AWS Big Data Blog
Category: Amazon Redshift
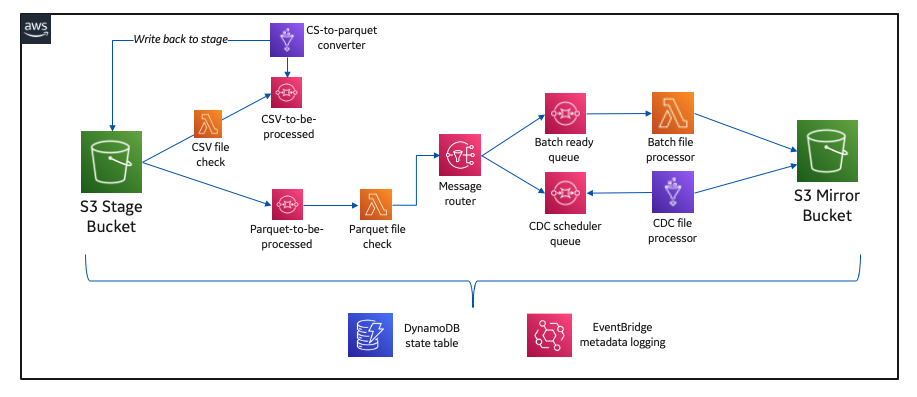
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platform
This post was co-written with Alcuin Weidus, Principal Architect from GE Aviation. GE Aviation, an operating unit of GE, is a world-leading provider of jet and turboprop engines, as well as integrated systems for commercial, military, business, and general aviation aircraft. GE Aviation has a global service network to support these offerings. From the turbosupercharger […]

Apply CI/CD DevOps principles to Amazon Redshift development
CI/CD in the context of application development is a well-understood topic, and developers can choose from numerous patterns and tools to build their pipelines to handle the build, test, and deploy cycle when a new commit gets into version control. For stored procedures or even schema changes that are directly related to the application, this […]

Accelerate self-service analytics with Amazon Redshift Query Editor V2
August 2023: This post was reviewed and updated with new features. Amazon Redshift is a fast, fully managed cloud data warehouse. Tens of thousands of customers use Amazon Redshift as their analytics platform. Users such as data analysts, database developers, and data scientists use SQL to analyze their data in Amazon Redshift data warehouses. Amazon […]

Query hierarchical data models within Amazon Redshift
In a hierarchical database model, information is stored in a tree-like structure or parent-child structure, where each record can have a single parent but many children. Hierarchical databases are useful when you need to represent data in a tree-like hierarchy. The perfect example of a hierarchical data model is the navigation file and folders or […]

Now Available: Updated guidance on the Data Analytics Lens for AWS Well-Architected Framework
Nearly all businesses today require some form of data analytics processing, from auditing user access to generating sales reports. For all your analytics needs, the Data Analytics Lens for AWS Well-Architected Framework provides prescriptive guidance to help you assess your workloads and identify best practices aligned to the AWS Well-Architected Pillars: Operational Excellence, Security, Reliability, […]
Cybersecurity Awareness Month: Learn about the job zero of securing your data using Amazon Redshift
Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price-performance. It allows you to run complex analytic queries against terabytes to petabytes of structured and semi-structured data, using sophisticated query optimization, columnar on high-performance storage, and massively parallel query execution. At AWS, we embrace the culture that security is job zero, by […]

Stream data from relational databases to Amazon Redshift with upserts using AWS Glue streaming jobs
Traditionally, read replicas of relational databases are often used as a data source for non-online transactions of web applications such as reporting, business analysis, ad hoc queries, operational excellence, and customer services. Due to the exponential growth of data volume, it became common practice to replace such read replicas with data warehouses or data lakes […]
Automate Amazon Redshift Cluster management operations using AWS CloudFormation
Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price-performance. Tens of thousands of customers run business-critical workloads on Amazon Redshift. Amazon Redshift offers many features that enable you to build scalable, highly performant, cost-effective, and easy-to-manage workloads. For example, you can scale an Amazon Redshift cluster up or down based on […]

Compare different node types for your workload using Amazon Redshift
February 2023: This post was reviewed and updated to include support for Amazon Redshift Serverless. The Amazon Redshift Node Configuration Comparison utility latest release now supports Amazon Redshift Serverless to test your workload performance. If you want to either explore different Amazon Redshift Serverless configurations or combination of Amazon Redshift Provisioned and Serverless configurations based […]

Migrate to an Amazon Redshift Lake House Architecture from Snowflake
The need to derive meaningful and timely insights increases proportionally with the amount of data being collected. Data warehouses play a key role in storing, transforming, and making data easily accessible to enable a wide range of use cases, such as data mining, business intelligence (BI) and reporting, and diagnostics, as well as predictive, prescriptive, […]