AWS Big Data Blog
Category: Amazon Redshift

How ENGIE scales their data ingestion pipelines using Amazon MWAA
ENGIE—one of the largest utility providers in France and a global player in the zero-carbon energy transition—produces, transports, and deals electricity, gas, and energy services. With 160,000 employees worldwide, ENGIE is a decentralized organization and operates 25 business units with a high level of delegation and empowerment. ENGIE’s decentralized global customer base had accumulated lots […]

Build a modern data architecture on AWS with Amazon AppFlow, AWS Lake Formation, and Amazon Redshift: Part 2
In Part 1 of this post, we provided a solution to build the sourcing, orchestration, and transformation of data from multiple source systems, including Salesforce, SAP, and Oracle, into a managed modern data platform. Roche partnered with AWS Professional Services to build out this fully automated and scalable platform to provide the foundation for their […]

Best practices to optimize your Amazon Redshift and MicroStrategy deployment
This is a guest blog post co-written by Amit Nayak at Microstrategy. In their own words, “MicroStrategy is the largest independent publicly traded business intelligence (BI) company, with the leading enterprise analytics platform. Our vision is to enable Intelligence Everywhere. MicroStrategy provides modern analytics on an open, comprehensive enterprise platform used by many of the […]
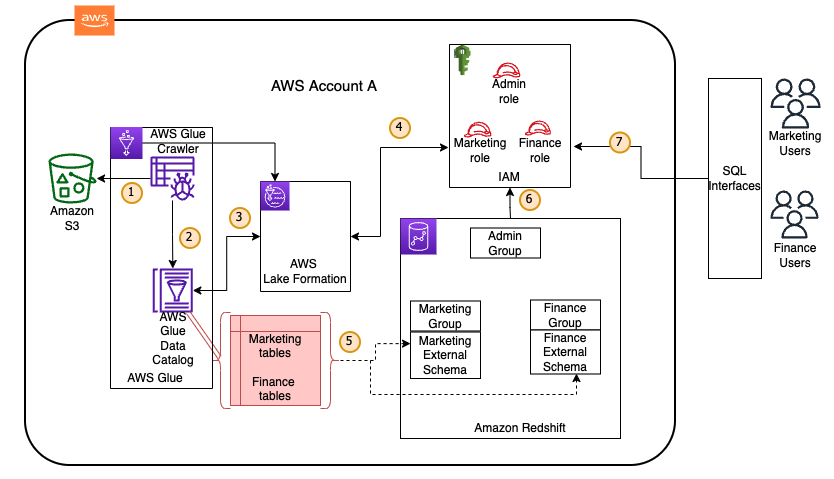
Centralize governance for your data lake using AWS Lake Formation while enabling a modern data architecture with Amazon Redshift Spectrum
Many customers are modernizing their data architecture using Amazon Redshift to enable access to all their data from a central data location. They are looking for a simpler, scalable, and centralized way to define and enforce access policies on their data lakes on Amazon Simple Storage Service (Amazon S3). They want access policies to allow […]
Define error handling for Amazon Redshift Spectrum data
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift Spectrum allows you to query open format data directly from the Amazon Simple Storage Service (Amazon S3) data lake without having to load the data into Amazon Redshift tables. With Redshift Spectrum, you can query open file formats such as […]

Set up cross-account audit logging for your Amazon Redshift cluster
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. One of the best practices of modern application design is to have centralized logging. Troubleshooting application problems is easy when you can correlate […]
Federate access to Amazon Redshift using the JDBC browser plugin for Single Sign-on authentication with Microsoft Azure Active Directory
Since 2020, Amazon Redshift has supported multi-factor authentication (MFA) to any SAML 2.0 compliant identity provider (IdP) in our JDBC and ODBC drivers. You can map the IdP user identity and group memberships in order to control authorization for database objects in Amazon Redshift. This simplifies administration by enabling you to manage user access in […]
Optimize your analytical workloads using the automatic query rewrite feature of Amazon Redshift materialized views
Amazon Redshift materialized views enable you to significantly improve performance of complex queries that are frequently run as part of your extract, load, and transform (ELT), business intelligence (BI), or dashboarding applications. Materialized views precompute and store the result sets of the SQL query in the view definition. Materialized views speed up data access, because […]

Power highly resilient use cases with Amazon Redshift
Amazon Redshift is the most popular and fastest cloud data warehouse, offering seamless integration with your data lake and other data sources, up to three times faster performance than any other cloud data warehouse, automated maintenance, separation of storage and compute, and up to 75% lower cost than any other cloud data warehouse. This post […]
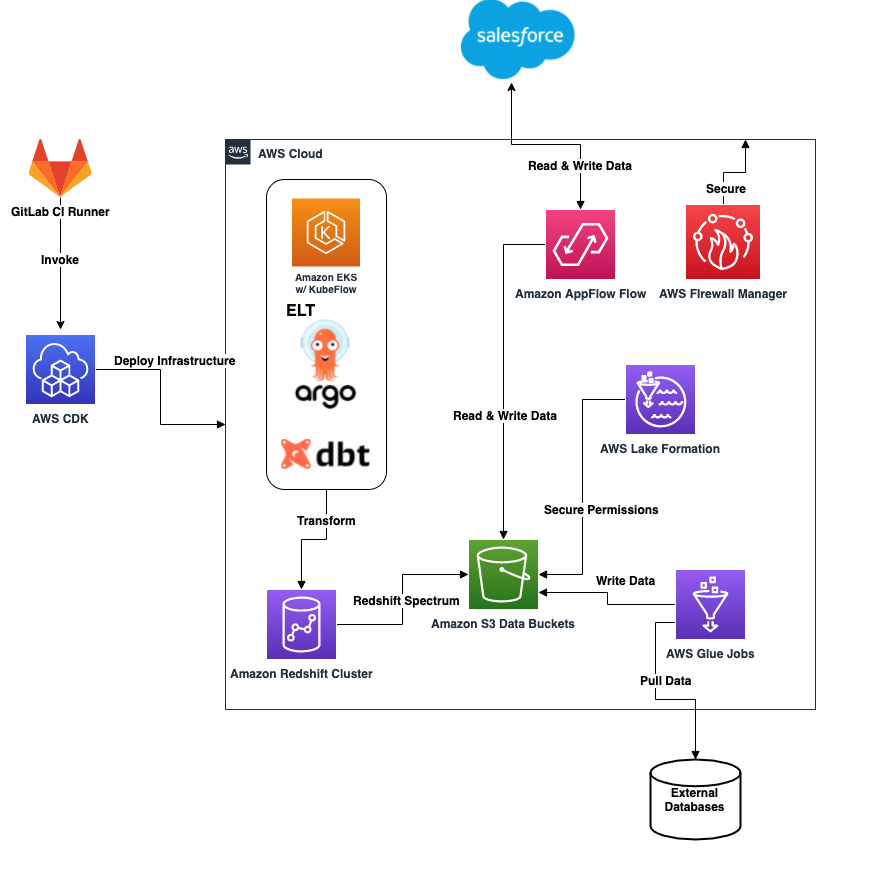
Build a modern data architecture on AWS with Amazon AppFlow, AWS Lake Formation, and Amazon Redshift
This is a guest post written by Dr. Yannick Misteli, lead cloud platform and ML engineering in global product strategy (GPS) at Roche. Recently the Roche Data Insights (RDI) initiative was launched to achieve our vision using new ways of working and collaboration in order to build shared, interoperable data & insights with federated governance. […]