AWS Big Data Blog
Catalog and analyze Application Load Balancer logs more efficiently with AWS Glue custom classifiers and Amazon Athena
You can query Application Load Balancer (ALB) access logs for various purposes, such as analyzing traffic distribution and patterns. You can also easily use Amazon Athena to create a table and query against the ALB access logs on Amazon Simple Storage Service (Amazon S3). (For more information, see How do I analyze my Application Load Balancer access logs using Amazon Athena? and Querying Application Load Balancer Logs.) All queries are run against the whole table because it doesn’t define any partitions. If you have several years of ALB logs, you may want to use a partitioned table instead for better query performance and cost control. In fact, partitioning data is one of the Top 10 performance tuning tips for Athena.
However, because ALB log files aren’t stored in a Hive-style prefix (such as /year=2021/), the process of creating thousands of partitions using ALTER TABLE ADD PARTITION in Athena is cumbersome. This post shows a way to create and schedule an AWS Glue crawler with a Grok custom classifier that infers the schema of all ALB log files under the specified Amazon S3 prefix and populates the partition metadata (year, month, and day) automatically to the AWS Glue Data Catalog.
Prerequisites
To follow along with this post, complete the following prerequisites:
- Enable access logging of the ALBs, and have the files already ingested in the specified S3 bucket.
- Set up the Athena query result location. For more information, see Working with Query Results, Output Files, and Query History.
Solution overview
The following diagram illustrates the solution architecture.
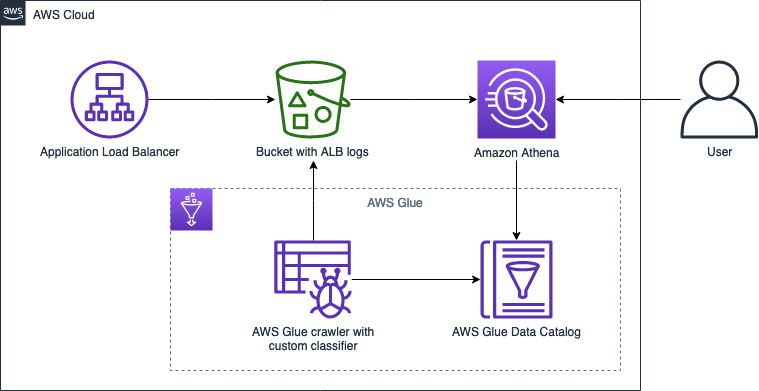
To implement this solution, we complete the following steps:
- Prepare the Grok pattern for our ALB logs, and cross-check with a Grok debugger.
- Create an AWS Glue crawler with a Grok custom classifier.
- Run the crawler to prepare a table with partitions in the Data Catalog.
- Analyze the partitioned data using Athena and compare query speed vs. a non-partitioned table.
Prepare the Grok pattern for our ALB logs
As a preliminary step, locate the access log files on the Amazon S3 console, and manually inspect the files to observe the format and syntax. To allow an AWS Glue crawler to recognize the pattern, we need to use a Grok pattern to match against an expression and map specific parts into the corresponding fields. Approximately 100 sample Grok patterns are available in the Logstash Plugins GitHub, and we can write our own custom pattern if it’s not listed.
The following the basic syntax format for a Grok pattern %{PATTERN:FieldName}
The following is an example of an ALB access log:
To map the first field, the Grok pattern might look like the following code:
The pattern includes the following components:
DATAmaps to.*?typeis the column name\sis the whitespace character
To map the second field, the Grok pattern might look like the following:
This pattern has the following elements:
TIMESTAMP_ISO8601maps to%{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}?timeis the column name\sis the whitespace character
When writing Grok patterns, we should also consider corner cases. For example, the following code is a normal case:
But when considering the possibility of null value, we should replace the pattern with the following:
When our Grok pattern is ready, we can test the Grok pattern with sample input using a third-party Grok debugger. The following pattern is a good start, but always remember to test it with the actual ALB logs.
Keep in mind that when you copy the Grok pattern from your browser, in some cases there are extra spaces in the end of the lines. Make sure to remove these extra spaces.
Create an AWS Glue crawler with a Grok custom classifier
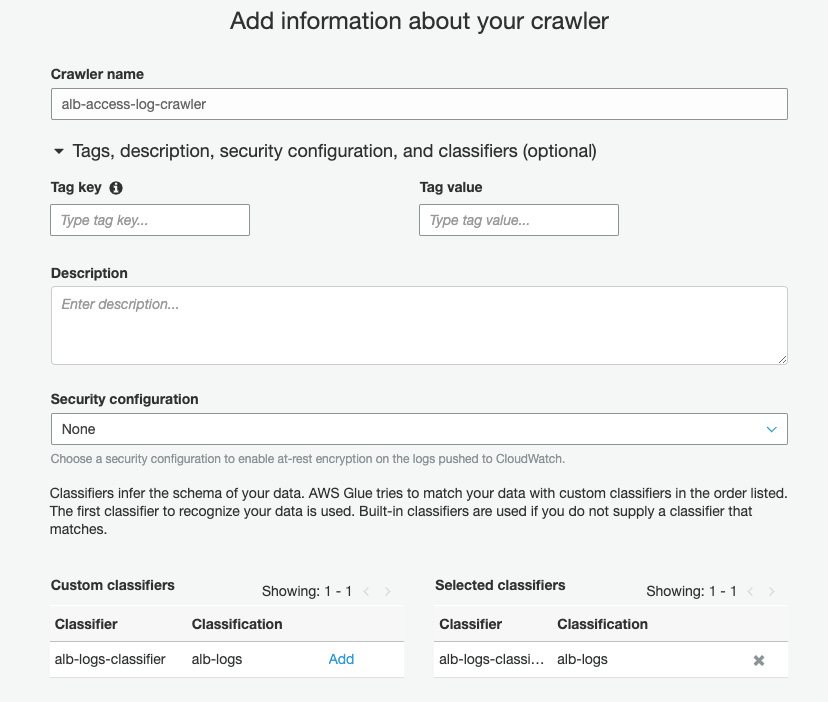
Before you create your crawler, you first create a custom classifier. Complete the following steps:
- On the AWS Glue console, under Crawler, choose Classifiers.
- Choose Add classifier.
- For Classifier name, enter
alb-logs-classifier. - For Classifier type¸ select Grok.
- For Classification, enter
alb-logs. - For Grok pattern, enter the pattern from the previous section.
- Choose Create.

Now you can create your crawler.
- Choose Crawlers in the navigation pane.
- Choose Add crawler.
- For Crawler name, enter
alb-access-log-crawler. - For Selected classifiers, enter
alb-logs-classifier.
- Choose Next.
- For Crawler source type, select Data stores.
- For Repeat crawls of S3 data stores, select Crawl new folders only.
- Choose Next.

- For Choose a data store, choose S3.
- For Crawl data in, select Specified path in my account.
- For Include path, enter the path to your ALB logs (for example,
s3://alb-logs-directory/AWSLogs/<ACCOUNT-ID>/elasticloadbalancing/<REGION>/). - Choose Next.

- When prompted to add another data store, select No and choose Next.
- Select Create an IAM role, and give it a name such as
AWSGlueServiceRole-alb-logs-crawler. - For Frequency, choose Daily.
- Indicate your start hour and minute.
- Choose Next.

- For Database, enter
elb-access-log-db. - For Prefix added to tables, enter
alb_logs_.

- Expand Configuration options.
- Select Update all new and existing partitions with metadata from the table.
- Keep the other options at their default.

- Choose Next.
- Review your settings and choose Finish.
Run your AWS Glue crawler
Next, we run our crawler to prepare a table with partitions in the Data Catalog.
- On the AWS Glue console, choose Crawlers.
- Select the crawler we just created.
- Choose Run crawler.
When the crawler is complete, you receive a notification indicating that a table has been created.

Next, we review and edit the schema.
- Under Databases, choose Tables.
- Choose the table
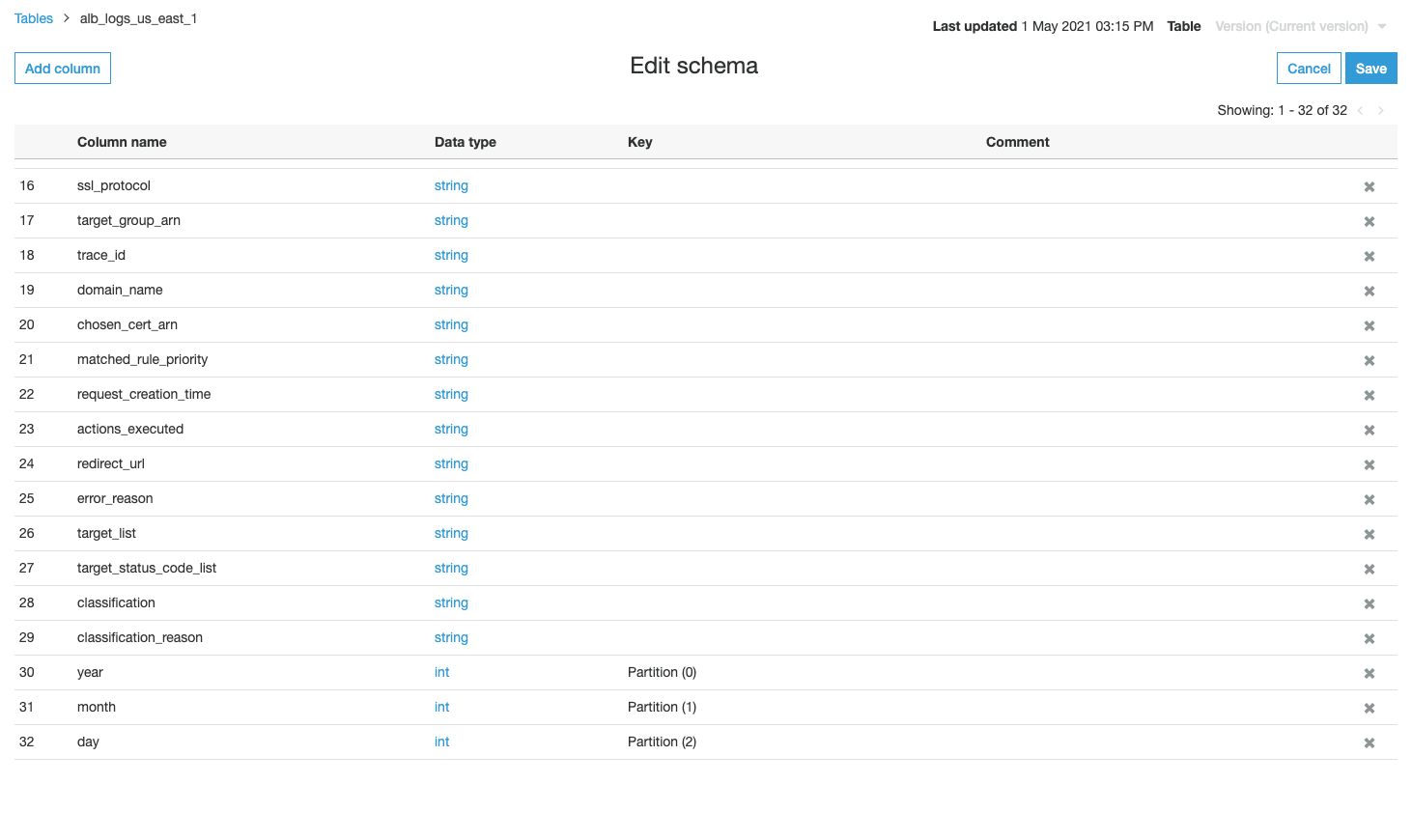
alb_logs_<region>. - Cross-check the column name and corresponding data type.
The table has three columns: partiion_0, partition_1, and partition_2.
- Choose Edit schema.
- Rename the columns
year,month, andday.
- Choose Save.
Analyze the data using Athena
Next, we analyze our data by querying the access logs. We compare the query speed between the following tables:
- Non-partitioned table – All data is treated as a single table
- Partitioned table – Data is partitioned by year, month, and day
Query the non-partitioned table
With the non-partitioned table, if we want to query access logs on a specific date, we have to write the WHERE clause using the LIKE operator because the data column was interpreted as a string. See the following code:
The query takes 5.25 seconds to complete, with 3.15 MB data scanned.

Query the partitioned table
With the year, month, and day columns as partitions, we can use the following statement to query access logs on the same day:
This time the query takes only 1.89 seconds to complete, with 25.72 KB data scanned.

This query is faster and costs less (because less data is scanned) due to partition pruning.
Clean up
To avoid incurring future charges, delete the resources created in the Data Catalog, and delete the AWS Glue crawler.
Summary
In this post, we illustrated how to create an AWS Glue crawler that populates ALB logs metadata in the AWS Glue Data Catalog automatically with partitions by year, month, and day. With partition pruning, we can improve query performance and associated costs in Athena.
If you have questions or suggestions, please leave a comment.
About the Authors
 Ray Wang is a Solutions Architect at AWS. With 8 years of experience in the IT industry, Ray is dedicated to building modern solutions on the cloud, especially in big data and machine learning. As a hungry go-getter, he passed all 12 AWS certificates to make his technical field not only deep but wide. He loves to read and watch sci-fi movies in his spare time.
Ray Wang is a Solutions Architect at AWS. With 8 years of experience in the IT industry, Ray is dedicated to building modern solutions on the cloud, especially in big data and machine learning. As a hungry go-getter, he passed all 12 AWS certificates to make his technical field not only deep but wide. He loves to read and watch sci-fi movies in his spare time.
 Corvus Lee is a Data Lab Solutions Architect at AWS. He enjoys all kinds of data-related discussions with customers, from high-level like white boarding a data lake architecture, to the details of data modeling, writing Python/Spark code for data processing, and more.
Corvus Lee is a Data Lab Solutions Architect at AWS. He enjoys all kinds of data-related discussions with customers, from high-level like white boarding a data lake architecture, to the details of data modeling, writing Python/Spark code for data processing, and more.