AWS Big Data Blog
Category: Amazon Redshift
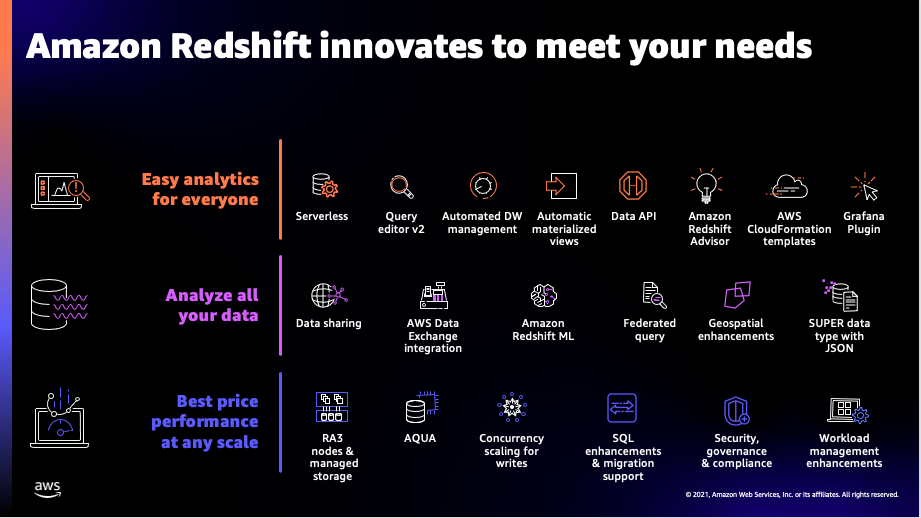
What’s new in Amazon Redshift – 2021, a year in review
Amazon Redshift is the cloud data warehouse of choice for tens of thousands of customers who use it to analyze exabytes of data to gain business insights. Customers have asked for more capabilities in Redshift to make it easier, faster, and secure to store, process, and analyze all of their data. We announced Redshift in 2012 […]

Introducing new features for Amazon Redshift COPY: Part 1
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of […]
Use the default IAM role in Amazon Redshift to simplify accessing other AWS services
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse, and can expand to petabyte scale. Today, tens of thousands of AWS […]
Use unsupervised training with K-means clustering in Amazon Redshift ML
June 2023: This post was reviewed and updated for accuracy. Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price–performance. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Data analysts and database developers want to use this data to train […]
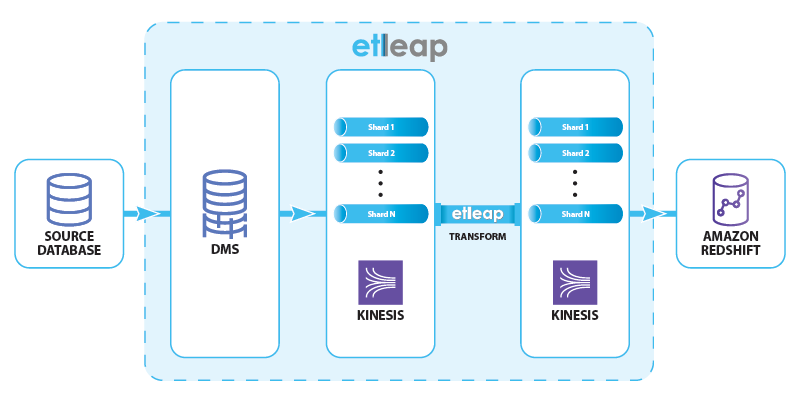
Integrate Etleap with Amazon Redshift Streaming Ingestion (preview) to make data available in seconds
Amazon Redshift is a fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using SQL and your extract, transform, and load (ETL), business intelligence (BI), and reporting tools. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics workloads. Etleap […]

Security considerations for Amazon Redshift cross-account data sharing
Data driven organizations recognize the intrinsic value of data and realize that monetizing data is not just about selling data to subscribers. They understand the indirect economic impact of data and the value that good data brings to the organization. They must democratize data and make it available for business decision makers to realize its […]
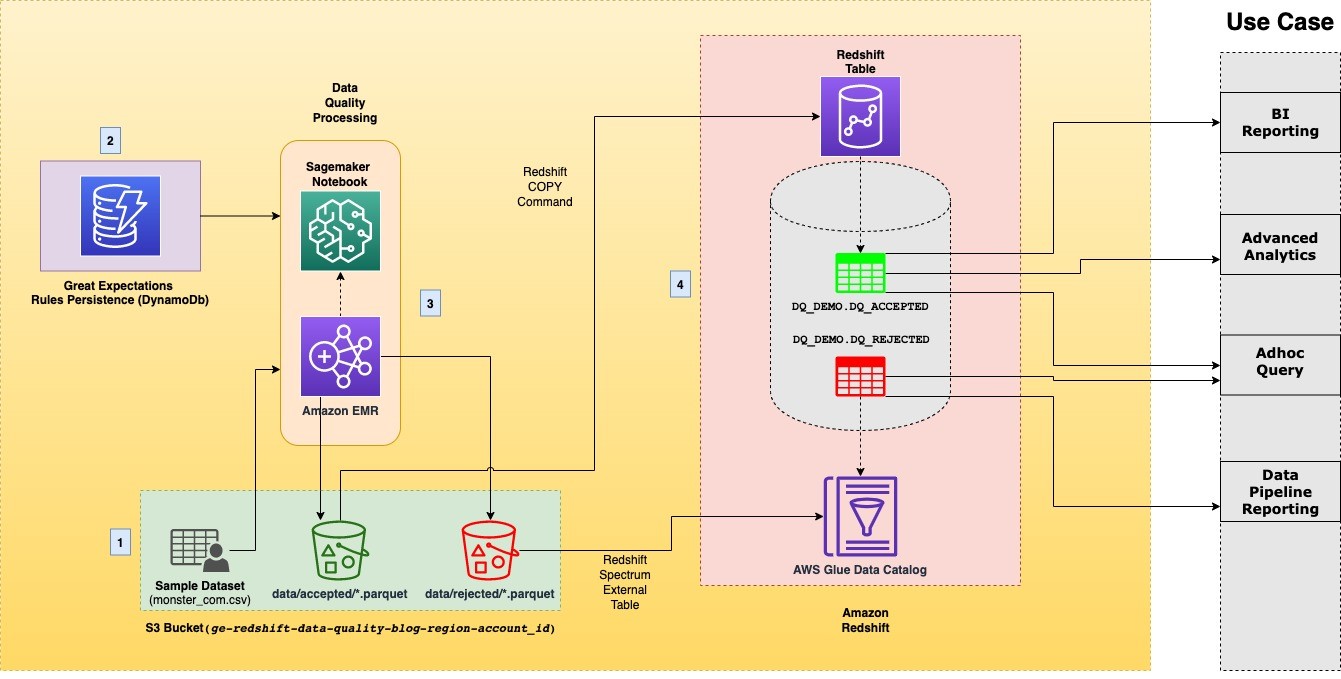
Provide data reliability in Amazon Redshift at scale using Great Expectations library
Ensuring data reliability is one of the key objectives of maintaining data integrity and is crucial for building data trust across an organization. Data reliability means that the data is complete and accurate. It’s the catalyst for delivering trusted data analytics and insights. Incomplete or inaccurate data leads business leaders and data analysts to make […]

Design and build a Data Vault model in Amazon Redshift from a transactional database
This blog post was updated in June, 2022 to update the entity relationship diagram. Building a highly performant data model for an enterprise data warehouse (EDW) has historically involved significant design, development, administration, and operational effort. Furthermore, the data model must be agile and adaptable to change while handling the largest volumes of data efficiently. […]

Federate Amazon Redshift access with SecureAuth single sign-on
Amazon Redshift is the leading cloud data warehouse that delivers up to 3x better price performance compared to other cloud data warehouses by using massively parallel query execution, columnar storage on high-performance disks, and results caching. You can confidently run mission-critical workloads, even in highly regulated industries, because Amazon Redshift comes with out-of-the-box security and […]
Use the Amazon Redshift SQLAlchemy dialect to interact with Amazon Redshift
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that enables you to analyze your data at scale. You can interact with an Amazon Redshift database in several different ways. One method is using an object-relational mapping (ORM) framework. ORM is widely used by developers as an abstraction layer upon the […]