AWS Big Data Blog
Category: Amazon Redshift
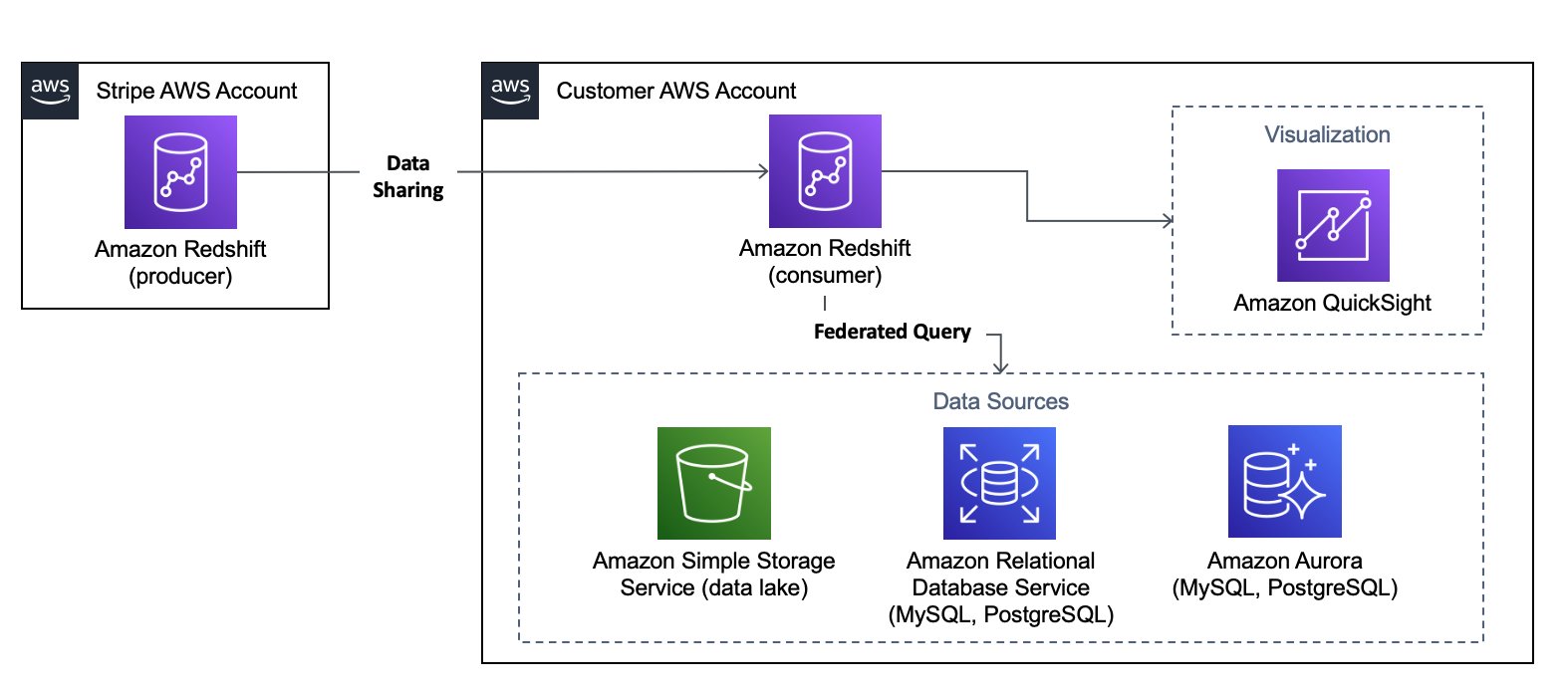
Ingest Stripe data in a fast and reliable way using Stripe Data Pipeline for Amazon Redshift
Enterprises typically host a myriad of business applications for varying data needs. As companies grow, so does the demand for insights from a complete set of business data. Having data from various applications that store data in disparate silos can delay the decision-making process. However, building and maintaining an API integration or a third-party extract, […]

Use a linear learner algorithm in Amazon Redshift ML to solve regression and classification problems
July 2024: This post was reviewed and updated for accuracy. Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price–performance. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Amazon Redshift ML, powered by Amazon SageMaker, makes it easy for SQL […]

Federate single sign-on access to Amazon Redshift query editor v2 with Okta
Amazon Redshift query editor v2 is a web-based SQL client application that you can use to author and run queries on your Amazon Redshift data warehouse. You can visualize query results with charts and collaborate by sharing queries with members of your team. You can use query editor v2 to create databases, schemas, tables, and […]
Federate access to Amazon Redshift query editor V2 with Active Directory Federation Services (AD FS): Part 3
In the first post of this series, Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS): Part 1, you set up Microsoft Active Directory Federation Services (AD FS) and Security Assertion Markup Language (SAML) based authentication and tested the SAML federation using a web browser. In Part 2, you learned […]
Analyze Amazon SES events at scale using Amazon Redshift
Email is one of the most important methods for business communication across many organizations. It’s also one of the primary methods for many businesses to communicate with their customers. With the ever-increasing necessity to send emails at scale, monitoring and analysis has become a major challenge. Amazon Simple Email Service (Amazon SES) is a cost-effective, […]

Build a big data Lambda architecture for batch and real-time analytics using Amazon Redshift
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. With real-time information about customers, products, and applications in hand, organizations can take action as events happen in their business application. For example, you can prevent financial fraud, deliver personalized offers, and […]

Secure data movement across Amazon S3 and Amazon Redshift using role chaining and ASSUMEROLE
Data lakes use a ring of purpose-built data services around a central data lake. Data needs to move between these services and data stores easily and securely. The following are some examples of such services: Amazon Simple Storage Service (Amazon S3), which stores structured, unstructured, and semi-structured data Amazon Redshift, a fully managed, petabyte-scale data […]

Real-time analytics with Amazon Redshift streaming ingestion
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. […]

Modernize your healthcare clinical quality data repositories with Amazon Redshift Data Vault
With the shift to value-based care, tapping data to its fullest to improve patient satisfaction tops the priority of healthcare executives everywhere. To achieve this, reliance on key technology relevant to their sphere is a must. This is where data lakes can help. A data lake is an architecture that can assist providers in storing, […]

Scale Amazon Redshift to meet high throughput query requirements
August 2024: This post was reviewed and updated for accuracy. Many enterprise customers have demanding query throughput requirements for their data warehouses. Some may be able to address these requirements through horizontally or vertically scaling a single cluster. Others may have a short duration where they need extra capacity to handle peaks that can be […]