchmarking and testing of the user data. An extract, transform, load (ETL) tool was used to process and load the data from various sources into Amazon Redshift.

Query your Amazon Redshift cluster with the new Query Editor
Data warehousing is a critical component for analyzing and extracting actionable insights from your data. Amazon Redshift is a fast, scalable data warehouse that makes it cost-effective to analyze all of your data across your data warehouse and data lake. The Amazon Redshift console recently launched the Query Editor. The Query Editor is an in-browser […]

Federate Amazon Redshift access with Okta as an identity provider
December 2022: This post was reviewed and updated for accuracy. Managing database users and access can be a daunting and error-prone task. In the past, database administrators had to determine which groups a user belongs to and which objects a user/group is authorized to use. These lists were maintained within the database and could easily […]

Grant fine-grained access to the Amazon Redshift Management Console
As a fully managed service, Amazon Redshift is designed to be easy to set up and use. In this blog post, we demonstrate how to grant access to users in an operations group to perform only specific actions in the Amazon Redshift Management Console. If you implement a custom IAM policy, you can set it […]
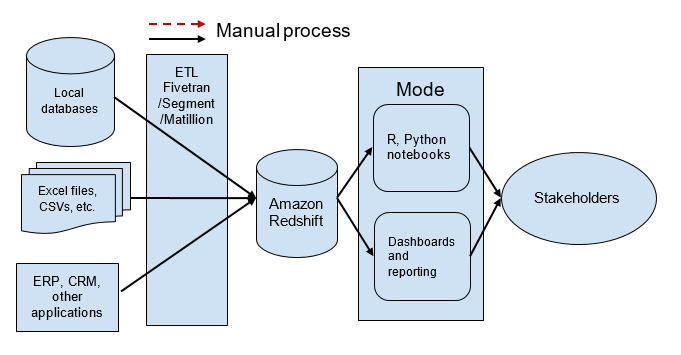
Build a modern analytics stack optimized for sharing and collaborating with Mode and Amazon Redshift
Leading technology companies, such as Netflix and Airbnb, are building on AWS to solve problems on the edge of the data ecosystem. While these companies show us what data and analytics make possible, the complexity and scale of their problems aren’t typical. Most of our challenges aren’t figuring out how to process billions of records […]

How to enable cross-account Amazon Redshift COPY and Redshift Spectrum query for AWS KMS–encrypted data in Amazon S3
This post shows a step-by-step walkthrough of how to set up a cross-account Amazon Redshift COPY and Spectrum query using a sample dataset in Amazon S3. The sample dataset is encrypted at rest using AWS KMS-managed keys (SSE-KMS). About AWS Key Management Service (AWS KMS) With AWS Key Management Service (AWS KMS), you can have […]

Run Amazon payments analytics with 750 TB of data on Amazon Redshift
The Amazon Payments Data Engineering team is responsible for data ingestion, transformation, and storage of a growing dataset of more than 750 TB. The team makes these services available to more than 300 business customers around the globe. These customers include managers from the product, marketing, and programs domains; as well as data scientists, business analysts, […]
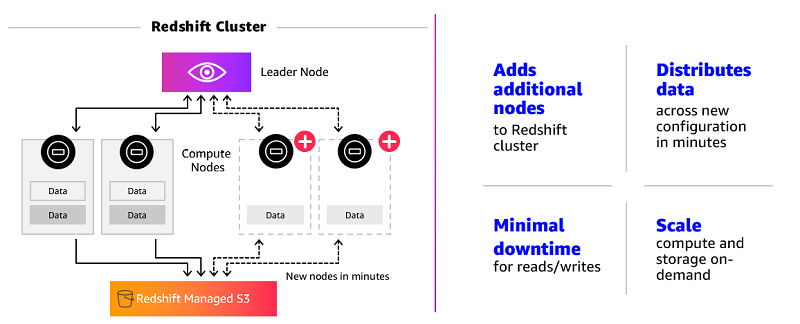
Scale your Amazon Redshift clusters up and down in minutes to get the performance you need, when you need it
Amazon Redshift is the cloud data warehouse of choice for organizations of all sizes—from fast-growing technology companies such as Turo and Yelp to Fortune 500 companies such as 21st Century Fox and Johnson & Johnson. With quickly expanding use cases, data sizes, and analyst populations, these customers have a critical need for scalable data warehouses. […]
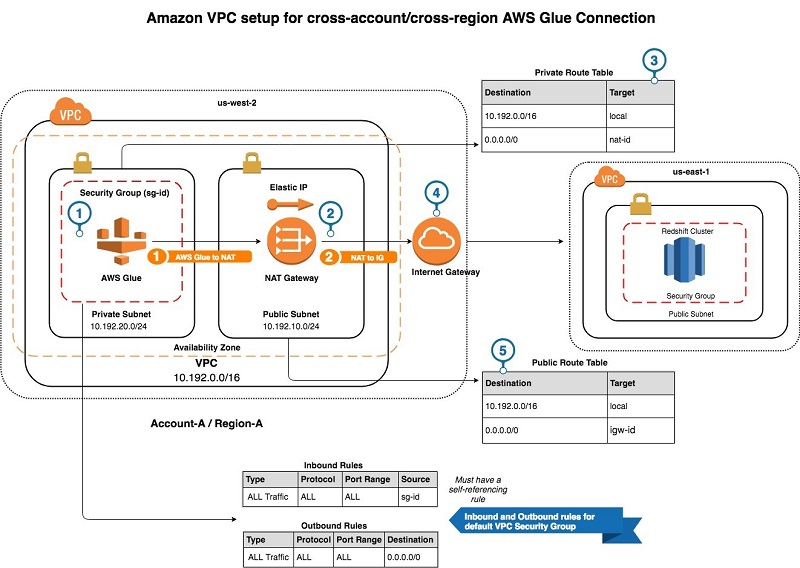
Create cross-account and cross-region AWS Glue connections
In this blog post, we describe how to configure the networking routes and interfaces to give AWS Glue access to a data store in an AWS Region different from the one with your AWS Glue resources. In our example, we connect AWS Glue, located in Region A, to an Amazon Redshift data warehouse located in Region B.