AWS Big Data Blog
Category: Amazon Redshift

Integrate Power BI with Amazon Redshift for insights and analytics
July 2022: This post was reviewed for accuracy. Amazon Redshift is a fast, fully managed, cloud-native data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Microsoft Power BI is a business analytics service that delivers insights to enable fast, informed decisions. […]

Analyze your Amazon S3 spend using AWS Glue and Amazon Redshift
The AWS Cost & Usage Report (CUR) tracks your AWS usage and provides estimated charges associated with that usage. You can configure this report to present the data at hourly or daily intervals, and it is updated at least one time per day until it is finalized at the end of the billing period. The […]

Amazon Redshift at re:Invent 2019
The annual AWS re:Invent learning conference is an exciting time full of new product and program launches. At the first re:Invent conference in 2012, AWS announced Amazon Redshift. Since then, tens of thousands of customers have started using Amazon Redshift as their cloud data warehouse. In 2019, AWS shared several significant launches and dozens of […]

Maximize data ingestion and reporting performance on Amazon Redshift
This is a guest post from ZS. In their own words, “ZS is a professional services firm that works closely with companies to help develop and deliver products and solutions that drive customer value and company results. ZS engagements involve a blend of technology, consulting, analytics, and operations, and are targeted toward improving the commercial […]

Working with nested data types using Amazon Redshift Spectrum
Redshift Spectrum is a feature of Amazon Redshift that allows you to query data stored on Amazon S3 directly and supports nested data types. This post discusses which use cases can benefit from nested data types, how to use Amazon Redshift Spectrum with nested data types to achieve excellent performance and storage efficiency, and some […]

ETL and ELT design patterns for modern data architecture using Amazon Redshift: Part 2
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks. Part 1 of this multi-post series, ETL and ELT design patterns for modern data architecture using Amazon Redshift: Part 1, […]

ETL and ELT design patterns for lake house architecture using Amazon Redshift: Part 1
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks. Part 1 of this multi-post series discusses design best practices for building scalable ETL (extract, transform, load) and ELT (extract, […]
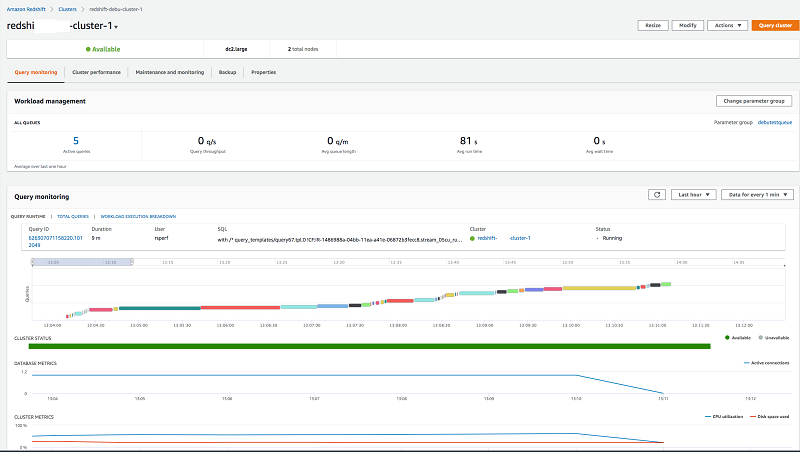
Simplify management of Amazon Redshift clusters with the Redshift console
Amazon Redshift is the most popular and the fastest cloud data warehouse. It includes a console for administrators to create, configure, and manage Amazon Redshift clusters. The new Amazon Redshift console modernizes the user interface and adds several features to improve managing your clusters and workloads running on clusters. The new Amazon Redshift console provides visibility to the health and performance of clusters from a unified dashboard, simplified management of clusters by streamlining several screens and flows, improved mean-time-to-diagnose query performance issues by adding capabilities to monitor user queries and correlate with cluster performance metrics, as well as the ability for non-admin users to use Query Editor.

Orchestrate Amazon Redshift-Based ETL workflows with AWS Step Functions and AWS Glue
In this post, I show how to use AWS Step Functions and AWS Glue Python Shell to orchestrate tasks for those Amazon Redshift-based ETL workflows in a completely serverless fashion. AWS Glue Python Shell is a Python runtime environment for running small to medium-sized ETL tasks, such as submitting SQL queries and waiting for a response. Step Functions lets you coordinate multiple AWS services into workflows so you can easily run and monitor a series of ETL tasks. Both AWS Glue Python Shell and Step Functions are serverless, allowing you to automatically run and scale them in response to events you define, rather than requiring you to provision, scale, and manage servers.

Protect and Audit PII data in Amazon Redshift with DataSunrise Security
This post focuses on active security for Amazon Redshift, in particular DataSunrise’s capabilities for masking and access control of personally identifiable information (PII), which you can back with DataSunrise’s passive security offerings such as auditing access of sensitive information. This post discusses DataSunrise security for Amazon Redshift, how it works, and how to get started.