AWS Big Data Blog
Category: Amazon Athena

Securely process near-real-time data from Amazon MSK Serverless using an AWS Glue streaming ETL job with IAM authentication
Streaming data has become an indispensable resource for organizations worldwide because it offers real-time insights that are crucial for data analytics. The escalating velocity and magnitude of collected data has created a demand for real-time analytics. This data originates from diverse sources, including social media, sensors, logs, and clickstreams, among others. With streaming data, organizations […]

Extracting key insights from Amazon S3 access logs with AWS Glue for Ray
This blog post presents an architecture solution that allows customers to extract key insights from Amazon S3 access logs at scale. We will partition and format the server access logs with Amazon Web Services (AWS) Glue, a serverless data integration service, to generate a catalog for access logs and create dashboards for insights.

Implement a serverless CDC process with Apache Iceberg using Amazon DynamoDB and Amazon Athena
Apache Iceberg is an open table format for very large analytic datasets. Iceberg manages large collections of files as tables, and it supports modern analytical data lake operations such as record-level insert, update, delete, and time travel queries. The Iceberg specification allows seamless table evolution such as schema and partition evolution, and its design is […]

Use Amazon Athena to query data stored in GCP GCS
As customers accelerate their migrations to the cloud and transform their businesses, some find themselves in situations where they have to manage data analytics in a multi-cloud environment, such as acquiring a company that runs on a different cloud provider. Customers who use multi-cloud environments often face challenges in data access and compatibility that can […]

Monitor data pipelines in a serverless data lake
AWS serverless services, including but not limited to AWS Lambda, AWS Glue, AWS Fargate, Amazon EventBridge, Amazon Athena, Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Storage Service (Amazon S3), have become the building blocks for any serverless data lake, providing key mechanisms to ingest and transform data […]

Create an Apache Hudi-based near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSight
We recently announced support for streaming extract, transform, and load (ETL) jobs in AWS Glue version 4.0, a new version of AWS Glue that accelerates data integration workloads in AWS. AWS Glue streaming ETL jobs continuously consume data from streaming sources, clean and transform the data in-flight, and make it available for analysis in seconds. AWS also offers a broad selection of services to support your needs. A database replication service such as AWS Database Migration Service (AWS DMS) can replicate the data from your source systems to Amazon Simple Storage Service (Amazon S3), which commonly hosts the storage layer of the data lake. This post demonstrates how to apply CDC changes from Amazon Relational Database Service (Amazon RDS) or other relational databases to an S3 data lake, with flexibility to denormalize, transform, and enrich the data in near-real time.
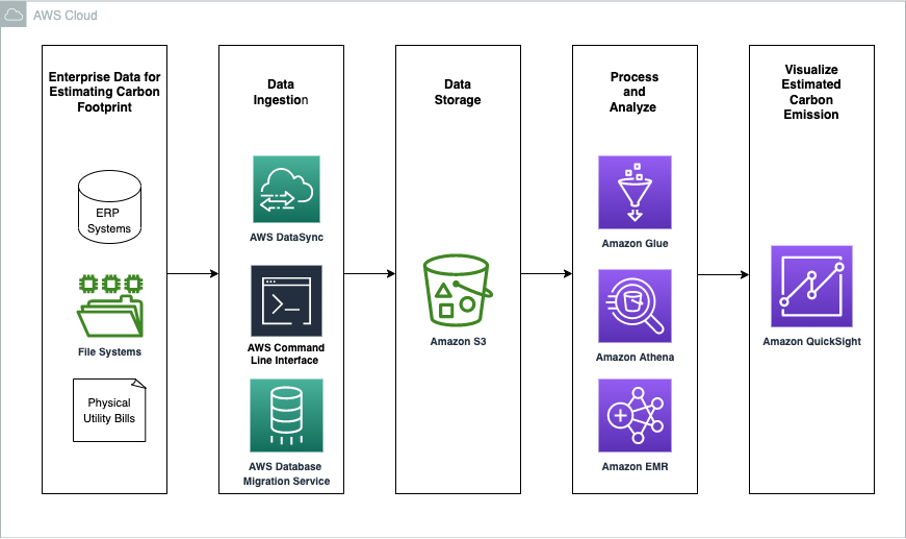
Estimating Scope 1 Carbon Footprint with Amazon Athena
Today, more than 400 organizations have signed The Climate Pledge, a commitment to reach net-zero carbon by 2040. Some of the drivers that lead to setting explicit climate goals include customer demand, current and anticipated government relations, employee demand, investor demand, and sustainability as a competitive advantage. AWS customers are increasingly interested in ways to […]

Extend your data mesh with Amazon Athena and federated views
Amazon Athena is a serverless, interactive analytics service built on the Trino, PrestoDB, and Apache Spark open-source frameworks. You can use Athena to run SQL queries on petabytes of data stored on Amazon Simple Storage Service (Amazon S3) in widely used formats such as Parquet and open-table formats like Apache Iceberg, Apache Hudi, and Delta […]

Orca Security’s journey to a petabyte-scale data lake with Apache Iceberg and AWS Analytics
This post is co-written with Eliad Gat and Oded Lifshiz from Orca Security. With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. One key component that plays a central role in modern data architectures is the data lake, which allows organizations to […]

Build and share a business capability model with Amazon QuickSight
The technology landscape has been evolving rapidly, with waves of change impacting IT from every angle. It is causing a ripple effect across IT organizations and shifting the way IT delivers applications and services. The change factors impacting IT organizations include: The shift from a traditional application model to a services-based application model (SaaS, PaaS) […]