AWS Big Data Blog
Category: Amazon Redshift

Set up and manage data ingestion easily with Amazon Redshift native console integration with partners
We’re excited to announce that Amazon Redshift console partner integration is now generally available. This new console integration provides rapid provisioning and seamless integration with AWS partners. You can onboard with data integration partner solutions in less than a minute directly on the Amazon Redshift console, and ingest data from multiple data sources using partners’ […]

Enable private access to Amazon Redshift from your client applications in another VPC
November 2023: This post was reviewed and updated to include configurations and options for Amazon Redshift Serverless. You can now use an Amazon Redshift-managed VPC endpoint (powered by AWS PrivateLink) to connect to your private Amazon Redshift cluster with the RA3-instance type or Amazon Redshift Serverless within your virtual private cloud (VPC). With an Amazon […]

Build a DataOps platform to break silos between engineers and analysts
Organizations across the globe are striving to provide a better service to internal and external stakeholders by enabling various divisions across the enterprise, like customer success, marketing, and finance, to make data-driven decisions. Data teams are the key enablers in this process, and usually consist of multiple roles, such as data engineers and analysts. However, […]

Implementing multi-tenant patterns in Amazon Redshift using data sharing
Software service providers offer subscription-based analytics capabilities in the cloud with Analytics as a Service (AaaS), and increasingly customers are turning to AaaS for business insights. A multi-tenant storage strategy allows the service providers to build a cost-effective architecture to meet increasing demand. Multi-tenancy means a single instance of software and its supporting infrastructure is […]
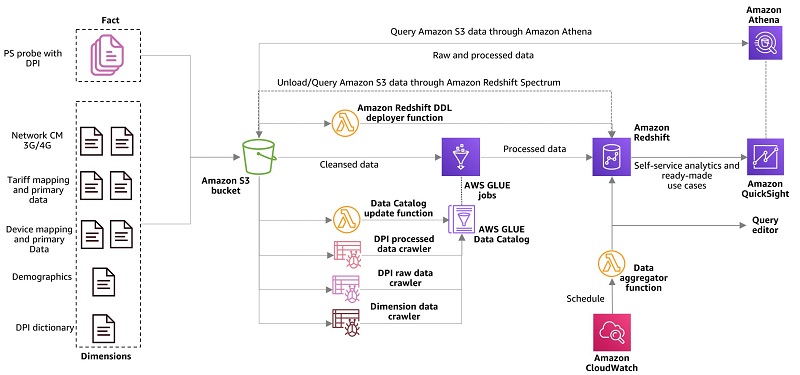
Data monetization and customer experience optimization using telco data assets: Part 2
Part 1 of this series explains the importance of building and implementing a customer experience (CX) management and data monetization strategy for telecom service providers (TSPs), and the major challenges driving these initiatives. It also includes an AWS CloudFormation template to set up a demonstration of the solution using AWS services. It covers transforming and enriching […]

Building a cost efficient, petabyte-scale lake house with Amazon S3 lifecycle rules and Amazon Redshift Spectrum: Part 2
In part 1 of this series, we demonstrated building an end-to-end data lifecycle management system integrated with a data lake house implemented on Amazon Simple Storage Service (Amazon S3) with Amazon Redshift and Amazon Redshift Spectrum. In this post, we address the ongoing operation of the solution we built. Data ageing process after a month […]

Amazon Redshift 2020 year in review
Today, more data is created every hour than in an entire year just 20 years ago. Successful organizations are leveraging this data to deliver better service to their customers, improve their products, and run an efficient and effective business. As the importance of data and analytics continues to grow, the Amazon Redshift cloud data warehouse […]
Building a cost efficient, petabyte-scale lake house with Amazon S3 lifecycle rules and Amazon Redshift Spectrum: Part 1
The continuous growth of data volumes combined with requirements to implement long-term retention (typically due to specific industry regulations) puts pressure on the storage costs of data warehouse solutions, even for cloud native data warehouse services such as Amazon Redshift. The introduction of the new Amazon Redshift RA3 node types helped in decoupling compute from […]

Running queries securely from the same VPC where an Amazon Redshift cluster is running
Customers who don’t need to set up a VPN or a private connection to AWS often use public endpoints to access AWS. Although this is acceptable for testing out the services, most production workloads need a secure connection to their VPC on AWS. If you’re running your production data warehouse on Amazon Redshift, you can […]
Scheduling SQL queries on your Amazon Redshift data warehouse
Amazon Redshift is the most popular cloud data warehouse today, with tens of thousands of customers collectively processing over 2 exabytes of data on Amazon Redshift daily. Amazon Redshift is fully managed, scalable, secure, and integrates seamlessly with your data lake. In this post, we discuss how to set up and use the new query […]