AWS Big Data Blog
Category: Amazon EMR

How the GoDaddy data platform achieved over 60% cost reduction and 50% performance boost by adopting Amazon EMR Serverless
This is a guest post co-written with Brandon Abear, Dinesh Sharma, John Bush, and Ozcan IIikhan from GoDaddy. GoDaddy empowers everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their ideas, build a professional website, attract customers, […]

Build a pseudonymization service on AWS to protect sensitive data: Part 2
Part 1 of this two-part series described how to build a pseudonymization service that converts plain text data attributes into a pseudonym or vice versa. A centralized pseudonymization service provides a unique and universally recognized architecture for generating pseudonyms. Consequently, an organization can achieve a standard process to handle sensitive data across all platforms. Additionally, […]

Bring your workforce identity to Amazon EMR Studio and Athena
September 2025: This post was updated for accuracy. Customers today may struggle to implement proper access controls and auditing at the user level when multiple applications are involved in data access workflows. The key challenge is to implement proper least-privilege access controls based on user identity when one application accesses data on behalf of the […]

Simplify authentication with native LDAP integration on Amazon EMR
Many companies have corporate identities stored inside identity providers (IdPs) like Active Directory (AD) or OpenLDAP. Previously, customers using Amazon EMR could integrate their clusters with Active Directory by configuring a one-way realm trust between their AD domain and the EMR cluster Kerberos realm. For more details, refer to Tutorial: Configure a cross-realm trust with […]

Preprocess and fine-tune LLMs quickly and cost-effectively using Amazon EMR Serverless and Amazon SageMaker
Large language models (LLMs) are becoming increasing popular, with new use cases constantly being explored. In general, you can build applications powered by LLMs by incorporating prompt engineering into your code. However, there are cases where prompting an existing LLM falls short. This is where model fine-tuning can help. Prompt engineering is about guiding the […]

Enforce fine-grained access control on Open Table Formats via Amazon EMR integrated with AWS Lake Formation
With Amazon EMR 6.15, we launched AWS Lake Formation based fine-grained access controls (FGAC) on Open Table Formats (OTFs), including Apache Hudi, Apache Iceberg, and Delta lake. This allows you to simplify security and governance over transactional data lakes by providing access controls at table-, column-, and row-level permissions with your Apache Spark jobs. Many […]

Orchestrate Amazon EMR Serverless Spark jobs with Amazon MWAA, and data validation using Amazon Athena
As data engineering becomes increasingly complex, organizations are looking for new ways to streamline their data processing workflows. Many data engineers today use Apache Airflow to build, schedule, and monitor their data pipelines. However, as the volume of data grows, managing and scaling these pipelines can become a daunting task. Amazon Managed Workflows for Apache […]

Use Amazon EMR with S3 Access Grants to scale Spark access to Amazon S3
Amazon EMR is pleased to announce integration with Amazon Simple Storage Service (Amazon S3) Access Grants that simplifies Amazon S3 permission management and allows you to enforce granular access at scale. With this integration, you can scale job-based Amazon S3 access for Apache Spark jobs across all Amazon EMR deployment options and enforce granular Amazon […]
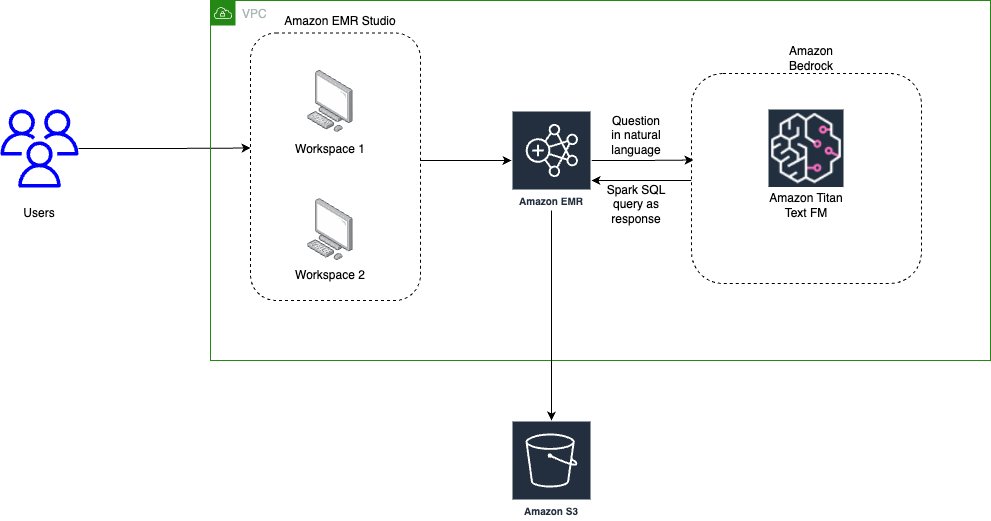
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently. Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine […]
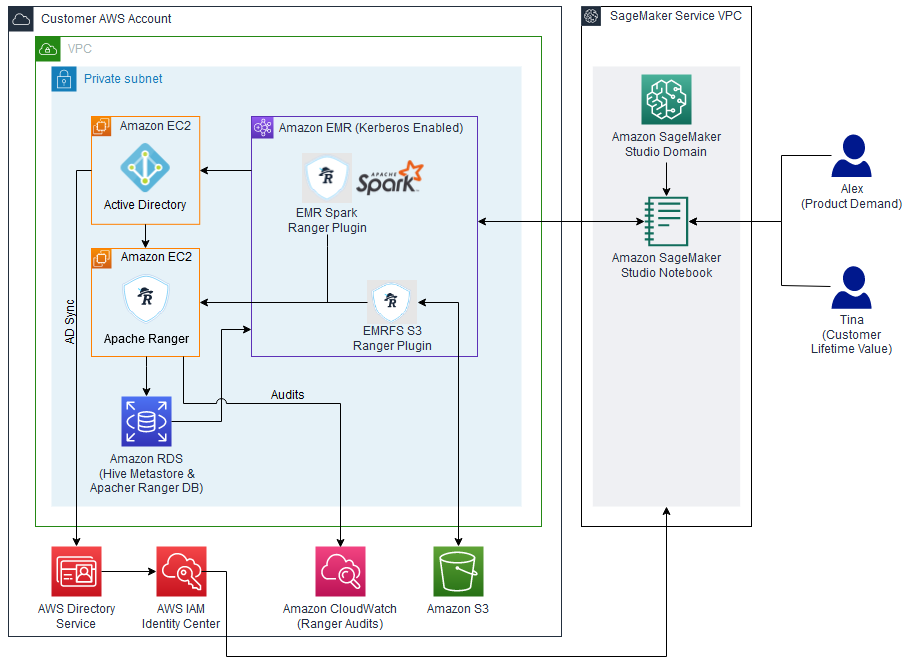
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.