AWS Architecture Blog
Selecting Service Endpoints for Reliability and Performance
Choose Your Route Wisely
Much like a roadway, the Internet is subject to congestion and blockage that cause slowdowns and at worst prevent packets from arriving at their destination. Like too many cars jamming themselves onto a highway, too much data over a route on the Internet results in slowdowns. Transatlantic cable breaks have much the same effect as road construction, resulting in detours and further congestion and may prevent access to certain sites altogether. Services with multiple points of presence paired with either smart clients or service-side routing logic improve performance and reliability by ensuring your viewers have access to alternative routes when roadways are blocked. This blog post provides you with an overview of service side and client side designs that can improve the reliability and performance of your Internet-facing services.
In order to understand how smart routing can increase performance, we must first understand why Internet downloads take time. To extend our roadway analogy, imagine we need to drive to the hardware to obtain supplies. If we can get our supplies in one trip and it takes 10 minutes to drive one way, it takes 20 minutes to get the supplies and return to the house project. (For sake of simplicity we’ll exclude the time involved with finding a parking spot, wandering aimlessly around the store in search of the right parts, and loading up materials.) Much of the time is taken up by driving the 5 km across multiples types of roadways to the hardware store.
Packets on the Internet must also transit physical distance and many links to reach their destination. A traceroute from my home network to my website hosted in eu-west-1 traverse 20 different links. It takes time for a packet to traverse the physical distance between each of these nodes. Traveling at a speed of 200,000 km/sec my packets travel from Seattle to Dublin and back in 170 ms.
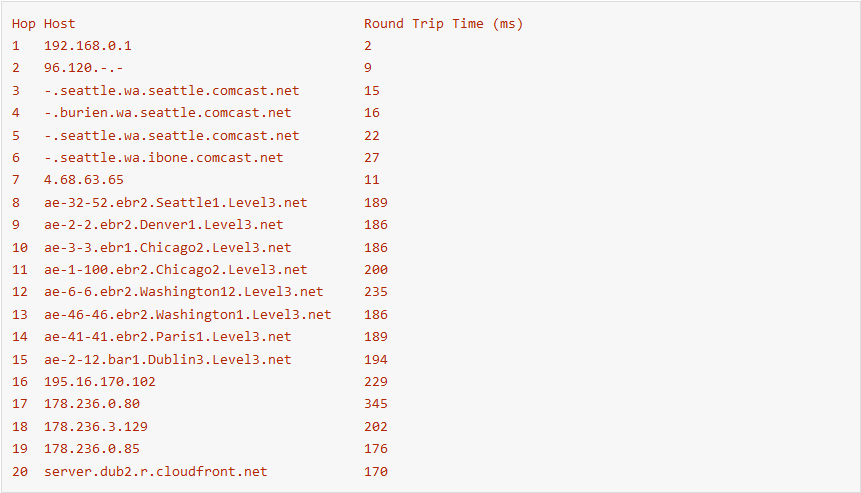
Unlike roadways, when congestion occurs on Internet paths routers discard packets. Discarded packets result in retransmits by the sender adding additional round trips to the overall download. The additional round trips result in a slower download. Just as multiple trips to the hardware store results in more time spent driving and less time building.
To reduce the time of a round trip, a packet needs to travel a shorter physical distance. To avoid packet loss and additional round trips, a packet needs to avoid broken or congested routes. Performance and reliability of an Internet-facing service are improved by using the shortest physical path between the service and the client and by minimizing the number of round trips for data transfer.
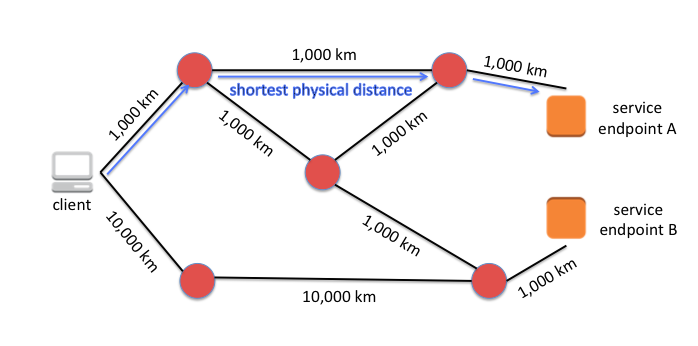

Adding multiple points of presence to your architecture is like opening up a chain of hardware stores around the city. With multiple points of presence, drivers can choose a destination hardware store that allows them to drive the shortest physical distant. If the route to any one hardware store is congested or blocked entirely, driver can instead drive to the next nearest store.
Measuring the Internet
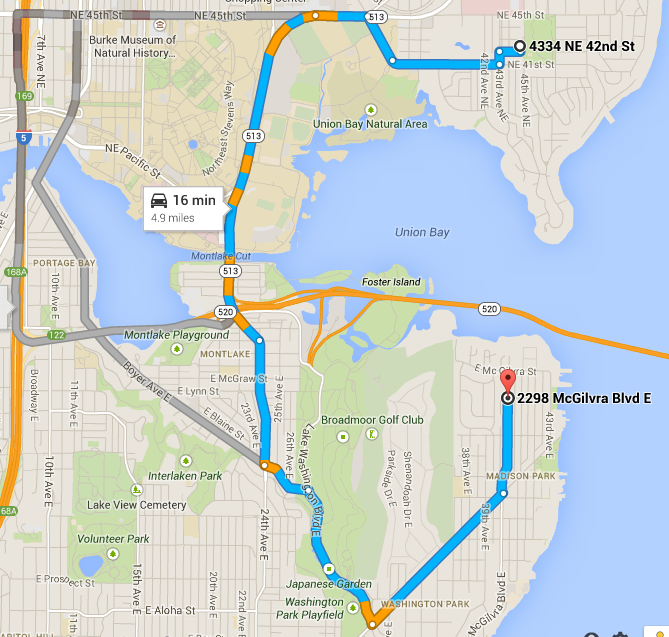
Finding the fastest and most reliable paths on across the Internet requires real world measurement. The closest endpoint as the crow flies often isn’t the same as fastest via Internet paths. The diagrams below depict an all too common example when driving in the real world. Given the starting point (the white dot), hardware store B (the red marker in the second diagram) is actually closer as the crow flies, but requires a lot more driving distance. A driver that knows the roadways will know that it will take less overall time to drive to store A.
Hardware store A is 10 minutes away by car

Hardware store B would be much closer by way of the water, but is 16 minutes by car
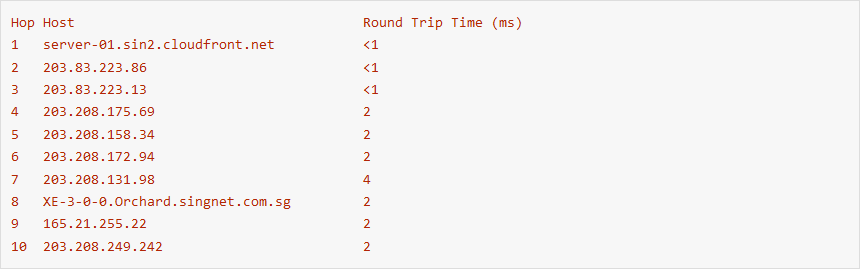
The same is true on the Internet, here’s a real-world example from CloudFront just after it launched in 2008. Below is a traceroute from an ISP network in Singapore to the SIN2 edge location in Singapore (internally AWS uses airport codes to identify edge locations). The trace route below shows that a packet sourced from a Singapore ISP to the SIN2 edge location was routed by way of Hong Kong! Based on the connectivity of this viewer network, Singapore customers are better served from the HKG1 edge location rather than SIN2. If routing logic assumed that geographically closer edge locations resulted in lower latency, the router engine would choose SIN2. By measuring latency the system we see that the system should select HKG50 as the preferred edge location, but going doing the routing system can provide the viewer with 32 ms round trip times versus 39 ms round trip times.

The topology of the Internet is always changing. The SIN to HKG example is old, now SIN2 is directly peered with the network above. Continuous or just in time measurements allow a system to adapt when Internet topology changes. Once the AWS networking team built a direct connection between our SIN edge location and the Singapore ISP, the CloudFront measurement system automatically observed lower latencies. SIN2 became preferred lowest latency pop. The direct path results in 2.2 ms round trip times versus 39 ms round trip times.
Leveraging Real World Measurements for Routing Decisions
Service-Side Routing
CloudFront and Route 53 both leverage similar mechanisms to route clients to the closest available end points. CloudFront uses routing logic in its DNS layer. When clients resolve DNS for a CloudFront distribution they receive a set of IPs that map to the closest available edge location. Route 53’s Latency-Based Routing combined with DNS Failover and health checks allows customers to build the same routing logic into any service hosted across multiple AWS regions.
Availability failures are detected via continuous health checks. Each CloudFront edge location checks the availability of every other edge location and reports the health-state to CloudFront DNS servers (which also happen to be Route 53 DNS servers). If an edge location starts failing health checks, CloudFront DNS servers respond to client queries with IPs that map to the client’s the next-closest healthy edge location. AWS customers can implement similar health check fail over capabilities within their services by use the Route 53 DNS failover and health checks feature.
Lowest-latency routing is achieved by continuously sampling latency measurements from viewer networks across the Internet to each AWS region and edge location. Latency measurement data is compiled into a list of AWS sites for each viewer network, sorted by latency. CloudFront and Route 53 DNS servers use this data to direct traffic. When network topology shifts occur, the latency measurement system picks up the changes and reorders the list of least-latent AWS endpoints for that given network.
Client-Side Routing
But service-side technology isn’t the only way to perform latency-based routing. Client software also has access to all of the data it needs to select the best endpoint. A smart client can intelligently rotate through a list of endpoints whenever a connection failure occurs. Smart clients perform their own latency measurements and choose the lowest latency endpoint as its connection destination. Most DNS resolvers do exactly that. Lee’s prior blog post made mention of DNS resolvers and provided a reference to this presentation.
The DNS protocol is well suited to smart-client endpoint selection. When a DNS server resolves a DNS name, say www.internetkitties.com, the server must first determine which DNS servers are authoritative to answer queries for the domain. In my case, my domain is hosted by Route 53, which provides me with 4 assigned name servers. Smart DNS resolvers track the query response times to each name server and preferentially query the fastest name server. If the name server fails to respond, the DNS resolver falls back to other name servers on the list.
There are examples in HTTP as well. The Kindle Fire web browser, Amazon Silk, makes use of a backend-resources hosted in multiple AWS regions to speed up the web browsing experience for its customers. The Amazon Silk client knows about and collects latency measurements against each endpoint of the Amazon Silk backend service. The client connects to the lowest-latency end point. As the device moves around from one network to another, the lowest-latency end point might change.
Service architecture with multiple points of presence on the Internet combined with latency-based service-side or client-side endpoint selection can improve the performance and reliability of your service. Let us know if you’d like to a follow blog on best practices for measuring Internet latencies or lessons learned from the Amazon Silk client-side endpoint selector.
– Nate Dye