AWS Architecture Blog
Category: Technical How-to
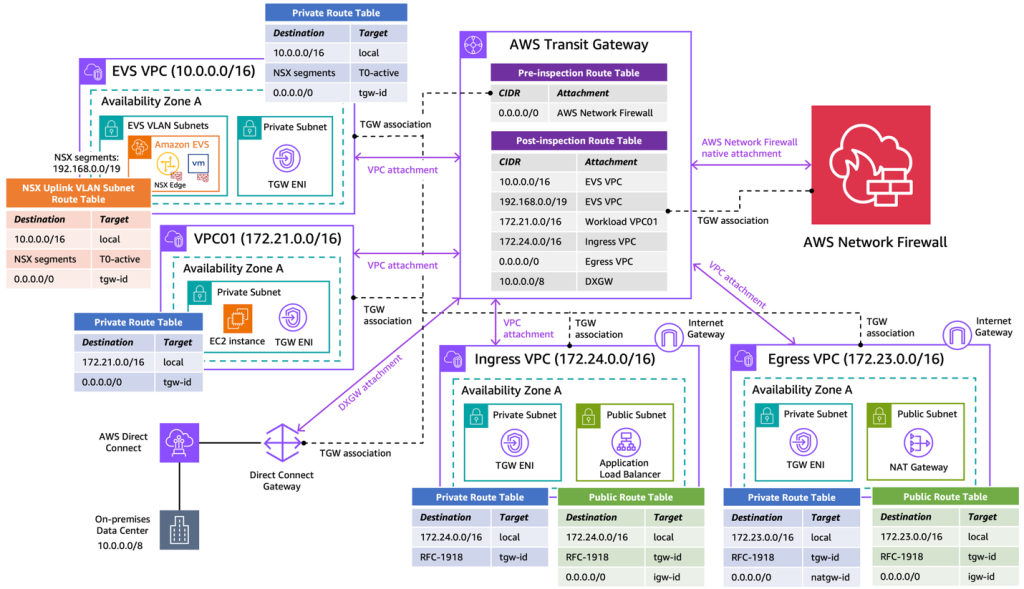
Secure Amazon Elastic VMware Service (Amazon EVS) with AWS Network Firewall
In this post, we demonstrate how to utilize AWS Network Firewall to secure an Amazon EVS environment, using a centralized inspection architecture across an EVS cluster, VPCs, on-premises data centers and the internet. We walk through the implementation steps to deploy this architecture using AWS Network Firewall and AWS Transit Gateway.
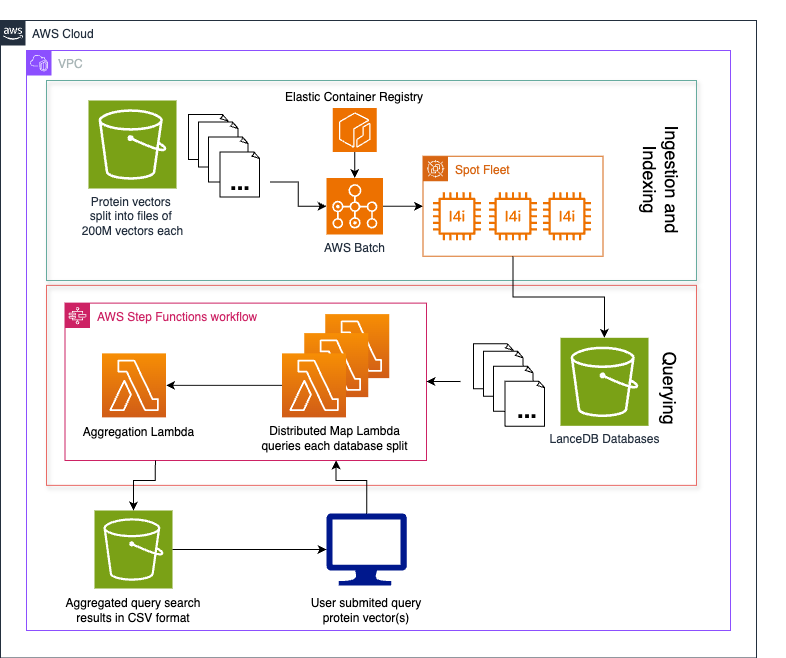
A scalable, elastic database and search solution for 1B+ vectors built on LanceDB and Amazon S3
In this post, we explore how Metagenomi built a scalable database and search solution for over 1 billion protein vectors using LanceDB and Amazon S3. The solution enables rapid enzyme discovery by transforming proteins into vector embeddings and implementing a serverless architecture that combines AWS Lambda, AWS Step Functions, and Amazon S3 for efficient nearest neighbor searches.
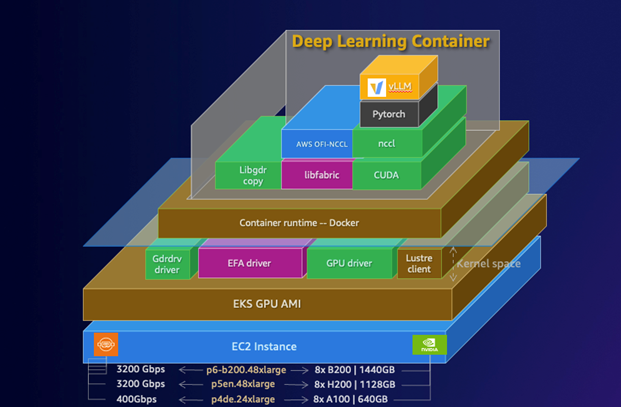
Deploy LLMs on Amazon EKS using vLLM Deep Learning Containers
In this post, we demonstrate how to deploy the DeepSeek-R1-Distill-Qwen-32B model using AWS DLCs for vLLMs on Amazon EKS, showcasing how these purpose-built containers simplify deployment of this powerful open source inference engine. This solution can help you solve the complex infrastructure challenges of deploying LLMs while maintaining performance and cost-efficiency.
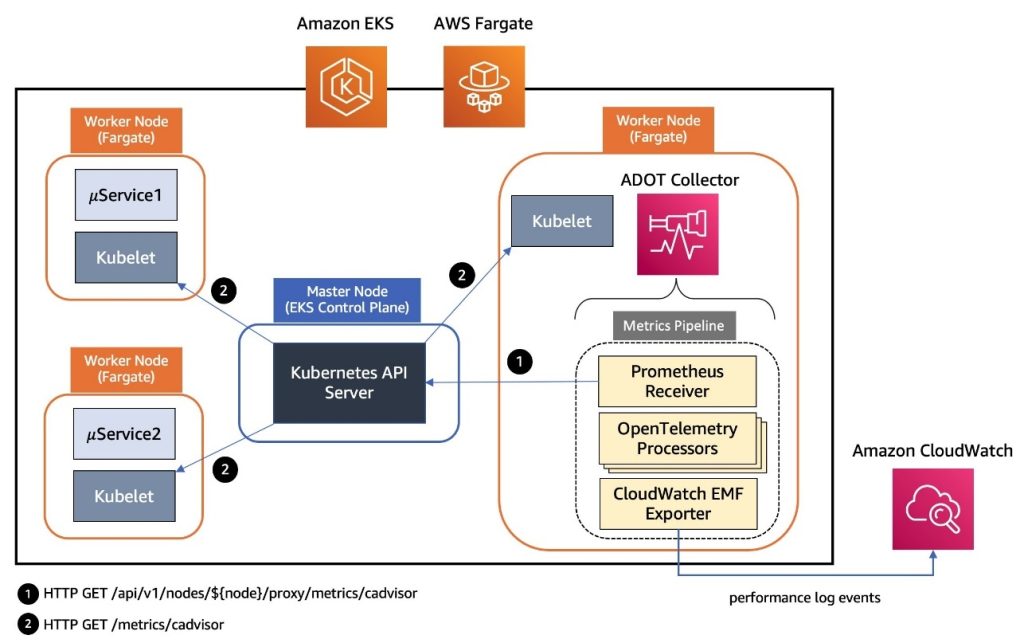
Implement monitoring for Amazon EKS with managed services
In this post, we show you how to implement comprehensive monitoring for Amazon Elastic Kubernetes Service (Amazon EKS) workloads using AWS managed services. This solution demonstrates building an EKS platform that combines flexible compute options with enterprise-grade observability using AWS native services and OpenTelemetry.

Amazon Bedrock baseline architecture in an AWS landing zone
In this post, we explore the Amazon Bedrock baseline architecture and how you can secure and control network access to your various Amazon Bedrock capabilities within AWS network services and tools. We discuss key design considerations, such as using Amazon VPC Lattice auth policies, Amazon Virtual Private Cloud (Amazon VPC) endpoints, and AWS Identity and Access Management (IAM) to restrict and monitor access to your Amazon Bedrock capabilities.

Analyze media content using AWS AI services
Organizations managing large audio and video archives face significant challenges in extracting value from their media content. Consider a radio network with thousands of broadcast hours across multiple stations and the challenges they face to efficiently verify ad placements, identify interview segments, and analyze programming patterns. In this post, we demonstrate how you can automatically transform unstructured media files into searchable, analyzable content.

How Launchpad from Pega enables secure SaaS extensibility with AWS Lambda
In this post, we share how Pegasystems (Pega) built Launchpad, its new SaaS development platform, to solve a core challenge in multi-tenant environments: enabling secure customer customization. By running tenant code in isolated environments with AWS Lambda, Launchpad offers its customers a secure, scalable foundation, eliminating the need for bespoke code customizations.

Transforming Maya’s API management with Amazon API Gateway
In this post, you will learn how Amazon Web Services (AWS) customer, Maya, the Philippines’ leading fintech company and digital bank, built an API management platform to address the growing complexities of managing multiple APIs hosted on Amazon API Gateway.

How Smartsheet boosts developer productivity with Amazon Bedrock and Roo Code
This post explores how Smartsheet successfully deployed Roo Code with Amazon Bedrock and Anthropic’s Claude, achieving significant improvements in developer efficiency while optimizing costs through innovative caching strategies.

Revolutionizing agricultural knowledge management using a multi-modal LLM: A reference architecture
In this blog post, we introduce a reference architecture that offers an intelligent document digitization solution that converts handwritten notes, scanned documents, and images into editable, searchable, and accessible formats. Powered by Anthropic’s Claude 3 on Amazon Bedrock, the solution uses the sophisticated vision capabilities of LLMs to process a wide range of visual formats, preserving the original formatting while extracting text, tables, and images.