AWS Big Data Blog
Category: Amazon Athena

Interact with Apache Iceberg tables using Amazon Athena and cross account fine-grained permissions using AWS Lake Formation
We recently announced support for AWS Lake Formation fine-grained access control policies in Amazon Athena queries for data stored in any supported file format using table formats such as Apache Iceberg, Apache Hudi and Apache Hive. AWS Lake Formation allows you to define and enforce database, table, and column-level access policies to query Iceberg tables […]

Extend geospatial queries in Amazon Athena with UDFs and AWS Lambda
Amazon Athena is a serverless and interactive query service that allows you to easily analyze data in Amazon Simple Storage Service (Amazon S3) and 25-plus data sources, including on-premises data sources or other cloud systems using SQL or Python. Athena built-in capabilities include querying for geospatial data; for example, you can count the number of […]
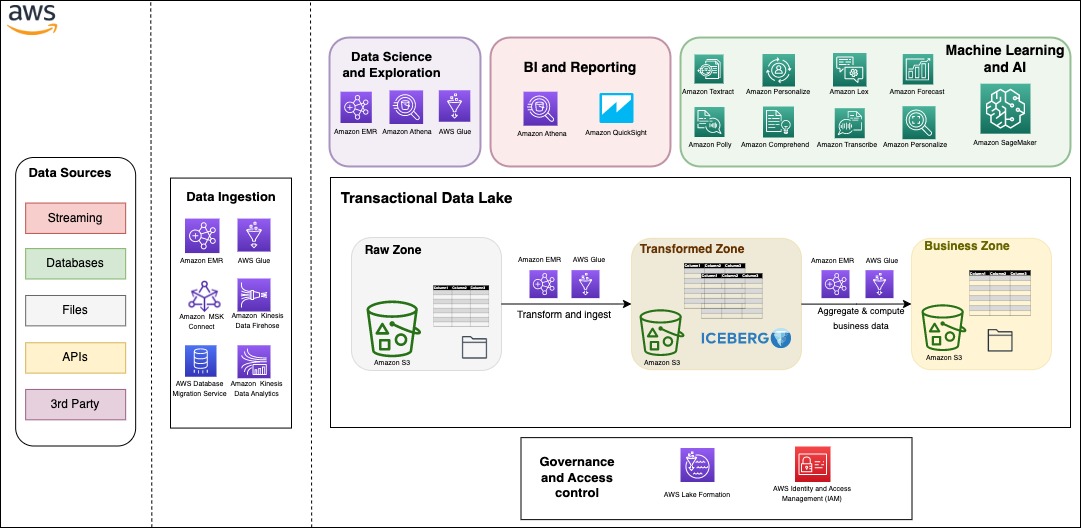
Build a serverless transactional data lake with Apache Iceberg, Amazon EMR Serverless, and Amazon Athena
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructured data at any scale and in various formats. However, as data processing at scale solutions grow, organizations need […]

Improve productivity by using keyboard shortcuts in Amazon Athena query editor
Amazon Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open-table and file formats. Athena provides a simplified, flexible way to analyze petabytes of data where it lives. You can analyze data or build applications from an Amazon Simple Storage Service (Amazon S3) data lake and over 25 data sources, including on-premises […]

Access Amazon Athena in your applications using the WebSocket API
In this post, we present a solution that can integrate with your front-end application to query data from Amazon S3 using an Athena synchronous API invocation. With this solution, you can add a layer of abstraction to your application on direct Athena API calls and promote the access using the WebSocket API developed with Amazon API Gateway. The query results are returned back to the application as Amazon S3 presigned URLs.

Use Apache Iceberg in a data lake to support incremental data processing
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. It adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. Iceberg has […]

Build a real-time GDPR-aligned Apache Iceberg data lake
Data lakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a data lake design, data should be immutable once stored. But regulations such as the General Data Protection Regulation (GDPR) have created obligations for data operators who must be able to erase or […]

Automate replication of relational sources into a transactional data lake with Apache Iceberg and AWS Glue
Organizations have chosen to build data lakes on top of Amazon Simple Storage Service (Amazon S3) for many years. A data lake is the most popular choice for organizations to store all their organizational data generated by different teams, across business domains, from all different formats, and even over history. According to a study, the […]

Analyze Amazon S3 storage costs using AWS Cost and Usage Reports, Amazon S3 Inventory, and Amazon Athena
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating data lakes, serving as object storage for consumer applications, storing logs, and archiving data. As the application portfolio grows, customers tend to store data from multiple application and different business functions […]

How Amazon Devices scaled and optimized real-time demand and supply forecasts using serverless analytics
Every day, Amazon devices process and analyze billions of transactions from global shipping, inventory, capacity, supply, sales, marketing, producers, and customer service teams. This data is used in procuring devices’ inventory to meet Amazon customers’ demands. With data volumes exhibiting a double-digit percentage growth rate year on year and the COVID pandemic disrupting global logistics […]