AWS Big Data Blog
Category: Amazon Redshift

Get maximum value out of your cloud data warehouse with Amazon Redshift
Every day, customers are challenged with how to manage their growing data volumes and operational costs to unlock the value of data for timely insights and innovation, while maintaining consistent performance. Data creation, consumption, and storage are predicted to grow to 175 zettabytes by 2025, forecasted by the 2022 IDC Global DataSphere report. As data […]

Implement column-level encryption to protect sensitive data in Amazon Redshift with AWS Glue and AWS Lambda user-defined functions
Amazon Redshift is a massively parallel processing (MPP), fully managed petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data using existing business intelligence tools. When businesses are modernizing their data warehousing solutions to Amazon Redshift, implementing additional data protection mechanisms for sensitive data, such as personally identifiable information (PII) or […]

Generic orchestration framework for data warehousing workloads using Amazon Redshift RSQL
Tens of thousands of customers run business-critical workloads on Amazon Redshift, AWS’s fast, petabyte-scale cloud data warehouse delivering the best price-performance. With Amazon Redshift, you can query data across your data warehouse, operational data stores, and data lake using standard SQL. You can also integrate AWS services like Amazon EMR, Amazon Athena, Amazon SageMaker, AWS […]

Manage your data warehouse cost allocations with Amazon Redshift Serverless tagging
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your data warehouse infrastructure. Developers, data scientists, and analysts can work across databases, data warehouses, and data lakes to build reporting and dashboarding applications, perform real-time analytics, share and collaborate on data, and even build and train machine learning (ML) […]

How SafetyCulture scales unpredictable dbt Cloud workloads in a cost-effective manner with Amazon Redshift
This post is co-written by Anish Moorjani, Data Engineer at SafetyCulture. SafetyCulture is a global technology company that puts the power of continuous improvement into everyone’s hands. Its operations platform unlocks the power of observation at scale, giving leaders visibility and workers a voice in driving quality, efficiency, and safety improvements. Amazon Redshift is a […]

Simplify data loading into Type 2 slowly changing dimensions in Amazon Redshift
Thousands of customers rely on Amazon Redshift to build data warehouses to accelerate time to insights with fast, simple, and secure analytics at scale and analyze data from terabytes to petabytes by running complex analytical queries. Organizations create data marts, which are subsets of the data warehouse and usually oriented for gaining analytical insights specific […]

How gaming companies can use Amazon Redshift Serverless to build scalable analytical applications faster and easier
This post provides guidance on how to build scalable analytical solutions for gaming industry use cases using Amazon Redshift Serverless. It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. This post […]

How Tricentis unlocks insights across the software development lifecycle at speed and scale using Amazon Redshift
This is a guest post co-written with Parag Doshi, Guru Havanur, and Simon Guindon from Tricentis. Tricentis is a global leader in continuous testing for DevOps, cloud, and enterprise applications. It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more […]
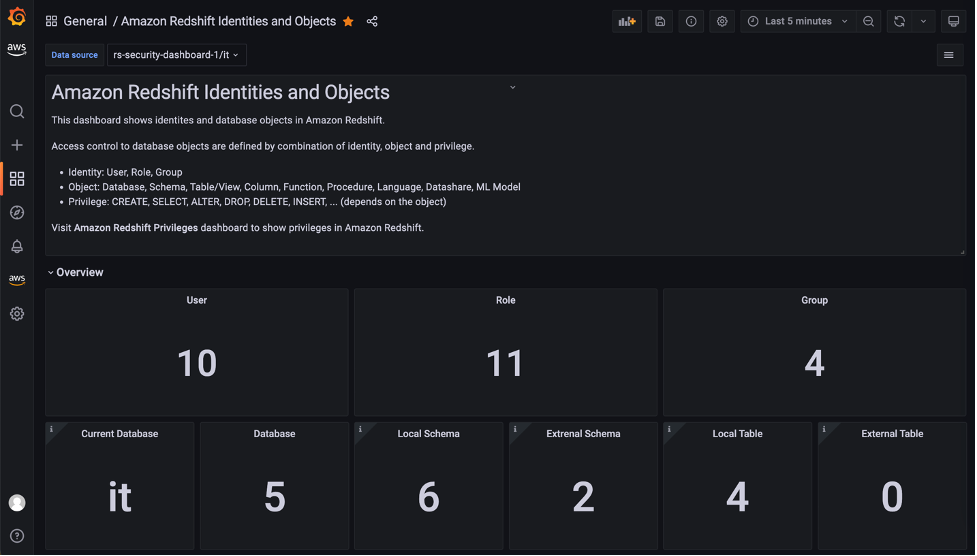
Visualize database privileges on Amazon Redshift using Grafana
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift enables you to use SQL for analyzing structured and semi-structured data with best price performance along with secure access to the data. As more users start querying data in a data warehouse, access control is paramount to protect valuable organizational […]

Simplify Online Analytical Processing (OLAP) queries in Amazon Redshift using new SQL constructs such as ROLLUP, CUBE, and GROUPING SETS
Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. We are continuously investing to make analytics easy with Redshift by simplifying SQL constructs and adding new operators. Now we are adding […]