AWS Big Data Blog
Category: Amazon Athena

Query your Oracle database using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Oracle as your transactional data store, you may need to join the data in your data lake with Oracle on Amazon Relational Database Service (Amazon RDS), Oracle running on Amazon […]

Create a secure data lake by masking, encrypting data, and enabling fine-grained access with AWS Lake Formation
You can build data lakes with millions of objects on Amazon Simple Storage Service (Amazon S3) and use AWS native analytics and machine learning (ML) services to process, analyze, and extract business insights. You can use a combination of our purpose-built databases and analytics services like Amazon EMR, Amazon OpenSearch Service, and Amazon Redshift as […]

Hydrate your data lake with SaaS application data using Amazon AppFlow
Organizations today want to make data-driven decisions. The data could lie in multiple source systems, such as line of business applications, log files, connected devices, social media, and many more. As organizations adopt software as a service (SaaS) applications, data becomes increasingly fragmented and trapped in different “data islands.” To make decision-making easier, organizations are […]

Build a data quality score card using AWS Glue DataBrew, Amazon Athena, and Amazon QuickSight
Data quality plays an important role while building an extract, transform, and load (ETL) pipeline for sending data to downstream analytical applications and machine learning (ML) models. The analogy “garbage in, garbage out” is apt at describing why it’s important to filter out bad data before further processing. Continuously monitoring data quality and comparing it […]
Speed up your Amazon Athena queries using partition projection
This post is co-written with Steven Wasserman of Vertex, Inc. Amazon Athena is an interactive query service that makes it easy to analyze data stored in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. […]
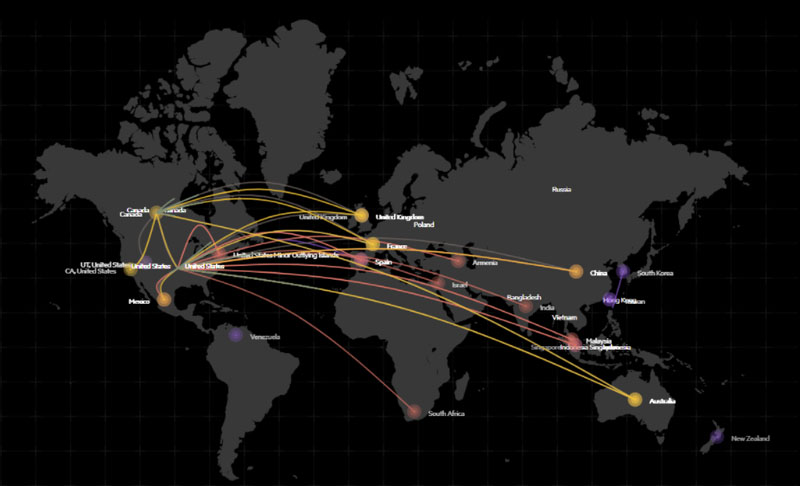
How Imperva uses Amazon Athena for machine learning botnets detection
This is a guest post by Ori Nakar, Principal Engineer at Imperva. In their own words, “Imperva is a large cyber security company and an AWS Partner Network (APN) Advanced Technology Partner, who protects web applications and data assets. Imperva protects over 6,200 enterprises worldwide and many of them use Imperva Web Application Firewall (WAF) […]
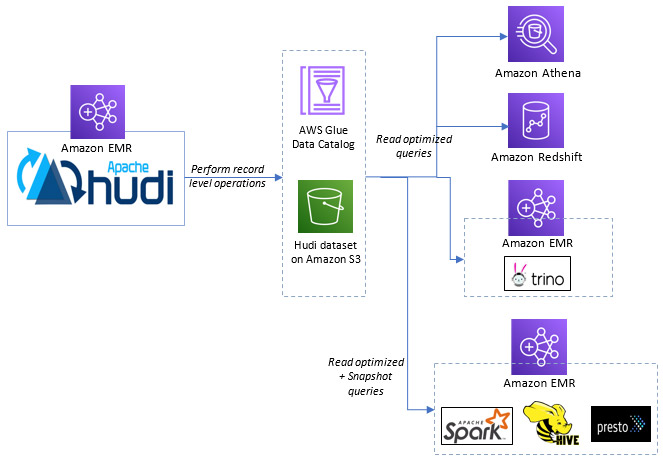
New features from Apache Hudi available in Amazon EMR
Apache Hudi is an open-source data management framework used to simplify incremental data processing and data pipeline development by providing record-level insert, update and delete capabilities. This record-level capability is helpful if you’re building your data lakes on Amazon S3 or HDFS. You can use it to comply with data privacy regulations and simplify data […]

Create a custom data connector to Slack’s Member Analytics API in Amazon QuickSight with Amazon Athena Federated Query
Amazon QuickSight recently added support for Amazon Athena Federated Query, which allows you to query data in place from various data sources. With this capability, QuickSight can extend support to query additional data sources like Amazon CloudWatch Logs, Amazon DynamoDB, and Amazon DocumentDB (with Mongo DB compatibility) via their existing Amazon Athena data source. You […]

Integrating Datadog data with AWS using Amazon AppFlow for intelligent monitoring
Infrastructure and operation teams are often challenged with getting a full view into their IT environments to do monitoring and troubleshooting. New monitoring technologies are needed to provide an integrated view of all components of an IT infrastructure and application system. Datadog provides intelligent application and service monitoring by bringing together data from servers, databases, […]

Querying a Vertica data source in Amazon Athena using the Athena Federated Query SDK
The ability to query data and perform ad hoc analysis across multiple platforms and data stores with a single tool brings immense value to the big data analytical arena. As organizations build out data lakes with increasing volumes of data, there is a growing need to combine that data with large amounts of data in […]