AWS Big Data Blog
Category: Amazon Athena

Improve federated queries with predicate pushdown in Amazon Athena
In modern data architectures, it’s common to store data in multiple data sources. However, organizations embracing this approach still need insights from their data and require technologies that help them break down data silos. Amazon Athena is an interactive query service that makes it easy to analyze structured, unstructured, and semi-structured data stored in Amazon […]

Visualize Amazon S3 data using Amazon Athena and Amazon Managed Grafana
Grafana is a popular open-source analytics platform that you can employ to create, explore, and share your data through flexible dashboards. Its use cases include application and IoT device monitoring, and visualization of operational and business data, among others. You can create your dashboard with your own datasets or publicly available datasets related to your […]

Set up federated access to Amazon Athena for Microsoft AD FS users using AWS Lake Formation and a JDBC client
Tens of thousands of AWS customers choose Amazon Simple Storage Service (Amazon S3) as their data lake to run big data analytics, interactive queries, high-performance computing, and artificial intelligence (AI) and machine learning (ML) applications to gain business insights from their data. On top of these data lakes, you can use AWS Lake Formation to […]
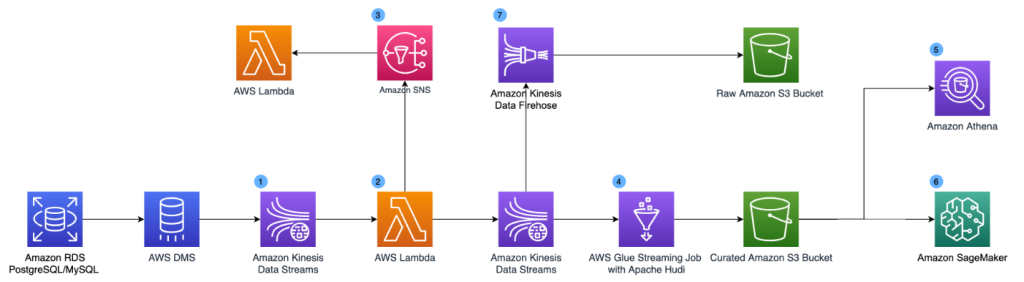
How NerdWallet uses AWS and Apache Hudi to build a serverless, real-time analytics platform
This is a guest post by Kevin Chun, Staff Software Engineer in Core Engineering at NerdWallet. NerdWallet’s mission is to provide clarity for all of life’s financial decisions. This covers a diverse set of topics: from choosing the right credit card, to managing your spending, to finding the best personal loan, to refinancing your mortgage. […]

Use Amazon Athena parameterized queries to provide data as a service
Amazon Athena now provides you more flexibility to use parameterized queries, and we recommend you use them as the best practice for your Athena queries moving forward so you benefit from the security, reusability, and simplicity they offer. In a previous post, Improve reusability and security using Amazon Athena parameterized queries, we explained how parameterized […]

Build an Apache Iceberg data lake using Amazon Athena, Amazon EMR, and AWS Glue
March 2024: This post was reviewed and updated for accuracy. Most businesses store their critical data in a data lake, where you can bring data from various sources to a centralized storage. The data is processed by specialized big data compute engines, such as Amazon Athena for interactive queries, Amazon EMR for Apache Spark applications, […]

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]

Build a multilingual dashboard with Amazon Athena and Amazon QuickSight
Amazon QuickSight is a serverless business intelligence (BI) service used by organizations of any size to make better data-driven decisions. QuickSight dashboards can also be embedded into SaaS apps and web portals to provide interactive dashboards, natural language query or data analysis capabilities to app users seamlessly. The QuickSight Demo Central contains many dashboards, feature showcase […]

A serverless operational data lake for retail with AWS Glue, Amazon Kinesis Data Streams, Amazon DynamoDB, and Amazon QuickSight
Do you want to reduce stockouts at stores? Do you want to improve order delivery timelines? Do you want to provide your customers with accurate product availability, down to the millisecond? A retail operational data lake can help you transform the customer experience by providing deeper insights into a variety of operational aspects of your […]

Visualize MongoDB data from Amazon QuickSight using Amazon Athena Federated Query
In this post, you will learn how to use Amazon Athena Federated Query to connect a MongoDB database to Amazon QuickSight in order to build dashboards and visualizations. Amazon Athena is a serverless interactive query service, based on Presto, that provides full ANSI SQL support to query a variety of standard data formats, including CSV, […]