AWS Partner Network (APN) Blog
Developing Data-Driven IoT Business Models for Sustainability with Storm Reply
By Gabriel Paredes Loza, Business Unit Manager (IoT) — Storm Reply
By Nicolas Corpancho Villasana, Sr. Solutions Architect — Storm Reply
 |
| Storm Reply |
 |
Today, more than ever, governments and businesses require the promotion of solutions targeting the measurement and impact of their efforts on sustainability as part of their agenda. Achieving Sustainable Development Goals (SDGs) requires a holistic and informed approach in the measurement, test, study, and research of real use cases.
Firms spend substantial efforts in the identification and collection of quality data streams from different sources, such as IoT devices, web or mobile applications, and third-party or on-premises systems. However, identifying and interpreting energy, water, or gas usage patterns and consumption types in households or buildings is sometimes insufficient; especially when sustainability outcomes are expected to match ROI requirements.
In this post, you will learn how Storm Reply, combining knowledge of the energy and utilities industry with its expertise in the development of data analytics platforms in Amazon Web Services (AWS), can help customers in the design, development, and maintenance of secure serverless IoT big data platforms with a focus on the identification of new business models for sustainability.
The Internet of Things (IoT) gives businesses great potential for achieving, measuring, and promoting SDGs, besides being a key enabler of successful industry 4.0 applications. Combining business goals with services, like AWS IoT Core and the AWS Analytics Suite, for the identification and processing of precision and quality data can lead to the development of disruptive business models able to unlock value to service providers, final consumers, and other stakeholders in the value chain.
Storm Reply is an AWS Premier Tier Services Partner with an IoT Competency.
Serverless Analytics Architecture
Big data platform architectures are designed following AWS and Storm Reply best practices and the concept of standardization.
The most basic concept of a big data platform is that of an AWS Data Pipeline representing a series of processing steps. First, data is ingested into the pipeline following a sequence of steps in which resulting output from one step is fed as input into the next step. The process continues until all the stages of the pipeline are completed.

Figure 1 — Data pipeline.
The structure proposed for the development of big data platforms aligns with the data pipeline principles recommended by AWS. Since data sources are different by nature (for example, real-time, event-driven, or batch ingesting), the architecture of the platform is built by adapting different data pipelines to different sources or use cases.
In the context of IoT, Storm Reply adopts an AWS serverless data analytics reference architecture for modern, secure, and scalable IoT analytics platforms. This platform includes ingestion, enrichment, and processing pipelines, a data lake, and a consumption layer for visualization and analysis. This reference architecture enables real-time analytics through Amazon Kinesis Data Analytics and Amazon QuickSight.
Data streams can be directly fed into Amazon Simple Storage Service (Amazon S3) bucket(s) for later processing through AWS Glue, while other pipelines can include event-driven or batch processing with Amazon Kinesis Data Firehose. Complementary data enrichment can be made through the usage of machine learning (ML) inference models deployed in AWS Lambda, and developed and trained with the help of Amazon SageMaker.
Other important layers, including security and monitoring, are built leveraging specific services, such as AWS Lake Formation, AWS Key Management Service (AWS KMS), Amazon CloudWatch, Amazon EventBridge, and AWS Identity and Access Management (IAM). The inclusion of these services is fundamental to ensure the necessary levels of data governance and security, besides providing the fundamentals of an extendable and future-ready platform.
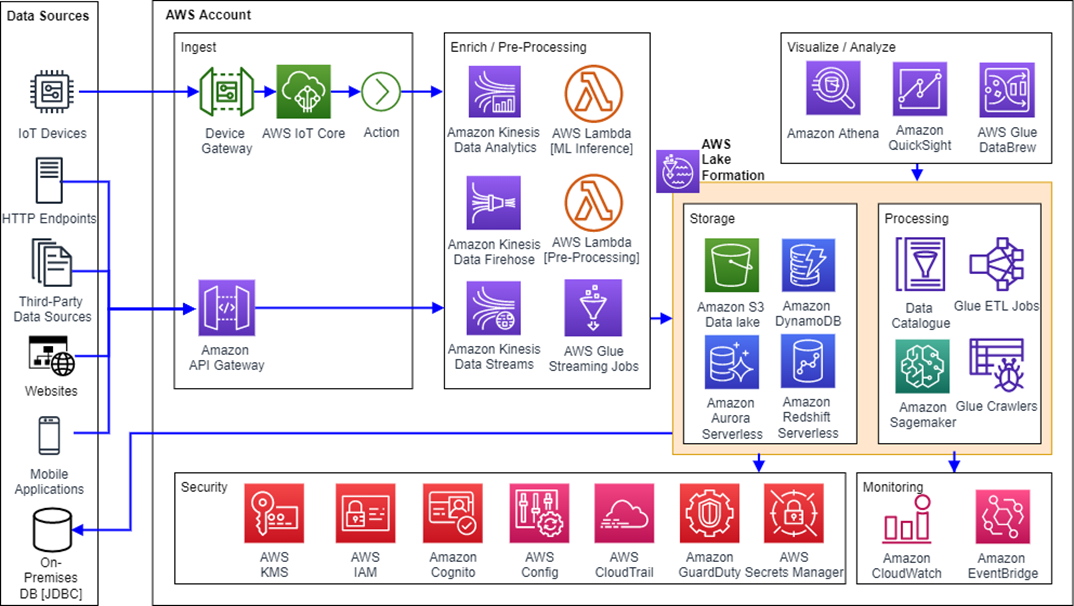
Figure 2 — Big data platform architecture.
CI/CD Automation
As a best practice, Storm Reply follows a DevOps approach for the development, maintainability, and extension of the code in the platform. CI/CD pipelines are included for fast update-and-deploy procedures of the whole architecture incurring independent scalability, reliability, and performance thanks to the modular structure of both the repositories and the deployment pipelines.
The modular approach ensures that individual steps of a data pipeline are treated as independent services developed, maintained, and extended, following a microservices deployment strategy.
The AWS Cloud Development Kit (AWS CDK), an open-source software development framework, is used for the purpose of repeatability and platform services consistency across different AWS regions, accounts, and environments. AWS CDK constructs help developers separate the definition of pieces of architecture, easing the reuse of Infrastructure as Code (IaC).
As shown in Figure 3, different layers are mapped to different AWS CDK stacks within a single repository. The repository contains an AWS CDK application composed of stacks. The modularity of the stacks is designed for the reusability of the code by having a division of stages (or layers) in different folders. The image shows how architecture components are allocated in folders, each containing CDK pieces.

Figure 3 — Stacks in AWS CodeCommit repository.
For the purpose of CI/CD, AWS CodePipeline was integrated in the solution. As displayed in Figure 4, the pipelines help automate the release of the platform’s new features, updates, or simple maintenance. Fully managed continuous delivery services from AWS, including AWS CodeCommit repositories, build and testing process through AWS CodeBuild, and the actual deployments through AWS CodeDeploy are the founding elements of the pipeline.

Figure 4 — AWS CodePipeline.
Different pipelines serve the purpose of deploying different services in the given stage (or layer). Good examples could be a Java application (for example, Apache Flink) for the Amazon Kinesis Data Analytics application; the build, test, and deploy of machine learning models in AWS Lambda functions or Amazon Elastic Container Services (Amazon ECS); or the development of AWS Glue ETL (extract, transform, and load) jobs.
This DevOps agile approach makes the fundamentals of a good and sound cloud, data, and software development strategy. Storm Reply uses this approach as a best practice for similar projects, ensuring the necessary levels of governance, security, and agility required by its customers engaged in time-critical initiatives (for example, involving time-to-market constraints).
360 Degrees Data Collection
Building a big data and analytics platform requires collecting data from multiple sources and moving it to a centralized source—a data lake. To unlock value from customer data, Storm Reply leverages on Amazon S3 as the core service for a dedicated data storage strategy in which structured and unstructured data is maintained—regardless of the scale.
Data sources include IoT devices, websites (for example, web scraping data), mobile applications, data pulled through JDBC connectors, data pushed to Amazon API Gateway, or other internal or third-party IT/business systems.
Depending on the format, frequency, and source of the data, different data pipelines will use different AWS services that can be differentiated into real-time data streams, batch processing data streams, or event-driven data streams.
Real-time data pipelines leverage real-time and serverless services from AWS such as, AWS IoT Core, Amazon Kinesis Data Analytics, AWS Glue streaming jobs, Amazon Redshift Serverless, and Amazon Aurora Serverless, to name a few. Figure 5 depicts a high-level architecture of a serverless, real-time data pipeline built in AWS.
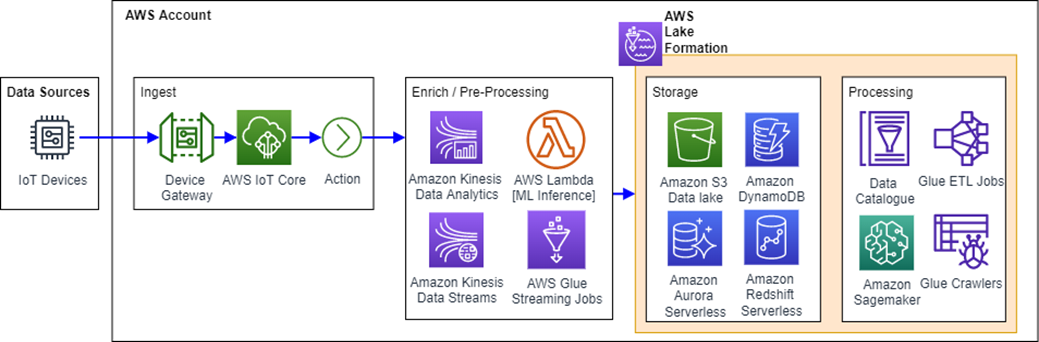
Figure 5 — Real-time data analytics ingestion pipeline.
In general, IoT devices can either have sensing capabilities, actuating capabilities, or both (bi-directional interaction). Depending on the industry, sensors may be used for sensing or measuring temperature, pressure, light, vibration, and voltage/current. On the other hand, actuators are intended to physically react to specific events or local or remote commands. For example, actuators might interact with valves, DC/DC switching regulators, and activate thermal actuators.
As a result, leveraging the available variety of data, ML models are designed, trained, and developed through different iterations. Data is first given the necessary structure; cleaned up for unnecessary rows, NaN values, and redundant columns; labeled to facilitate correlation; and enriched with different sources for features extension, with the purpose of increasing the accuracy and performance of the ML model itself. Amazon SageMaker Studio is the preferred service for the purpose.

Figure 6 — Batch data processing pipeline.
Figure 6 shows the architecture of a batch data processing pipeline developed in AWS. External information from other data sources can also be aggregated using AWS Glue ETL jobs with a push strategy through Amazon API Gateway and Amazon S3, or with a pull strategy through JDBC connectors configured in AWS Lake Formation.
One important thing to consider with data pipelines is that not all stages or steps of a pipeline need to be always included. For instance, the enrich/pre-processing or processing stages could, or could not, be part of a pipeline.
Getting Sense of Data
Data lakes are better developed using AWS Lake Formation to set up a centralized and secure repository containing all data from different data sources. The service enables several features to build, develop, and maintain a data lake efficiently. It allows importing data from external data sources and from databases that already exist in AWS (Figure 6). Data can be catalogued and labeled inside AWS Lake Formation to create a searchable catalog, enabling users to discover available data sets.
Another important aspect to consider is security management. Lake Formation provides the capability of enforcing encryption using AWS Key Management Service (AWS KMS) to automatically secure data at-rest and in-transit. Besides encrypting data, the service also offers the capability to manage access controls. Security policies can be defined to restrict access, while access itself can be tracked using logs with AWS CloudTrail.
This facilitates auditing and compliance efforts with centrally defined policies. ACID (atomic, consistent, isolated, and durable) transactions can also be enforced to permit multiple users and systems to insert data reliably and consistently across multiple tables. The transactions for the governed tables automatically manage conflicts and errors and ensures consistent views for all users. Data can be queried from Amazon S3, Amazon Redshift, Amazon Athena, and AWS Glue.
Centralized, reliable, and feature-enriched data can allow companies with the identification of patterns, correlations, issues, and causations by profiling final users, systems, and business processes. This strategy does not only allow the generation of new business streams, but could also benefit the improvement of existing processes in organizations.
Identifying New Business Models
Storm Reply’s phased approach to identifying new business models starts with an assessment of the customer’s readiness for the adoption of an IoT solution. Engagements proceed with the identification of a business case, and include a Proof of Concept (PoC). PoC’s are conducted following a discovery-driven planning approach designed to generate business value while containing timings and investments to what is functional to making decisions for the overall project.
After the first positive results are obtained, the solution is extended following a modularized and scalable approach with the help of the Storm’s IoT Innovator Framework (Figure 7).

Figure 7 — Storm Reply’s IoT phased approach.
Among the different activities in an IoT project, special attention is given to the availability and reliability of data. An analysis of the required governance and security is carried out considering the speed in which the different teams need to operate.
Data is structured, enriched, cleaned, and modeled in a secure manner, so that useful and trustful insights are retrieved. AWS Glue plays a key role by as it maintains the data catalog for all sources and processed data.
In terms of data predictive analytics, Amazon SageMaker is used as a lab to allow data scientists to build, develop, train, and improve machine learning models. The lab has access to the data catalog and the Amazon S3 data lake in which structured, unstructured, and processed data is stored.
Another important factor is that of the agile methodology adoption. The “fail fast, learn fast” approach enables self-organized and cross-functional teams to try things quickly—minimizing efforts, time, and investments. This discovery-driven planning is preferred, as it facilitates the validation of initial assumptions and the identification and testing of new ideas as part of the process.
The combination of agile methodologies, availability and reliability of data, and the direct interaction with the business makes it possible to identify new business models in which other participants of the value chain could capture both financial and non-financial value. Gaining consumption awareness and identifying ways in which damages or waste can be prevented are key for customers on their road to an environmentally conscious consumption.
Storm Reply supports these initiatives for sustainability by leveraging the agility, speed, and cost effectiveness of AWS, combined with a good business understanding and industry domain expertise.
Conclusion
As explored in this post, business and sustainable development goals can be achieved by leveraging AWS cloud technologies and engaging the right partners. But availability of data is not enough; companies should focus on the ingestion, processing, and exposure of quality data to get its full potential through—for example—the identification of new business models aiming to disrupt core offerings, open new business streams, or differentiate among competitors.
While this post focuses on the energy and utilities sector, the same technologies, building blocks, strategy, and approach can be applied in other industries aiming to adopt a secure, scalable, and reliable IoT big data platform.
To work with Storm Reply, contact the team.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.
 .
.
Storm Reply – AWS Partner Spotlight
Storm Reply is an AWS Premier Tier Services Partner and AWS Competency Partner that supports businesses in the strategy, design, development, and maintenance of DevOps, big data, IoT (industrial and consumer), and cloud-native AWS solutions focusing on security, costs transparency, and time efficiency.