AWS Big Data Blog
Category: Amazon EMR

Define per-team resource limits for big data workloads using Amazon EMR Serverless
Customers face a challenge when distributing cloud resources between different teams running workloads such as development, testing, or production. The resource distribution challenge also occurs when you have different line-of-business users. The objective is not only to ensure sufficient resources be consistently available to production workloads and critical teams, but also to prevent adhoc jobs […]

Query big data with resilience using Trino in Amazon EMR with Amazon EC2 Spot Instances for less cost
New enhancements in Trino with Amazon EMR provide improved resiliency for running ETL and batch workloads on Spot Instances with reduced costs. This post showcases the resilience of Amazon EMR with Trino using fault-tolerant configuration to run long-running queries on Spot Instances to save costs. We simulate Spot interruptions on Trino worker nodes by using AWS Fault Injection Simulator (AWS FIS).

Apache Iceberg optimization: Solving the small files problem in Amazon EMR
Currently, Iceberg provides a compaction utility that compacts small files at a table or partition level. But this approach requires you to implement the compaction job using your preferred job scheduler or manually triggering the compaction job. In this post, we discuss the new Iceberg feature that you can use to automatically compact small files while writing data into Iceberg tables using Spark on Amazon EMR or Amazon Athena.

Capacity Management and Amazon EMR Managed Scaling improvements for Amazon EMR on EC2 clusters
In 2022, we told you about the new enhancements we made in Amazon EMR Managed Scaling, which helped improve cluster utilization as well as reduced cluster costs. In 2023, we are happy to report that the Amazon EMR team has been hard at work. We worked backward from customer requirements and launched multiple new features to enhance your Amazon EMR on EC2 clusters capacity management and scaling experience. Let’s dive deeper and discuss the new Amazon EMR on EC2 features in detail.

Monitor Apache Spark applications on Amazon EMR with Amazon Cloudwatch
To improve a Spark application’s efficiency, it’s essential to monitor its performance and behavior. In this post, we demonstrate how to publish detailed Spark metrics from Amazon EMR to Amazon CloudWatch. This will give you the ability to identify bottlenecks while optimizing resource utilization.

Improved scalability and resiliency for Amazon EMR on EC2 clusters
Amazon EMR is the cloud big data solution for petabyte-scale data processing, interactive analytics, and machine learning using open-source frameworks such as Apache Spark, Apache Hive, and Presto. Customers asked us for features that would further improve the resiliency and scalability of their Amazon EMR on EC2 clusters, including their large, long-running clusters. We have […]

Orca Security’s journey to a petabyte-scale data lake with Apache Iceberg and AWS Analytics
This post is co-written with Eliad Gat and Oded Lifshiz from Orca Security. With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. One key component that plays a central role in modern data architectures is the data lake, which allows organizations to […]

Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance. Index rebalancing arbitrage takes advantage of short-term price discrepancies resulting from ETF managers’ efforts to […]
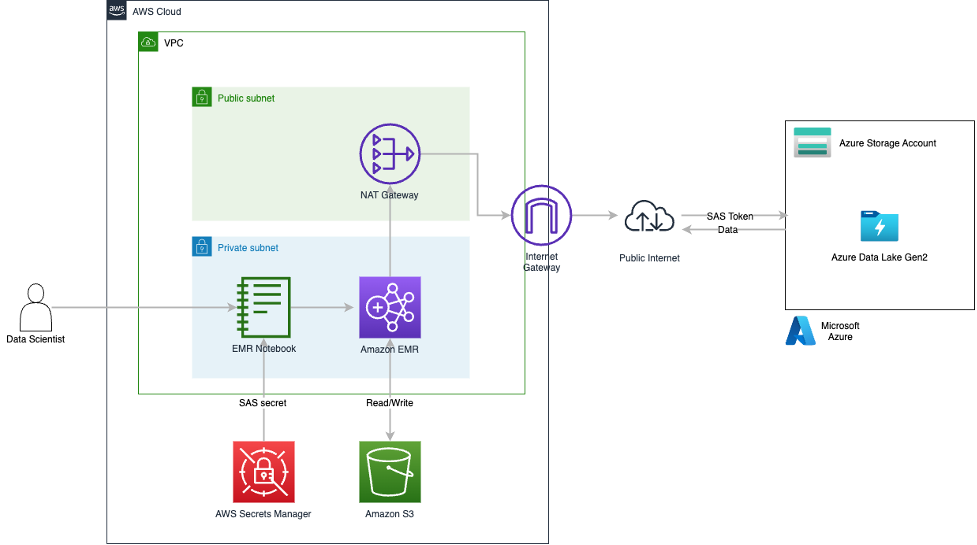
Enable remote reads from Azure ADLS with SAS tokens using Spark in Amazon EMR
Organizations use data from many sources to understand, analyze, and grow their business. These data sources are often spread across various public cloud providers. Enterprises may also expand their footprint by mergers and acquisitions, and during such events they often end up with data spread across different public cloud providers. These scenarios can create the […]
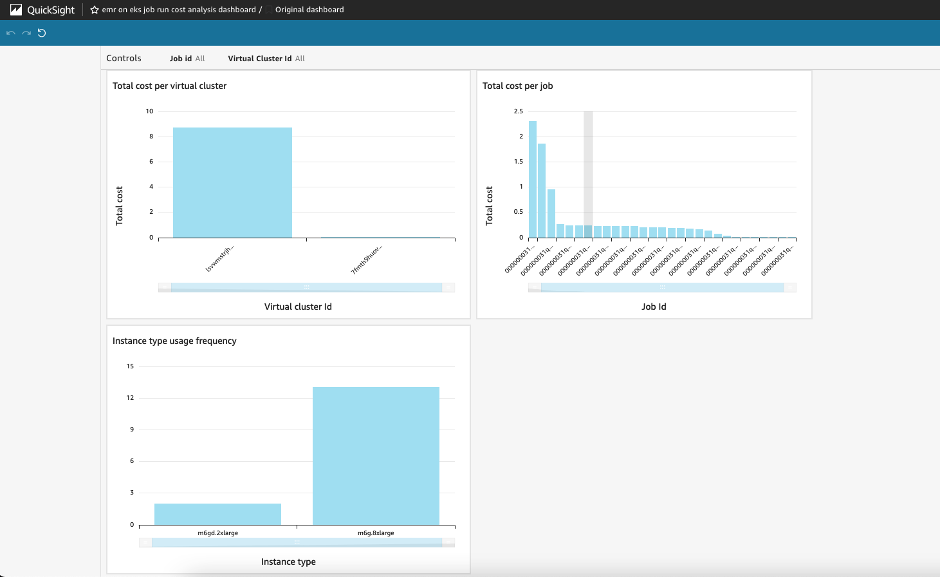
Cost monitoring for Amazon EMR on Amazon EKS
Amazon EMR is the industry-leading cloud big data solution, providing a collection of open-source frameworks such as Spark, Hive, Hudi, and Presto, fully managed and with per-second billing. Amazon EMR on Amazon EKS is a deployment option allowing you to deploy Amazon EMR on the same Amazon Elastic Kubernetes Service (Amazon EKS) clusters that is […]