AWS Big Data Blog
Category: Amazon Redshift
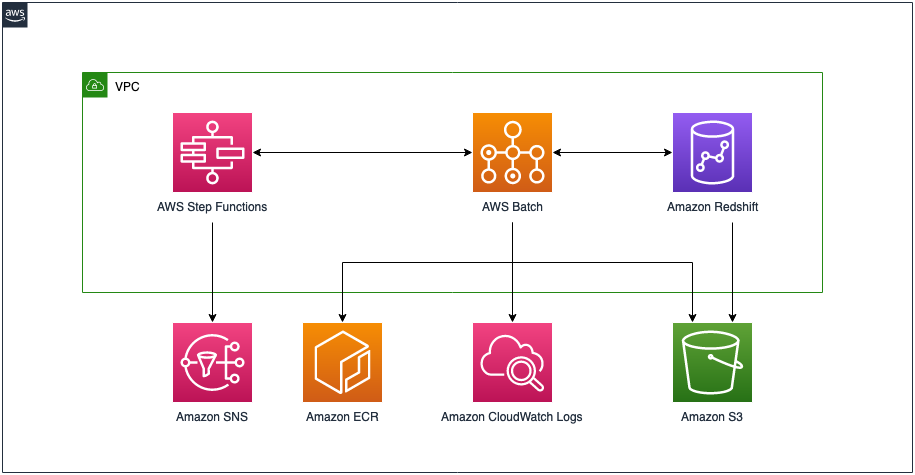
Develop an Amazon Redshift ETL serverless framework using RSQL, AWS Batch, and AWS Step Functions
Amazon Redshift RSQL is a command-line client for interacting with Amazon Redshift clusters and databases. You can connect to an Amazon Redshift cluster, describe database objects, query data, and view query results in various output formats. You can use enhanced control flow commands to replace existing extract, transform, load (ETL) and automation scripts. This post […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]

Use SQL queries to define Amazon Redshift datasets in AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. In the post Data preparation using Amazon Redshift with AWS Glue DataBrew, we saw how to create an AWS Glue DataBrew job using a JDBC connection for Amazon Redshift. In this post, we show you how to create a DataBrew profile job and a recipe job using […]
Accelerate your data warehouse migration to Amazon Redshift – Part 6
This is the sixth in a series of posts. We’re excited to share dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially simplify your migrations from legacy data warehouses to Amazon Redshift. Check out all the previous posts in this series: […]

Create a most-recent view of your data lake using Amazon Redshift Serverless
Building a robust data lake is very beneficial because it enables organizations have a holistic view of their business and empowers data-driven decisions. The curated layer of a data lake is able to hydrate multiple homogeneous data products, unlocking limitless capabilities to address current and future requirements. However, some concepts of how data lakes work […]

Simplify analytics on Amazon Redshift using PIVOT and UNPIVOT
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Many customers look to build their data warehouse on Amazon Redshift, and they have many requirements where they want to convert data from row […]

Integrate Amazon Redshift row-level security with Amazon Redshift native IdP authentication
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. As enterprise customers look to build their data […]

Migrate a large data warehouse from Greenplum to Amazon Redshift using AWS SCT – Part 2
In this second post of a multi-part series, we share best practices for choosing the optimal Amazon Redshift cluster, data architecture, converting stored procedures, compatible functions and queries widely used for SQL conversions, and recommendations for optimizing the length of data types for table columns. You can check out the first post of this series […]
Migrate a large data warehouse from Greenplum to Amazon Redshift using AWS SCT – Part 1
A data warehouse collects and consolidates data from various sources within your organization. It’s used as a centralized data repository for analytics and business intelligence. When working with on-premises legacy data warehouses, scaling the size of your data warehouse or improving performance can mean purchasing new hardware or adding more powerful hardware. This is often […]

Accelerate resizing of Amazon Redshift clusters with enhancements to classic resize
October 2023: This post was reviewed and updated to include the latest enhancements in Amazon Redshift’s resize feature. Amazon Redshift has improved the performance of the classic resize feature for multi-node RA3 clusters and increased the flexibility of the cluster snapshot restore operation. You can use the classic resize operation to resize a cluster when […]