AWS Big Data Blog
Category: Amazon Redshift

Bringing machine learning to more builders through databases and analytics services
Machine learning (ML) is becoming more mainstream, but even with the increasing adoption, it’s still in its infancy. For ML to have the broad impact that we think it can have, it has to get easier to do and easier to apply. We launched Amazon SageMaker in 2017 to remove the challenges from each stage […]
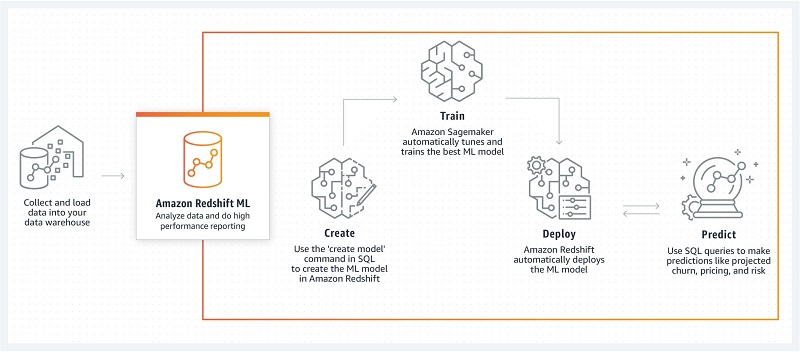
Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML
December 2022: Post was reviewed and updated to announce support of Prediction Probabilities for Classification problems using Amazon Redshift ML. Amazon Redshift is a fast, petabyte-scale cloud data warehouse data warehouse delivering the best price–performance. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. […]
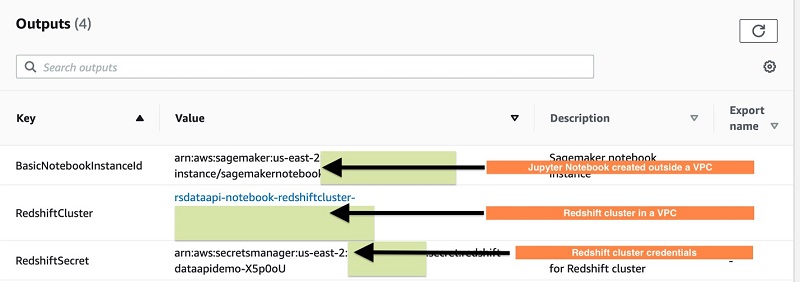
Using the Amazon Redshift Data API to interact from an Amazon SageMaker Jupyter notebook
June 2023: This post was reviewed for accuracy. The Amazon Redshift Data API makes it easy for any application written in Python, Go, Java, Node.JS, PHP, Ruby, and C++ to interact with Amazon Redshift. Traditionally, these applications use JDBC connectors to connect, send a query to run, and retrieve results from the Amazon Redshift cluster. […]

Migrating from Vertica to Amazon Redshift
Amazon Redshift powers analytical workloads for Fortune 500 companies, startups, and everything in between. With Amazon Redshift, you can query petabytes of structured and semi-structured data across your data warehouse, operational database, and your data lake using standard SQL. When you use Vertica, you have to install and upgrade Vertica database software and manage the […]

Building an event-driven application with AWS Lambda and the Amazon Redshift Data API
Event–driven applications are becoming popular with many customers, where applications run in response to events. A primary benefit of this architecture is the decoupling of producer and consumer processes, allowing greater flexibility in application design and building decoupled processes. An example of an even-driven application is an automated workflow being triggered by an event, which […]

Federated API access to Amazon Redshift using an Amazon Redshift connector for Python
July 2023: This post was reviewed for accuracy. Amazon Redshift is the leading cloud data warehouse that delivers performance 10 times faster at one-tenth of the cost of traditional data warehouses by using massively parallel query execution, columnar storage on high-performance disks, and results caching. You can confidently run mission-critical workloads, even in highly regulated […]

How the ZS COVID-19 Intelligence Engine helps Pharma & Med device manufacturers understand local healthcare needs & gaps at scale
This post is co-written by Parijat Sharma: Principal, Strategy & Transformation, Wenhao Xia: Manager, Data Science, Vineeth Sandadi: Manager, Business Consulting from ZS Associates, Inc, Arianna Tousi: Strategy, Insights and Planning Consultant from ZS, Gopi Vikranth: Associate Principal from ZS. In their own words, “We’re passionately committed to helping our clients and their customers thrive, […]
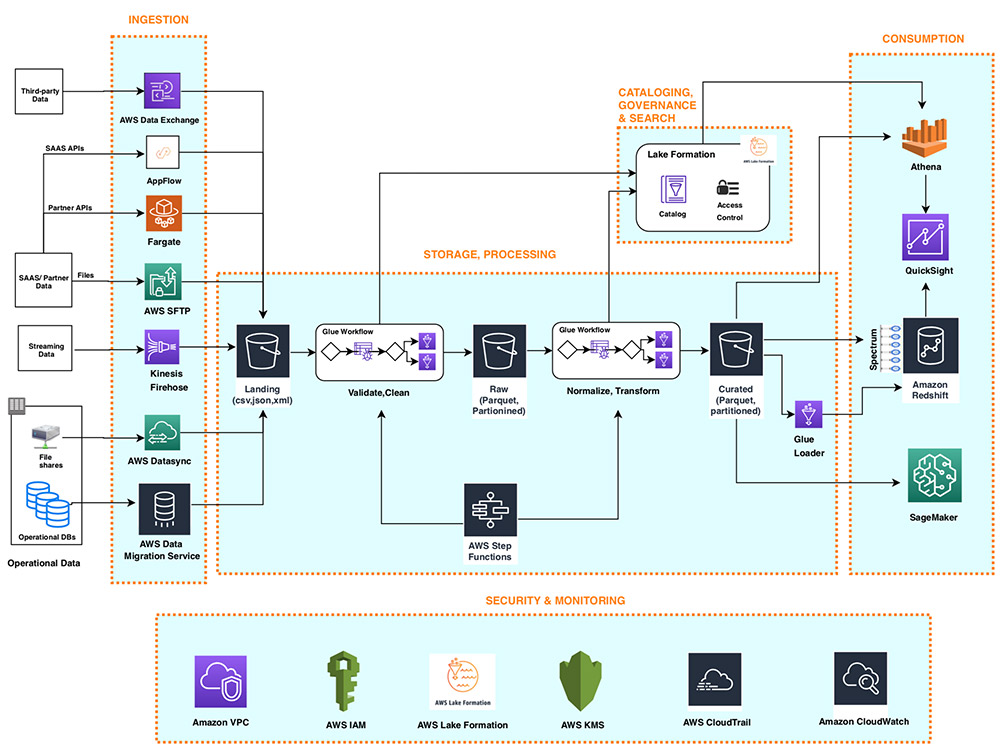
AWS serverless data analytics pipeline reference architecture
May 2022: This post was reviewed and updated to include additional resources for predictive analysis section. Onboarding new data or building new analytics pipelines in traditional analytics architectures typically requires extensive coordination across business, data engineering, and data science and analytics teams to first negotiate requirements, schema, infrastructure capacity needs, and workload management. For a […]

Automating DBA tasks on Amazon Redshift securely using AWS IAM, AWS Lambda, Amazon EventBridge, and stored procedures
As a data warehouse administrator or data engineer, you may need to perform maintenance tasks and activities or perform some level of custom monitoring on a regular basis. You can combine these activities inside a stored procedure or invoke views to get details. Some of these activities include things like loading nightly staging tables, invoking […]
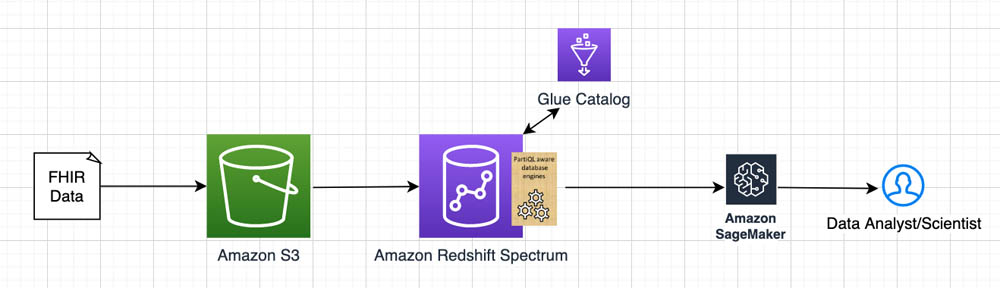
Analyzing healthcare FHIR data with Amazon Redshift PartiQL
Healthcare organizations across the globe strive to provide the best possible patient care at the lowest cost. In a patient’s care journey, multiple organizations are often involved, including the healthcare provider, diagnostic labs, pharmacies, and health insurance payors. Each of these organizations needs to exchange health data efficiently with the others to ensure care continuity […]