AWS Big Data Blog
Category: Amazon Redshift

Automating DBA tasks on Amazon Redshift securely using AWS IAM, AWS Lambda, Amazon EventBridge, and stored procedures
As a data warehouse administrator or data engineer, you may need to perform maintenance tasks and activities or perform some level of custom monitoring on a regular basis. You can combine these activities inside a stored procedure or invoke views to get details. Some of these activities include things like loading nightly staging tables, invoking […]
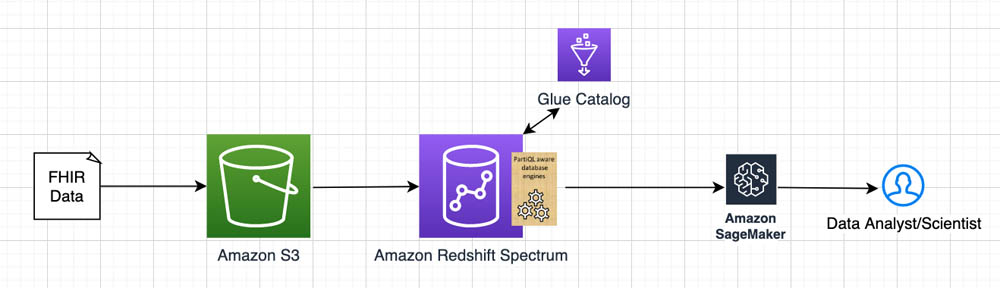
Analyzing healthcare FHIR data with Amazon Redshift PartiQL
Healthcare organizations across the globe strive to provide the best possible patient care at the lowest cost. In a patient’s care journey, multiple organizations are often involved, including the healthcare provider, diagnostic labs, pharmacies, and health insurance payors. Each of these organizations needs to exchange health data efficiently with the others to ensure care continuity […]

Building high-quality benchmark tests for Redshift using open-source tools: Best practices
Amazon Redshift is the most popular and fastest cloud data warehouse, offering seamless integration with your data lake, up to three times faster performance than any other cloud data warehouse, and up to 75% lower cost than any other cloud data warehouse. When you use Amazon Redshift to scale compute and storage independently, a need […]

Enabling multi-factor authentication for an Amazon Redshift cluster using Okta as an identity provider
December 2022: This post was reviewed and updated for accuracy. Many organizations have started using single sign-on (SSO) with multi-factor authentication (MFA) for enhanced security. This additional authentication factor is the new normal, which enhances the security provided by the user name and password model. Using SSO reduces the effort needed to maintain and remember […]

How Cookpad scaled its Amazon Redshift cluster while controlling costs with usage limits
This is a guest post by Shimpei Kodama, data engineer at Cookpad Inc. Cookpad is a tech company that builds a community platform where people share recipe ideas and cooking tips. The company’s mission is to “make everyday cooking fun.” It’s one of the largest recipe-sharing platforms in Japan with over 50 million users per […]
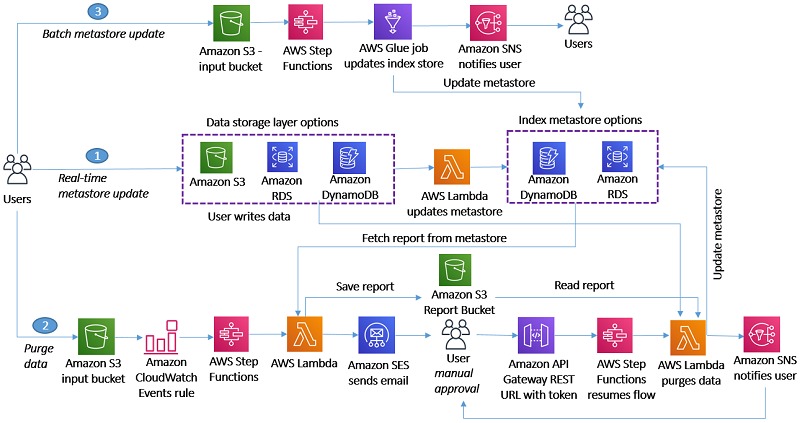
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]
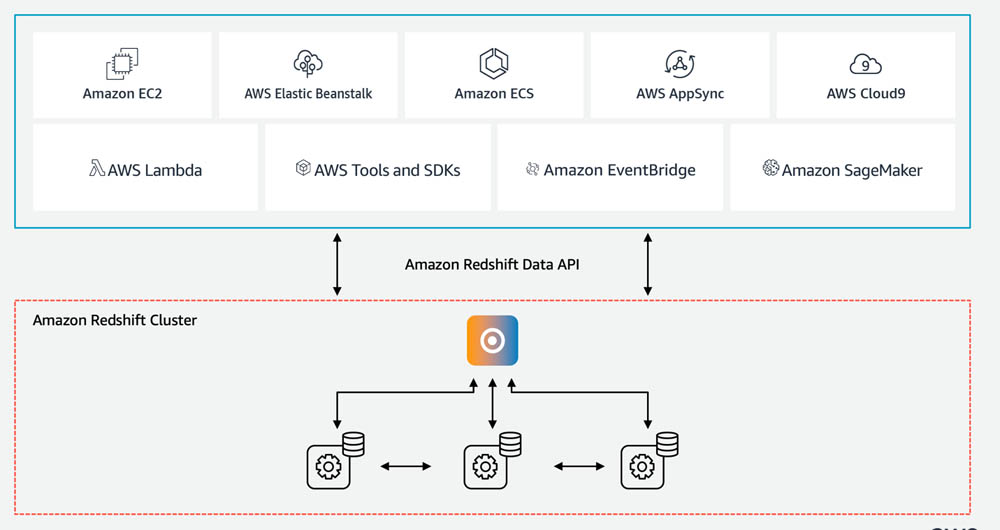
Using the Amazon Redshift Data API to interact with Amazon Redshift clusters
June 2023: This post was reviewed and updated for accuracy. July 2021: This post was reviewed and updated to include multi-statement and parameterization support. Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL […]
Zoopla drives KPIs with centralized data using Fivetran ELT for Amazon Redshift
This is a guest post by Steven Collings, Senior Data Consultant at Zoopla Zoopla is a property website that enables users to find residential or commercial property to buy or rent in the UK and overseas. Since acquiring Property Software Group and Expert Agent, we also offer a backend software that agents can use to […]
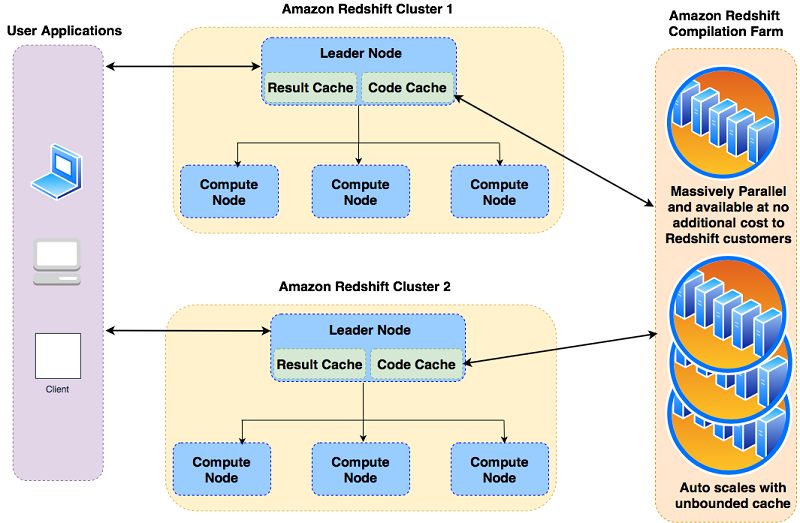
Fast and predictable performance with serverless compilation using Amazon Redshift
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Customers tell us that they want extremely fast query response times so they can make equally fast decisions. This post presents the recently launched, […]
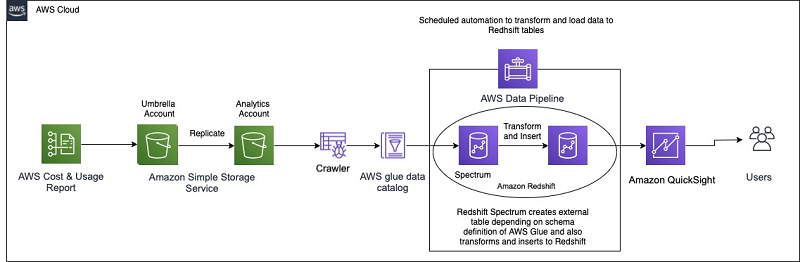
How Aruba Networks built a cost analysis solution using AWS Glue, Amazon Redshift, and Amazon QuickSight
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]